 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoseph G. Ellis
PatternNet: Visual Pattern Mining with Deep Neural Network
Jun 13, 2018
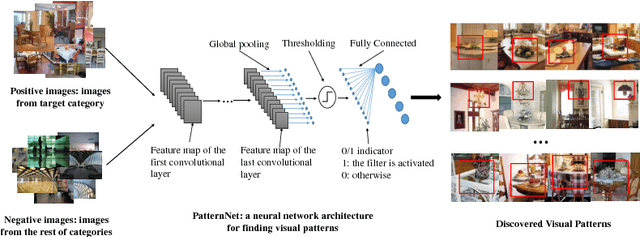

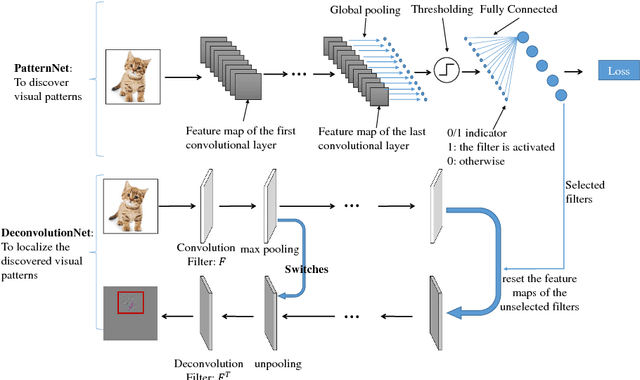
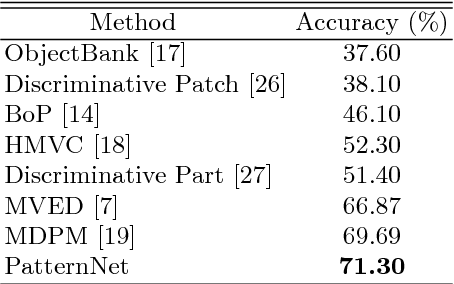
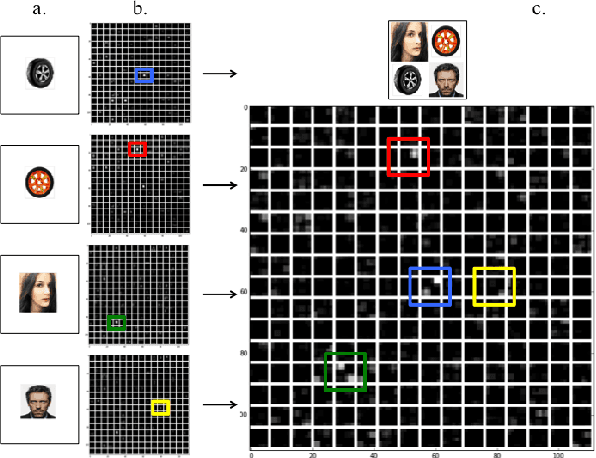
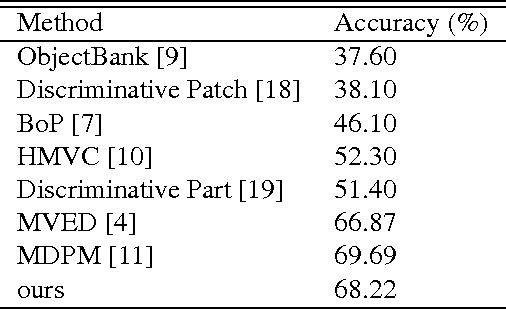
Visual patterns represent the discernible regularity in the visual world. They capture the essential nature of visual objects or scenes. Understanding and modeling visual patterns is a fundamental problem in visual recognition that has wide ranging applications. In this paper, we study the problem of visual pattern mining and propose a novel deep neural network architecture called PatternNet for discovering these patterns that are both discriminative and representative. The proposed PatternNet leverages the filters in the last convolution layer of a convolutional neural network to find locally consistent visual patches, and by combining these filters we can effectively discover unique visual patterns. In addition, PatternNet can discover visual patterns efficiently without performing expensive image patch sampling, and this advantage provides an order of magnitude speedup compared to most other approaches. We evaluate the proposed PatternNet subjectively by showing randomly selected visual patterns which are discovered by our method and quantitatively by performing image classification with the identified visual patterns and comparing our performance with the current state-of-the-art. We also directly evaluate the quality of the discovered visual patterns by leveraging the identified patterns as proposed objects in an image and compare with other relevant methods. Our proposed network and procedure, PatterNet, is able to outperform competing methods for the tasks described.
Event Specific Multimodal Pattern Mining with Image-Caption Pairs
Jan 05, 2016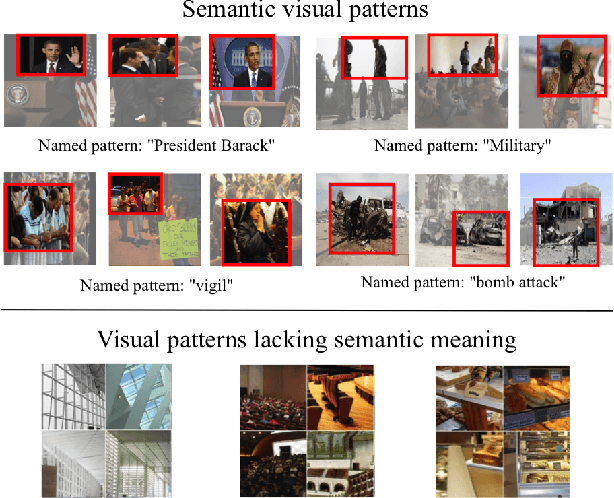

In this paper we describe a novel framework and algorithms for discovering image patch patterns from a large corpus of weakly supervised image-caption pairs generated from news events. Current pattern mining techniques attempt to find patterns that are representative and discriminative, we stipulate that our discovered patterns must also be recognizable by humans and preferably with meaningful names. We propose a new multimodal pattern mining approach that leverages the descriptive captions often accompanying news images to learn semantically meaningful image patch patterns. The mutltimodal patterns are then named using words mined from the associated image captions for each pattern. A novel evaluation framework is provided that demonstrates our patterns are 26.2% more semantically meaningful than those discovered by the state of the art vision only pipeline, and that we can provide tags for the discovered images patches with 54.5% accuracy with no direct supervision. Our methods also discover named patterns beyond those covered by the existing image datasets like ImageNet. To the best of our knowledge this is the first algorithm developed to automatically mine image patch patterns that have strong semantic meaning specific to high-level news events, and then evaluate these patterns based on that criteria.
Objective Variables for Probabilistic Revenue Maximization in Second-Price Auctions with Reserve
Jun 24, 2015


Many online companies sell advertisement space in second-price auctions with reserve. In this paper, we develop a probabilistic method to learn a profitable strategy to set the reserve price. We use historical auction data with features to fit a predictor of the best reserve price. This problem is delicate - the structure of the auction is such that a reserve price set too high is much worse than a reserve price set too low. To address this we develop objective variables, a new framework for combining probabilistic modeling with optimal decision-making. Objective variables are "hallucinated observations" that transform the revenue maximization task into a regularized maximum likelihood estimation problem, which we solve with an EM algorithm. This framework enables a variety of prediction mechanisms to set the reserve price. As examples, we study objective variable methods with regression, kernelized regression, and neural networks on simulated and real data. Our methods outperform previous approaches both in terms of scalability and profit.