 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuan Del Aguila Ferrandis
Learning Goal-Directed Object Pushing in Cluttered Scenes with Location-Based Attention
Mar 26, 2024




Non-prehensile planar pushing is a challenging task due to its underactuated nature with hybrid-dynamics, where a robot needs to reason about an object's long-term behaviour and contact-switching, while being robust to contact uncertainty. The presence of clutter in the environment further complicates this task, introducing the need to include more sophisticated spatial analysis to avoid collisions. Building upon prior work on reinforcement learning (RL) with multimodal categorical exploration for planar pushing, in this paper we incorporate location-based attention to enable robust navigation through clutter. Unlike previous RL literature addressing this obstacle avoidance pushing task, our framework requires no predefined global paths and considers the target orientation of the manipulated object. Our results demonstrate that the learned policies successfully navigate through a wide range of complex obstacle configurations, including dynamic obstacles, with smooth motions, achieving the desired target object pose. We also validate the transferability of the learned policies to robotic hardware using the KUKA iiwa robot arm.
Nonprehensile Planar Manipulation through Reinforcement Learning with Multimodal Categorical Exploration
Aug 04, 2023
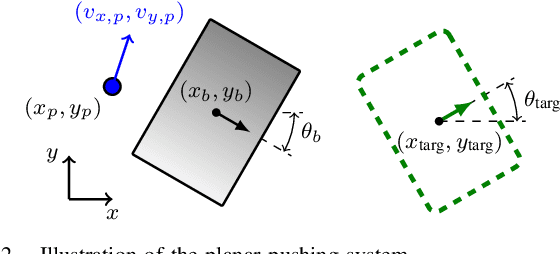
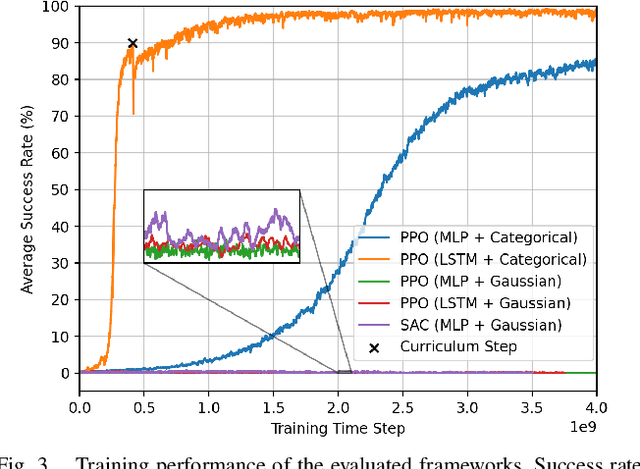
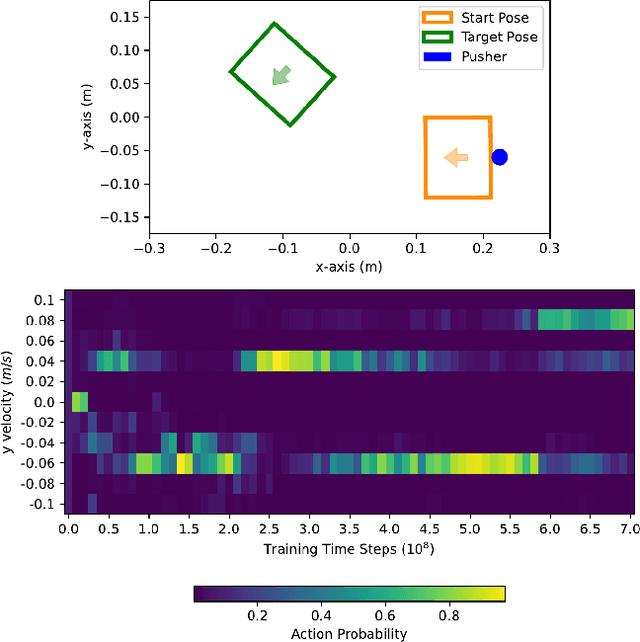
Developing robot controllers capable of achieving dexterous nonprehensile manipulation, such as pushing an object on a table, is challenging. The underactuated and hybrid-dynamics nature of the problem, further complicated by the uncertainty resulting from the frictional interactions, requires sophisticated control behaviors. Reinforcement Learning (RL) is a powerful framework for developing such robot controllers. However, previous RL literature addressing the nonprehensile pushing task achieves low accuracy, non-smooth trajectories, and only simple motions, i.e. without rotation of the manipulated object. We conjecture that previously used unimodal exploration strategies fail to capture the inherent hybrid-dynamics of the task, arising from the different possible contact interaction modes between the robot and the object, such as sticking, sliding, and separation. In this work, we propose a multimodal exploration approach through categorical distributions, which enables us to train planar pushing RL policies for arbitrary starting and target object poses, i.e. positions and orientations, and with improved accuracy. We show that the learned policies are robust to external disturbances and observation noise, and scale to tasks with multiple pushers. Furthermore, we validate the transferability of the learned policies, trained entirely in simulation, to a physical robot hardware using the KUKA iiwa robot arm. See our supplemental video: https://youtu.be/vTdva1mgrk4.