 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuho Kannala
Dense Road Surface Grip Map Prediction from Multimodal Image Data
Apr 26, 2024
Slippery road weather conditions are prevalent in many regions and cause a regular risk for traffic. Still, there has been less research on how autonomous vehicles could detect slippery driving conditions on the road to drive safely. In this work, we propose a method to predict a dense grip map from the area in front of the car, based on postprocessed multimodal sensor data. We trained a convolutional neural network to predict pixelwise grip values from fused RGB camera, thermal camera, and LiDAR reflectance images, based on weakly supervised ground truth from an optical road weather sensor. The experiments show that it is possible to predict dense grip values with good accuracy from the used data modalities as the produced grip map follows both ground truth measurements and local weather conditions, such as snowy areas on the road. The model using only the RGB camera or LiDAR reflectance modality provided good baseline results for grip prediction accuracy while using models fusing the RGB camera, thermal camera, and LiDAR modalities improved the grip predictions significantly.
DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
Mar 26, 2024
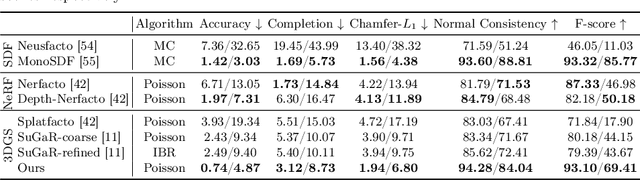


3D Gaussian splatting, a novel differentiable rendering technique, has achieved state-of-the-art novel view synthesis results with high rendering speeds and relatively low training times. However, its performance on scenes commonly seen in indoor datasets is poor due to the lack of geometric constraints during optimization. We extend 3D Gaussian splatting with depth and normal cues to tackle challenging indoor datasets and showcase techniques for efficient mesh extraction, an important downstream application. Specifically, we regularize the optimization procedure with depth information, enforce local smoothness of nearby Gaussians, and use the geometry of the 3D Gaussians supervised by normal cues to achieve better alignment with the true scene geometry. We improve depth estimation and novel view synthesis results over baselines and show how this simple yet effective regularization technique can be used to directly extract meshes from the Gaussian representation yielding more physically accurate reconstructions on indoor scenes. Our code will be released in https://github.com/maturk/dn-splatter.
Gaussian Splatting on the Move: Blur and Rolling Shutter Compensation for Natural Camera Motion
Mar 20, 2024
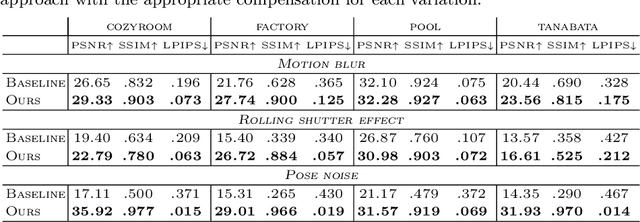


High-quality scene reconstruction and novel view synthesis based on Gaussian Splatting (3DGS) typically require steady, high-quality photographs, often impractical to capture with handheld cameras. We present a method that adapts to camera motion and allows high-quality scene reconstruction with handheld video data suffering from motion blur and rolling shutter distortion. Our approach is based on detailed modelling of the physical image formation process and utilizes velocities estimated using visual-inertial odometry (VIO). Camera poses are considered non-static during the exposure time of a single image frame and camera poses are further optimized in the reconstruction process. We formulate a differentiable rendering pipeline that leverages screen space approximation to efficiently incorporate rolling-shutter and motion blur effects into the 3DGS framework. Our results with both synthetic and real data demonstrate superior performance in mitigating camera motion over existing methods, thereby advancing 3DGS in naturalistic settings.
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
Nov 05, 2023Metaverse technologies demand accurate, real-time, and immersive modeling on consumer-grade hardware for both non-human perception (e.g., drone/robot/autonomous car navigation) and immersive technologies like AR/VR, requiring both structural accuracy and photorealism. However, there exists a knowledge gap in how to apply geometric reconstruction and photorealism modeling (novel view synthesis) in a unified framework. To address this gap and promote the development of robust and immersive modeling and rendering with consumer-grade devices, first, we propose a real-world Multi-Sensor Hybrid Room Dataset (MuSHRoom). Our dataset presents exciting challenges and requires state-of-the-art methods to be cost-effective, robust to noisy data and devices, and can jointly learn 3D reconstruction and novel view synthesis, instead of treating them as separate tasks, making them ideal for real-world applications. Second, we benchmark several famous pipelines on our dataset for joint 3D mesh reconstruction and novel view synthesis. Finally, in order to further improve the overall performance, we propose a new method that achieves a good trade-off between the two tasks. Our dataset and benchmark show great potential in promoting the improvements for fusing 3D reconstruction and high-quality rendering in a robust and computationally efficient end-to-end fashion.
Optimistic Multi-Agent Policy Gradient for Cooperative Tasks
Nov 03, 2023\textit{Relative overgeneralization} (RO) occurs in cooperative multi-agent learning tasks when agents converge towards a suboptimal joint policy due to overfitting to suboptimal behavior of other agents. In early work, optimism has been shown to mitigate the \textit{RO} problem when using tabular Q-learning. However, with function approximation optimism can amplify overestimation and thus fail on complex tasks. On the other hand, recent deep multi-agent policy gradient (MAPG) methods have succeeded in many complex tasks but may fail with severe \textit{RO}. We propose a general, yet simple, framework to enable optimistic updates in MAPG methods and alleviate the RO problem. Specifically, we employ a \textit{Leaky ReLU} function where a single hyperparameter selects the degree of optimism to reshape the advantages when updating the policy. Intuitively, our method remains optimistic toward individual actions with lower returns which are potentially caused by other agents' sub-optimal behavior during learning. The optimism prevents the individual agents from quickly converging to a local optimum. We also provide a formal analysis from an operator view to understand the proposed advantage transformation. In extensive evaluations on diverse sets of tasks, including illustrative matrix games, complex \textit{Multi-agent MuJoCo} and \textit{Overcooked} benchmarks, the proposed method\footnote{Code can be found at \url{https://github.com/wenshuaizhao/optimappo}.} outperforms strong baselines on 13 out of 19 tested tasks and matches the performance on the rest.
Projected Stochastic Gradient Descent with Quantum Annealed Binary Gradients
Oct 23, 2023We present, QP-SBGD, a novel layer-wise stochastic optimiser tailored towards training neural networks with binary weights, known as binary neural networks (BNNs), on quantum hardware. BNNs reduce the computational requirements and energy consumption of deep learning models with minimal loss in accuracy. However, training them in practice remains to be an open challenge. Most known BNN-optimisers either rely on projected updates or binarise weights post-training. Instead, QP-SBGD approximately maps the gradient onto binary variables, by solving a quadratic constrained binary optimisation. Under practically reasonable assumptions, we show that this update rule converges with a rate of $\mathcal{O}(1 / \sqrt{T})$. Moreover, we show how the $\mathcal{NP}$-hard projection can be effectively executed on an adiabatic quantum annealer, harnessing recent advancements in quantum computation. We also introduce a projected version of this update rule and prove that if a fixed point exists in the binary variable space, the modified updates will converge to it. Last but not least, our algorithm is implemented layer-wise, making it suitable to train larger networks on resource-limited quantum hardware. Through extensive evaluations, we show that QP-SBGD outperforms or is on par with competitive and well-established baselines such as BinaryConnect, signSGD and ProxQuant when optimising the Rosenbrock function, training BNNs as well as binary graph neural networks.
DGC-GNN: Descriptor-free Geometric-Color Graph Neural Network for 2D-3D Matching
Jun 21, 2023



Direct matching of 2D keypoints in an input image to a 3D point cloud of the scene without requiring visual descriptors has garnered increased interest due to its lower memory requirements, inherent privacy preservation, and reduced need for expensive 3D model maintenance compared to visual descriptor-based methods. However, existing algorithms often compromise on performance, resulting in a significant deterioration compared to their descriptor-based counterparts. In this paper, we introduce DGC-GNN, a novel algorithm that employs a global-to-local Graph Neural Network (GNN) that progressively exploits geometric and color cues to represent keypoints, thereby improving matching robustness. Our global-to-local procedure encodes both Euclidean and angular relations at a coarse level, forming the geometric embedding to guide the local point matching. We evaluate DGC-GNN on both indoor and outdoor datasets, demonstrating that it not only doubles the accuracy of the state-of-the-art descriptor-free algorithm but, also, substantially narrows the performance gap between descriptor-based and descriptor-free methods. The code and trained models will be made publicly available.
Simplified Temporal Consistency Reinforcement Learning
Jun 15, 2023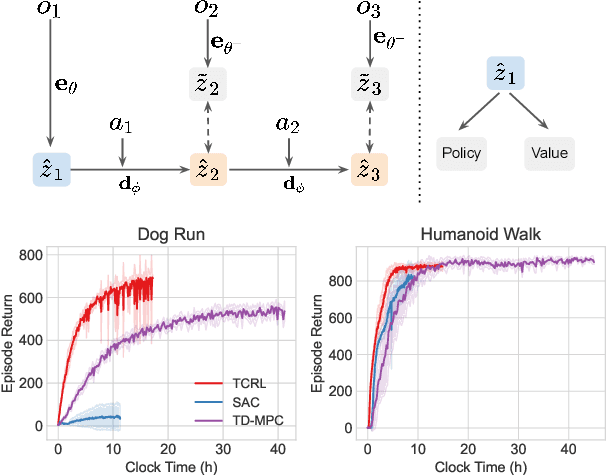

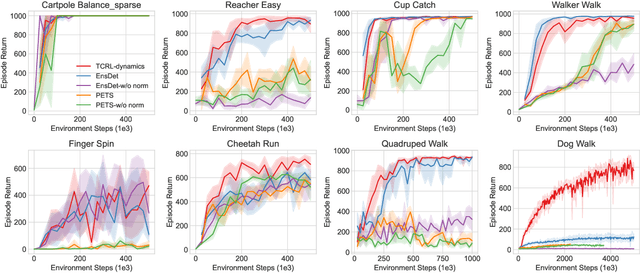
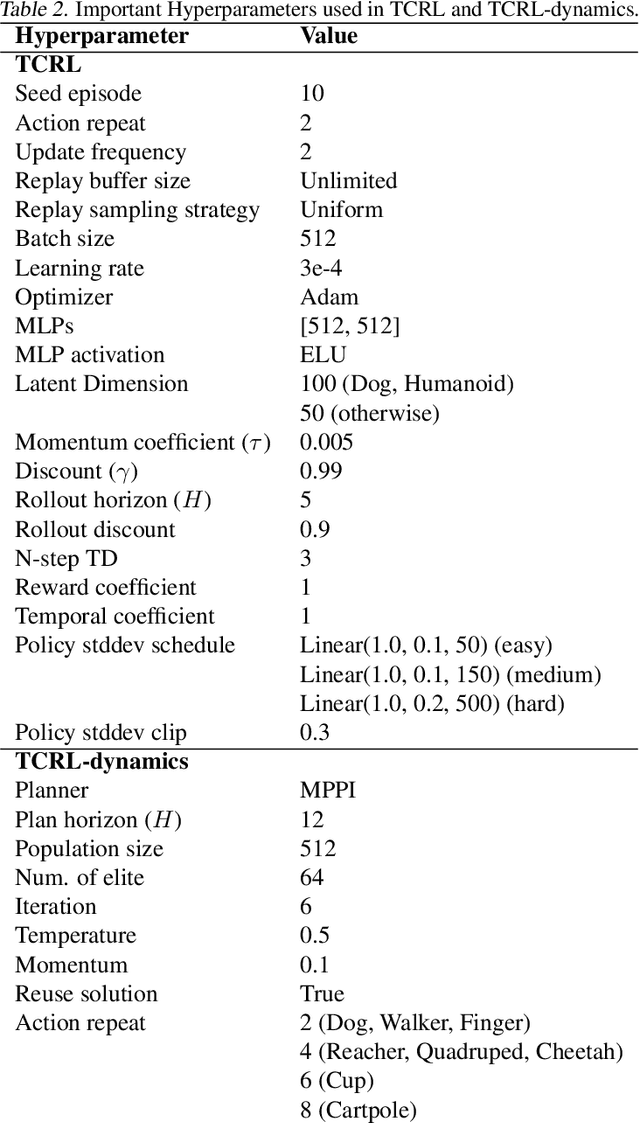
Reinforcement learning is able to solve complex sequential decision-making tasks but is currently limited by sample efficiency and required computation. To improve sample efficiency, recent work focuses on model-based RL which interleaves model learning with planning. Recent methods further utilize policy learning, value estimation, and, self-supervised learning as auxiliary objectives. In this paper we show that, surprisingly, a simple representation learning approach relying only on a latent dynamics model trained by latent temporal consistency is sufficient for high-performance RL. This applies when using pure planning with a dynamics model conditioned on the representation, but, also when utilizing the representation as policy and value function features in model-free RL. In experiments, our approach learns an accurate dynamics model to solve challenging high-dimensional locomotion tasks with online planners while being 4.1 times faster to train compared to ensemble-based methods. With model-free RL without planning, especially on high-dimensional tasks, such as the DeepMind Control Suite Humanoid and Dog tasks, our approach outperforms model-free methods by a large margin and matches model-based methods' sample efficiency while training 2.4 times faster.
HSCNet++: Hierarchical Scene Coordinate Classification and Regression for Visual Localization with Transformer
May 05, 2023



Visual localization is critical to many applications in computer vision and robotics. To address single-image RGB localization, state-of-the-art feature-based methods match local descriptors between a query image and a pre-built 3D model. Recently, deep neural networks have been exploited to regress the mapping between raw pixels and 3D coordinates in the scene, and thus the matching is implicitly performed by the forward pass through the network. However, in a large and ambiguous environment, learning such a regression task directly can be difficult for a single network. In this work, we present a new hierarchical scene coordinate network to predict pixel scene coordinates in a coarse-to-fine manner from a single RGB image. The proposed method, which is an extension of HSCNet, allows us to train compact models which scale robustly to large environments. It sets a new state-of-the-art for single-image localization on the 7-Scenes, 12 Scenes, Cambridge Landmarks datasets, and the combined indoor scenes.
TBPos: Dataset for Large-Scale Precision Visual Localization
Feb 20, 2023



Image based localization is a classical computer vision challenge, with several well-known datasets. Generally, datasets consist of a visual 3D database that captures the modeled scenery, as well as query images whose 3D pose is to be discovered. Usually the query images have been acquired with a camera that differs from the imaging hardware used to collect the 3D database; consequently, it is hard to acquire accurate ground truth poses between query images and the 3D database. As the accuracy of visual localization algorithms constantly improves, precise ground truth becomes increasingly important. This paper proposes TBPos, a novel large-scale visual dataset for image based positioning, which provides query images with fully accurate ground truth poses: both the database images and the query images have been derived from the same laser scanner data. In the experimental part of the paper, the proposed dataset is evaluated by means of an image-based localization pipeline.