 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJulien Cumin
Generative Resident Separation and Multi-label Classification for Multi-person Activity Recognition
Apr 10, 2024
This paper presents two models to address the problem of multi-person activity recognition using ambient sensors in a home. The first model, Seq2Res, uses a sequence generation approach to separate sensor events from different residents. The second model, BiGRU+Q2L, uses a Query2Label multi-label classifier to predict multiple activities simultaneously. Performances of these models are compared to a state-of-the-art model in different experimental scenarios, using a state-of-the-art dataset of two residents in a home instrumented with ambient sensors. These results lead to a discussion on the advantages and drawbacks of resident separation and multi-label classification for multi-person activity recognition.
Accommodating Missing Modalities in Time-Continuous Multimodal Emotion Recognition
Nov 16, 2023Decades of research indicate that emotion recognition is more effective when drawing information from multiple modalities. But what if some modalities are sometimes missing? To address this problem, we propose a novel Transformer-based architecture for recognizing valence and arousal in a time-continuous manner even with missing input modalities. We use a coupling of cross-attention and self-attention mechanisms to emphasize relationships between modalities during time and enhance the learning process on weak salient inputs. Experimental results on the Ulm-TSST dataset show that our model exhibits an improvement of the concordance correlation coefficient evaluation of 37% when predicting arousal values and 30% when predicting valence values, compared to a late-fusion baseline approach.
Emotion Recognition with Pre-Trained Transformers Using Multimodal Signals
Dec 22, 2022



In this paper, we address the problem of multimodal emotion recognition from multiple physiological signals. We demonstrate that a Transformer-based approach is suitable for this task. In addition, we present how such models may be pretrained in a multimodal scenario to improve emotion recognition performances. We evaluate the benefits of using multimodal inputs and pre-training with our approach on a state-ofthe-art dataset.
Transformer-Based Self-Supervised Learning for Emotion Recognition
Apr 08, 2022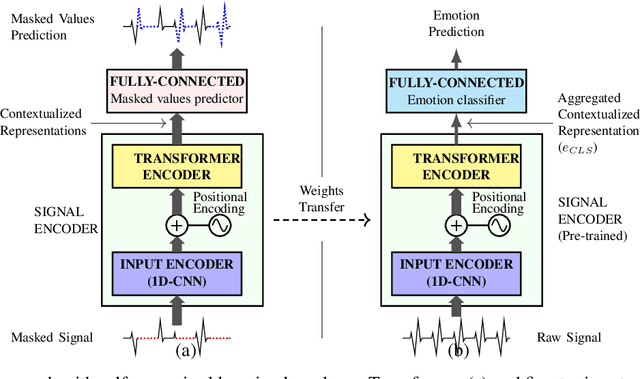

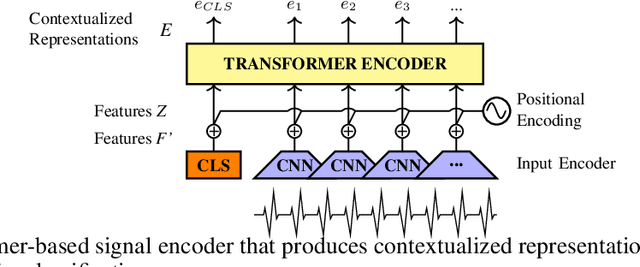

In order to exploit representations of time-series signals, such as physiological signals, it is essential that these representations capture relevant information from the whole signal. In this work, we propose to use a Transformer-based model to process electrocardiograms (ECG) for emotion recognition. Attention mechanisms of the Transformer can be used to build contextualized representations for a signal, giving more importance to relevant parts. These representations may then be processed with a fully-connected network to predict emotions. To overcome the relatively small size of datasets with emotional labels, we employ self-supervised learning. We gathered several ECG datasets with no labels of emotion to pre-train our model, which we then fine-tuned for emotion recognition on the AMIGOS dataset. We show that our approach reaches state-of-the-art performances for emotion recognition using ECG signals on AMIGOS. More generally, our experiments show that transformers and pre-training are promising strategies for emotion recognition with physiological signals.