 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJun Shao
MLDT: Multi-Level Decomposition for Complex Long-Horizon Robotic Task Planning with Open-Source Large Language Model
Apr 02, 2024


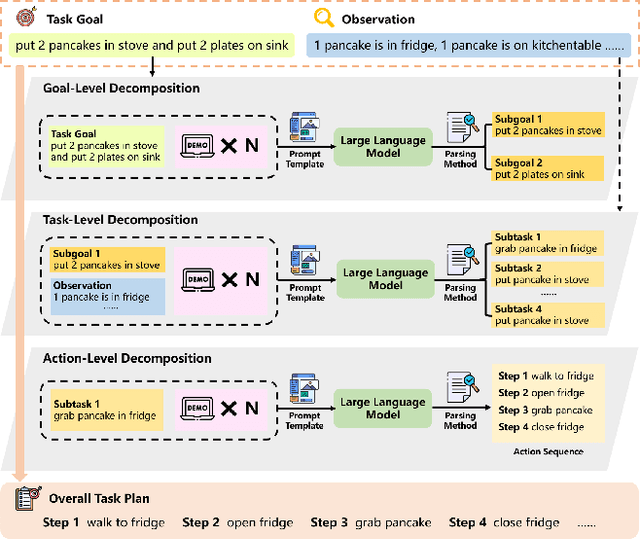

In the realm of data-driven AI technology, the application of open-source large language models (LLMs) in robotic task planning represents a significant milestone. Recent robotic task planning methods based on open-source LLMs typically leverage vast task planning datasets to enhance models' planning abilities. While these methods show promise, they struggle with complex long-horizon tasks, which require comprehending more context and generating longer action sequences. This paper addresses this limitation by proposing MLDT, theMulti-Level Decomposition Task planning method. This method innovatively decomposes tasks at the goal-level, task-level, and action-level to mitigate the challenge of complex long-horizon tasks. In order to enhance open-source LLMs' planning abilities, we introduce a goal-sensitive corpus generation method to create high-quality training data and conduct instruction tuning on the generated corpus. Since the complexity of the existing datasets is not high enough, we construct a more challenging dataset, LongTasks, to specifically evaluate planning ability on complex long-horizon tasks. We evaluate our method using various LLMs on four datasets in VirtualHome. Our results demonstrate a significant performance enhancement in robotic task planning, showcasing MLDT's effectiveness in overcoming the limitations of existing methods based on open-source LLMs as well as its practicality in complex, real-world scenarios.
A Transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics
Jun 01, 2023



During the diagnostic process, clinicians leverage multimodal information, such as chief complaints, medical images, and laboratory-test results. Deep-learning models for aiding diagnosis have yet to meet this requirement. Here we report a Transformer-based representation-learning model as a clinical diagnostic aid that processes multimodal input in a unified manner. Rather than learning modality-specific features, the model uses embedding layers to convert images and unstructured and structured text into visual tokens and text tokens, and bidirectional blocks with intramodal and intermodal attention to learn a holistic representation of radiographs, the unstructured chief complaint and clinical history, structured clinical information such as laboratory-test results and patient demographic information. The unified model outperformed an image-only model and non-unified multimodal diagnosis models in the identification of pulmonary diseases (by 12% and 9%, respectively) and in the prediction of adverse clinical outcomes in patients with COVID-19 (by 29% and 7%, respectively). Leveraging unified multimodal Transformer-based models may help streamline triage of patients and facilitate the clinical decision process.