 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJungwoo Lee
On the Convergence of Continual Learning with Adaptive Methods
Apr 15, 2024
One of the objectives of continual learning is to prevent catastrophic forgetting in learning multiple tasks sequentially, and the existing solutions have been driven by the conceptualization of the plasticity-stability dilemma. However, the convergence of continual learning for each sequential task is less studied so far. In this paper, we provide a convergence analysis of memory-based continual learning with stochastic gradient descent and empirical evidence that training current tasks causes the cumulative degradation of previous tasks. We propose an adaptive method for nonconvex continual learning (NCCL), which adjusts step sizes of both previous and current tasks with the gradients. The proposed method can achieve the same convergence rate as the SGD method when the catastrophic forgetting term which we define in the paper is suppressed at each iteration. Further, we demonstrate that the proposed algorithm improves the performance of continual learning over existing methods for several image classification tasks.
* Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI 2023), see https://proceedings.mlr.press/v216/han23a.html
SPQR: Controlling Q-ensemble Independence with Spiked Random Model for Reinforcement Learning
Jan 06, 2024Alleviating overestimation bias is a critical challenge for deep reinforcement learning to achieve successful performance on more complex tasks or offline datasets containing out-of-distribution data. In order to overcome overestimation bias, ensemble methods for Q-learning have been investigated to exploit the diversity of multiple Q-functions. Since network initialization has been the predominant approach to promote diversity in Q-functions, heuristically designed diversity injection methods have been studied in the literature. However, previous studies have not attempted to approach guaranteed independence over an ensemble from a theoretical perspective. By introducing a novel regularization loss for Q-ensemble independence based on random matrix theory, we propose spiked Wishart Q-ensemble independence regularization (SPQR) for reinforcement learning. Specifically, we modify the intractable hypothesis testing criterion for the Q-ensemble independence into a tractable KL divergence between the spectral distribution of the Q-ensemble and the target Wigner's semicircle distribution. We implement SPQR in several online and offline ensemble Q-learning algorithms. In the experiments, SPQR outperforms the baseline algorithms in both online and offline RL benchmarks.
Toward Reinforcement Learning-based Rectilinear Macro Placement Under Human Constraints
Nov 03, 2023Macro placement is a critical phase in chip design, which becomes more intricate when involving general rectilinear macros and layout areas. Furthermore, macro placement that incorporates human-like constraints, such as design hierarchy and peripheral bias, has the potential to significantly reduce the amount of additional manual labor required from designers. This study proposes a methodology that leverages an approach suggested by Google's Circuit Training (G-CT) to provide a learning-based macro placer that not only supports placing rectilinear cases, but also adheres to crucial human-like design principles. Our experimental results demonstrate the effectiveness of our framework in achieving power-performance-area (PPA) metrics and in obtaining placements of high quality, comparable to those produced with human intervention. Additionally, our methodology shows potential as a generalized model to address diverse macro shapes and layout areas.
Pitfall of Optimism: Distributional Reinforcement Learning by Randomizing Risk Criterion
Oct 27, 2023Distributional reinforcement learning algorithms have attempted to utilize estimated uncertainty for exploration, such as optimism in the face of uncertainty. However, using the estimated variance for optimistic exploration may cause biased data collection and hinder convergence or performance. In this paper, we present a novel distributional reinforcement learning algorithm that selects actions by randomizing risk criterion to avoid one-sided tendency on risk. We provide a perturbed distributional Bellman optimality operator by distorting the risk measure and prove the convergence and optimality of the proposed method with the weaker contraction property. Our theoretical results support that the proposed method does not fall into biased exploration and is guaranteed to converge to an optimal return. Finally, we empirically show that our method outperforms other existing distribution-based algorithms in various environments including Atari 55 games.
Domain-Aware Fine-Tuning: Enhancing Neural Network Adaptability
Aug 15, 2023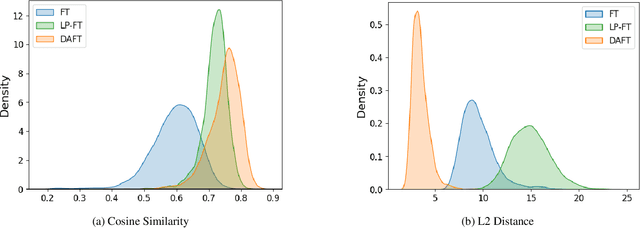

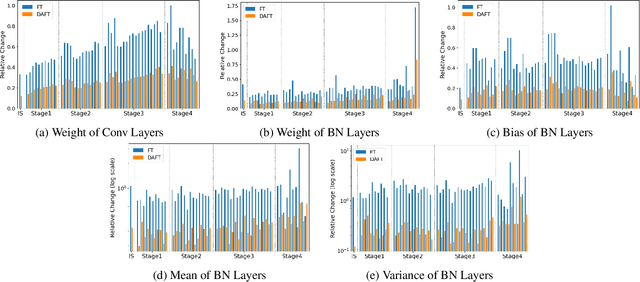
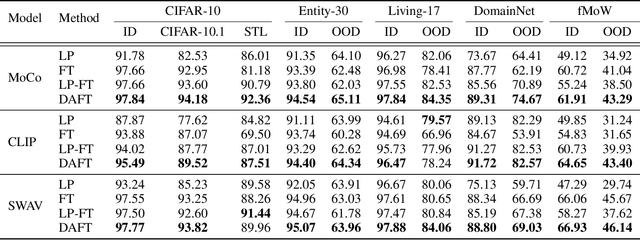
Fine-tuning pre-trained neural network models has become a widely adopted approach across various domains. However, it can lead to the distortion of pre-trained feature extractors that already possess strong generalization capabilities. Mitigating feature distortion during adaptation to new target domains is crucial. Recent studies have shown promising results in handling feature distortion by aligning the head layer on in-distribution datasets before performing fine-tuning. Nonetheless, a significant limitation arises from the treatment of batch normalization layers during fine-tuning, leading to suboptimal performance. In this paper, we propose Domain-Aware Fine-Tuning (DAFT), a novel approach that incorporates batch normalization conversion and the integration of linear probing and fine-tuning. Our batch normalization conversion method effectively mitigates feature distortion by reducing modifications to the neural network during fine-tuning. Additionally, we introduce the integration of linear probing and fine-tuning to optimize the head layer with gradual adaptation of the feature extractor. By leveraging batch normalization layers and integrating linear probing and fine-tuning, our DAFT significantly mitigates feature distortion and achieves improved model performance on both in-distribution and out-of-distribution datasets. Extensive experiments demonstrate that our method outperforms other baseline methods, demonstrating its effectiveness in not only improving performance but also mitigating feature distortion.
Learning to Learn Unlearned Feature for Brain Tumor Segmentation
May 13, 2023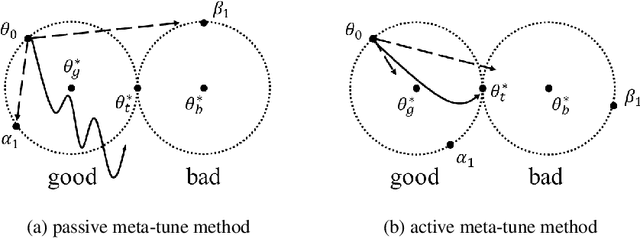

We propose a fine-tuning algorithm for brain tumor segmentation that needs only a few data samples and helps networks not to forget the original tasks. Our approach is based on active learning and meta-learning. One of the difficulties in medical image segmentation is the lack of datasets with proper annotations, because it requires doctors to tag reliable annotation and there are many variants of a disease, such as glioma and brain metastasis, which are the different types of brain tumor and have different structural features in MR images. Therefore, it is impossible to produce the large-scale medical image datasets for all types of diseases. In this paper, we show a transfer learning method from high grade glioma to brain metastasis, and demonstrate that the proposed algorithm achieves balanced parameters for both glioma and brain metastasis domains within a few steps.
Bridging the Gap between Model Explanations in Partially Annotated Multi-label Classification
Apr 04, 2023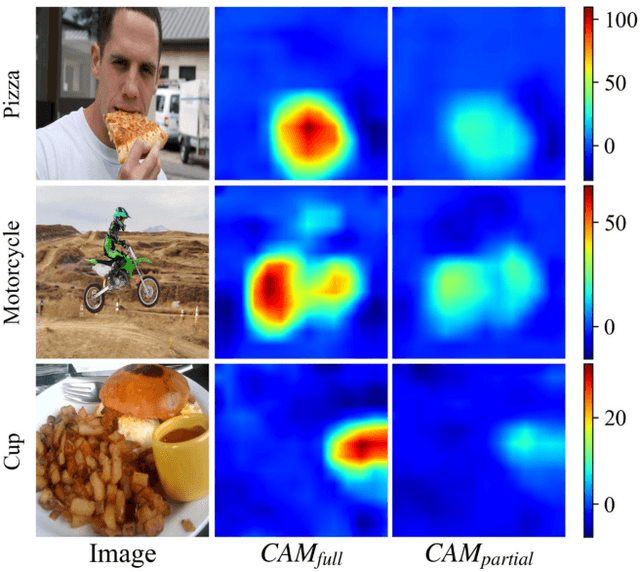
Due to the expensive costs of collecting labels in multi-label classification datasets, partially annotated multi-label classification has become an emerging field in computer vision. One baseline approach to this task is to assume unobserved labels as negative labels, but this assumption induces label noise as a form of false negative. To understand the negative impact caused by false negative labels, we study how these labels affect the model's explanation. We observe that the explanation of two models, trained with full and partial labels each, highlights similar regions but with different scaling, where the latter tends to have lower attribution scores. Based on these findings, we propose to boost the attribution scores of the model trained with partial labels to make its explanation resemble that of the model trained with full labels. Even with the conceptually simple approach, the multi-label classification performance improves by a large margin in three different datasets on a single positive label setting and one on a large-scale partial label setting. Code is available at https://github.com/youngwk/BridgeGapExplanationPAMC.
Large Loss Matters in Weakly Supervised Multi-Label Classification
Jun 08, 2022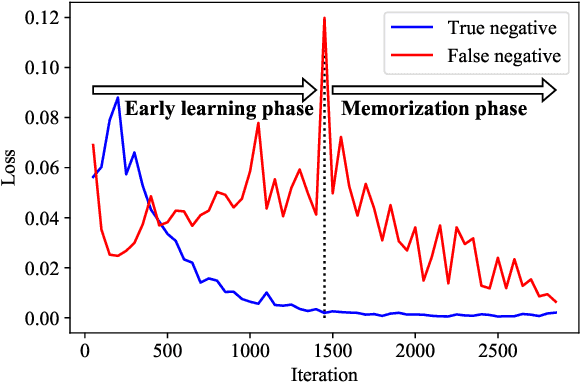

Weakly supervised multi-label classification (WSML) task, which is to learn a multi-label classification using partially observed labels per image, is becoming increasingly important due to its huge annotation cost. In this work, we first regard unobserved labels as negative labels, casting the WSML task into noisy multi-label classification. From this point of view, we empirically observe that memorization effect, which was first discovered in a noisy multi-class setting, also occurs in a multi-label setting. That is, the model first learns the representation of clean labels, and then starts memorizing noisy labels. Based on this finding, we propose novel methods for WSML which reject or correct the large loss samples to prevent model from memorizing the noisy label. Without heavy and complex components, our proposed methods outperform previous state-of-the-art WSML methods on several partial label settings including Pascal VOC 2012, MS COCO, NUSWIDE, CUB, and OpenImages V3 datasets. Various analysis also show that our methodology actually works well, validating that treating large loss properly matters in a weakly supervised multi-label classification. Our code is available at https://github.com/snucml/LargeLossMatters.