 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunhyeok Lee
LatentSwap: An Efficient Latent Code Mapping Framework for Face Swapping
Mar 02, 2024
We propose LatentSwap, a simple face swapping framework generating a face swap latent code of a given generator. Utilizing randomly sampled latent codes, our framework is light and does not require datasets besides employing the pre-trained models, with the training procedure also being fast and straightforward. The loss objective consists of only three terms, and can effectively control the face swap results between source and target images. By attaching a pre-trained GAN inversion model independent to the model and using the StyleGAN2 generator, our model produces photorealistic and high-resolution images comparable to other competitive face swap models. We show that our framework is applicable to other generators such as StyleNeRF, paving a way to 3D-aware face swapping and is also compatible with other downstream StyleGAN2 generator tasks. The source code and models can be found at \url{https://github.com/usingcolor/LatentSwap}.
VIFS: An End-to-End Variational Inference for Foley Sound Synthesis
Jun 08, 2023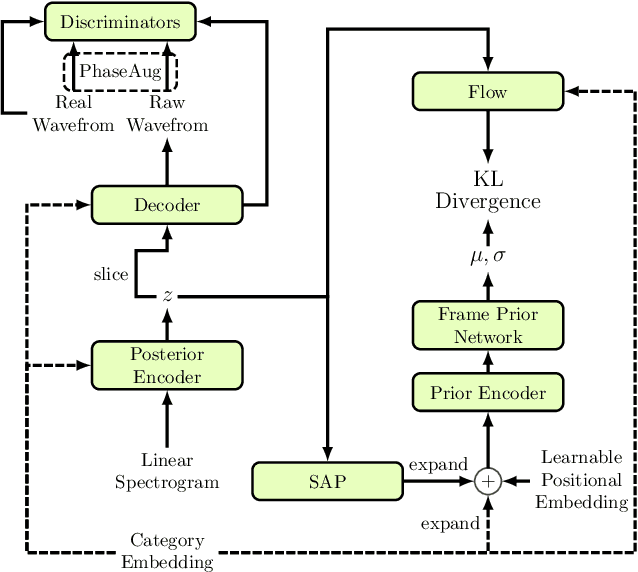
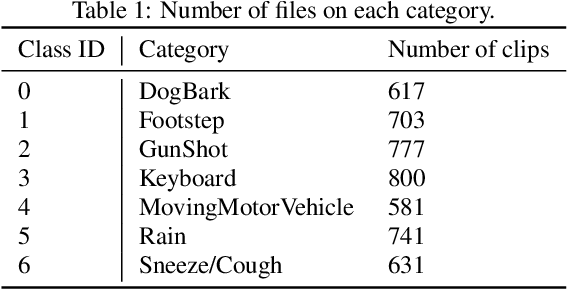
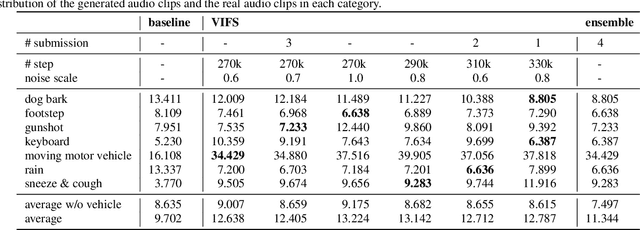
The goal of DCASE 2023 Challenge Task 7 is to generate various sound clips for Foley sound synthesis (FSS) by "category-to-sound" approach. "Category" is expressed by a single index while corresponding "sound" covers diverse and different sound examples. To generate diverse sounds for a given category, we adopt VITS, a text-to-speech (TTS) model with variational inference. In addition, we apply various techniques from speech synthesis including PhaseAug and Avocodo. Different from TTS models which generate short pronunciation from phonemes and speaker identity, the category-to-sound problem requires generating diverse sounds just from a category index. To compensate for the difference while maintaining consistency within each audio clip, we heavily modified the prior encoder to enhance consistency with posterior latent variables. This introduced additional Gaussian on the prior encoder which promotes variance within the category. With these modifications, we propose VIFS, variational inference for end-to-end Foley sound synthesis, which generates diverse high-quality sounds.
PITS: Variational Pitch Inference without Fundamental Frequency for End-to-End Pitch-controllable TTS
Mar 02, 2023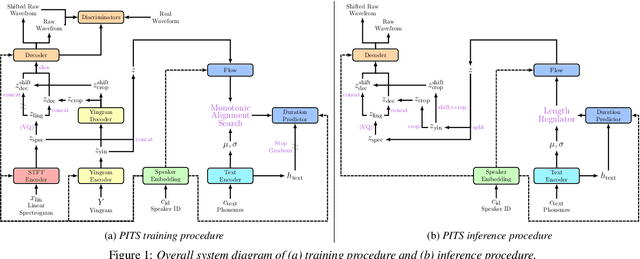
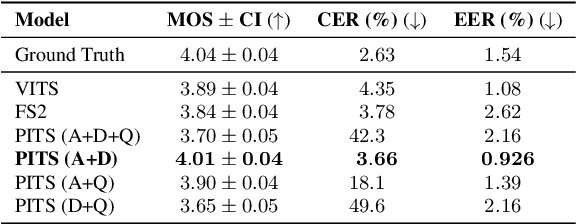
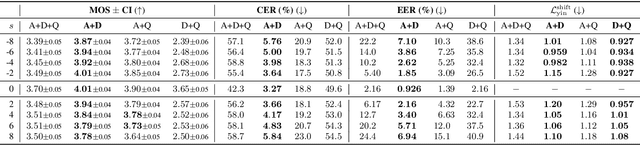
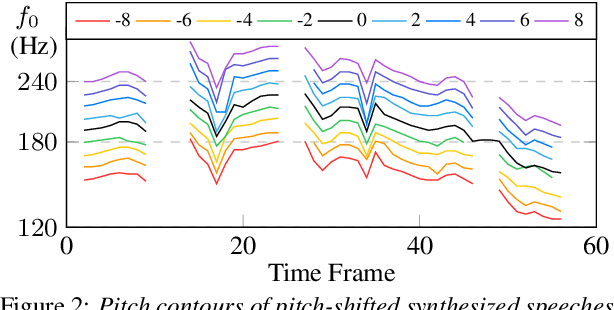
Previous pitch-controllable text-to-speech (TTS) models rely on directly modeling fundamental frequency, leading to low variance in synthesized speech. To address this issue, we propose PITS, an end-to-end pitch-controllable TTS model that utilizes variational inference to model pitch. Based on VITS, PITS incorporates the Yingram encoder, the Yingram decoder, and adversarial training of pitch-shifted synthesis to achieve pitch-controllability. Experiments demonstrate that PITS generates high-quality speech that is indistinguishable from ground truth speech and has high pitch-controllability without quality degradation. Code and audio samples will be available at https://github.com/anonymous-pits/pits.
Designing an offline reinforcement learning objective from scratch
Jan 30, 2023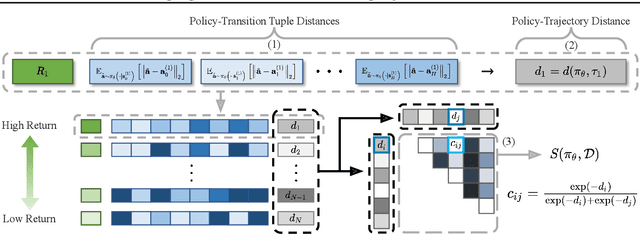
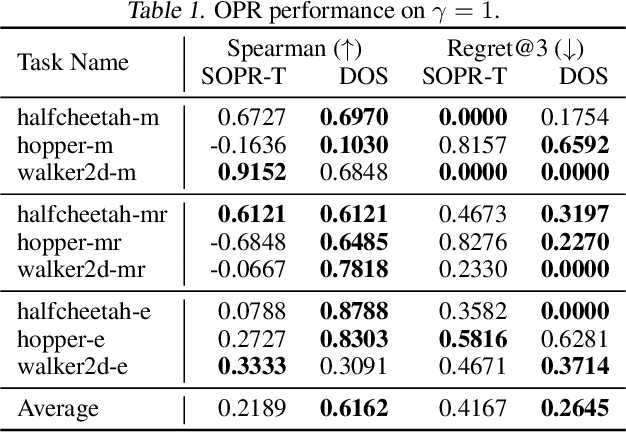
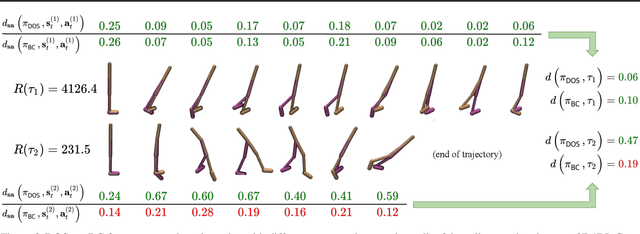
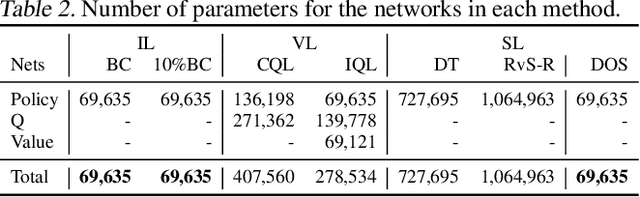
Offline reinforcement learning has developed rapidly over the recent years, but estimating the actual performance of offline policies still remains a challenge. We propose a scoring metric for offline policies that highly correlates with actual policy performance and can be directly used for offline policy optimization in a supervised manner. To achieve this, we leverage the contrastive learning framework to design a scoring metric that gives high scores to policies that imitate the actions yielding relatively high returns while avoiding those yielding relatively low returns. Our experiments show that 1) our scoring metric is able to more accurately rank offline policies and 2) the policies optimized using our metric show high performance on various offline reinforcement learning benchmarks. Notably, our algorithm has a much lower network capacity requirement for the policy network compared to other supervised learning-based methods and also does not need any additional networks such as a Q-network.
PhaseAug: A Differentiable Augmentation for Speech Synthesis to Simulate One-to-Many Mapping
Nov 08, 2022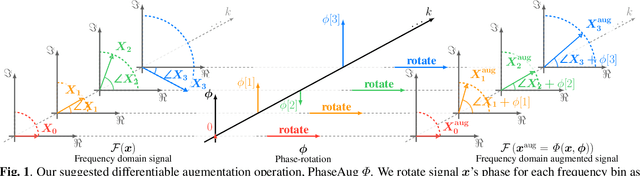
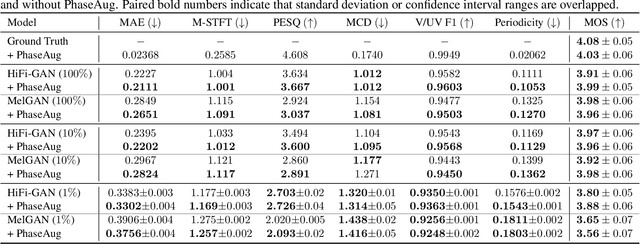
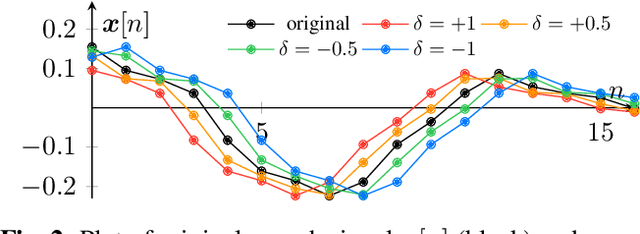
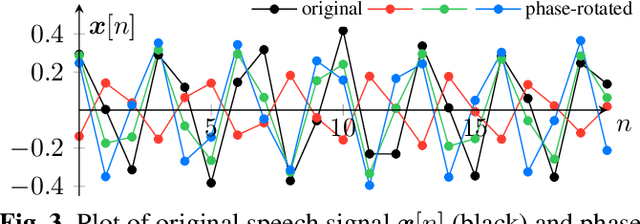
Previous generative adversarial network (GAN)-based neural vocoders are trained to reconstruct the exact ground truth waveform from the paired mel-spectrogram and do not consider the one-to-many relationship of speech synthesis. This conventional training causes overfitting for both the discriminators and the generator, leading to the periodicity artifacts in the generated audio signal. In this work, we present PhaseAug, the first differentiable augmentation for speech synthesis that rotates the phase of each frequency bin to simulate one-to-many mapping. With our proposed method, we outperform baselines without any architecture modification. Code and audio samples will be available at https://github.com/mindslab-ai/phaseaug.
SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech
Jun 24, 2022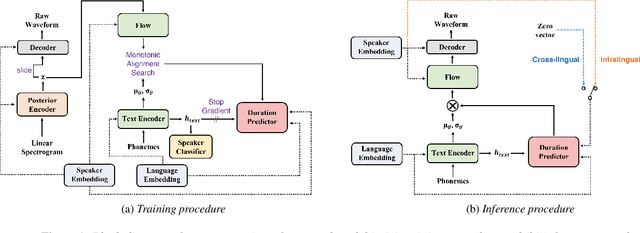
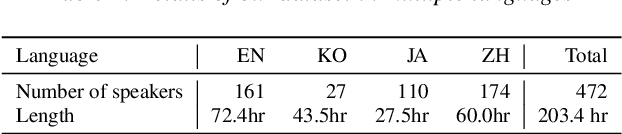

In this paper, we present SANE-TTS, a stable and natural end-to-end multilingual TTS model. By the difficulty of obtaining multilingual corpus for given speaker, training multilingual TTS model with monolingual corpora is unavoidable. We introduce speaker regularization loss that improves speech naturalness during cross-lingual synthesis as well as domain adversarial training, which is applied in other multilingual TTS models. Furthermore, by adding speaker regularization loss, replacing speaker embedding with zero vector in duration predictor stabilizes cross-lingual inference. With this replacement, our model generates speeches with moderate rhythm regardless of source speaker in cross-lingual synthesis. In MOS evaluation, SANE-TTS achieves naturalness score above 3.80 both in cross-lingual and intralingual synthesis, where the ground truth score is 3.99. Also, SANE-TTS maintains speaker similarity close to that of ground truth even in cross-lingual inference. Audio samples are available on our web page.
Query-Efficient and Scalable Black-Box Adversarial Attacks on Discrete Sequential Data via Bayesian Optimization
Jun 17, 2022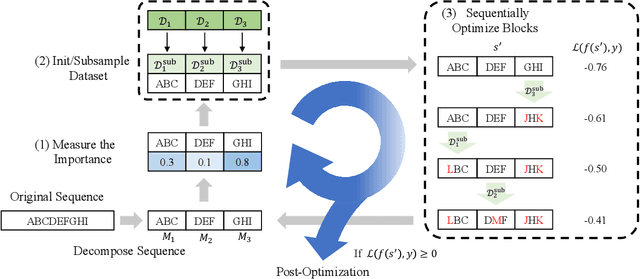

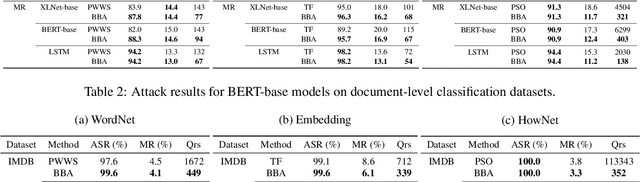
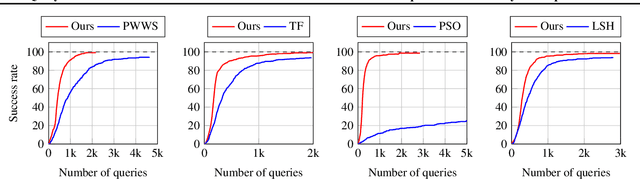
We focus on the problem of adversarial attacks against models on discrete sequential data in the black-box setting where the attacker aims to craft adversarial examples with limited query access to the victim model. Existing black-box attacks, mostly based on greedy algorithms, find adversarial examples using pre-computed key positions to perturb, which severely limits the search space and might result in suboptimal solutions. To this end, we propose a query-efficient black-box attack using Bayesian optimization, which dynamically computes important positions using an automatic relevance determination (ARD) categorical kernel. We introduce block decomposition and history subsampling techniques to improve the scalability of Bayesian optimization when an input sequence becomes long. Moreover, we develop a post-optimization algorithm that finds adversarial examples with smaller perturbation size. Experiments on natural language and protein classification tasks demonstrate that our method consistently achieves higher attack success rate with significant reduction in query count and modification rate compared to the previous state-of-the-art methods.
NU-Wave 2: A General Neural Audio Upsampling Model for Various Sampling Rates
Jun 17, 2022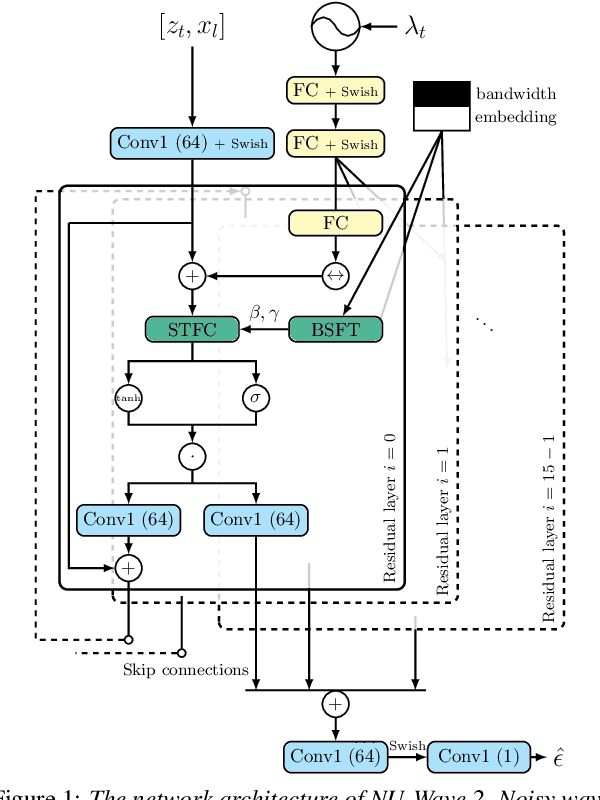
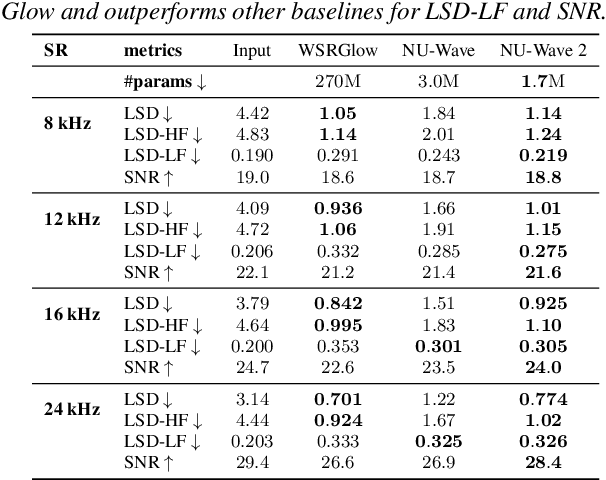
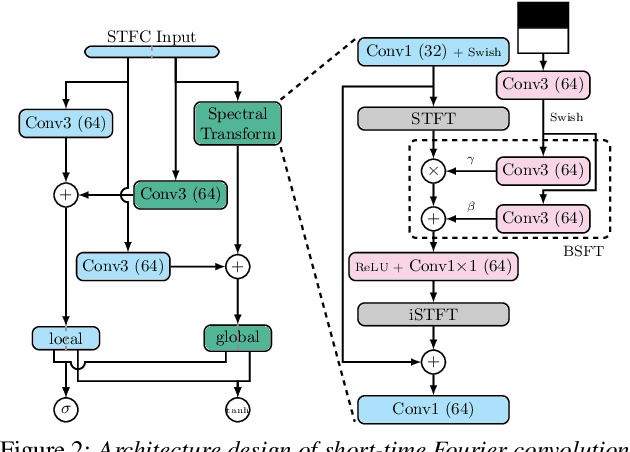
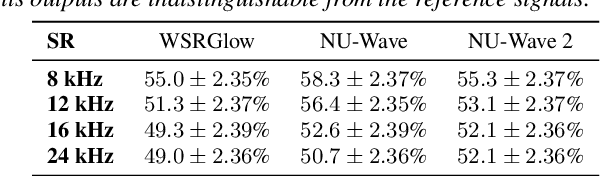
Conventionally, audio super-resolution models fixed the initial and the target sampling rates, which necessitate the model to be trained for each pair of sampling rates. We introduce NU-Wave 2, a diffusion model for neural audio upsampling that enables the generation of 48 kHz audio signals from inputs of various sampling rates with a single model. Based on the architecture of NU-Wave, NU-Wave 2 uses short-time Fourier convolution (STFC) to generate harmonics to resolve the main failure modes of NU-Wave, and incorporates bandwidth spectral feature transform (BSFT) to condition the bandwidths of inputs in the frequency domain. We experimentally demonstrate that NU-Wave 2 produces high-resolution audio regardless of the sampling rate of input while requiring fewer parameters than other models. The official code and the audio samples are available at https://mindslab-ai.github.io/nuwave2.