 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJustas Dauparas
Iterative SE(3)-Transformers
Mar 16, 2021




When manipulating three-dimensional data, it is possible to ensure that rotational and translational symmetries are respected by applying so-called SE(3)-equivariant models. Protein structure prediction is a prominent example of a task which displays these symmetries. Recent work in this area has successfully made use of an SE(3)-equivariant model, applying an iterative SE(3)-equivariant attention mechanism. Motivated by this application, we implement an iterative version of the SE(3)-Transformer, an SE(3)-equivariant attention-based model for graph data. We address the additional complications which arise when applying the SE(3)-Transformer in an iterative fashion, compare the iterative and single-pass versions on a toy problem, and consider why an iterative model may be beneficial in some problem settings. We make the code for our implementation available to the community.
Depth and nonlinearity induce implicit exploration for RL
May 29, 2018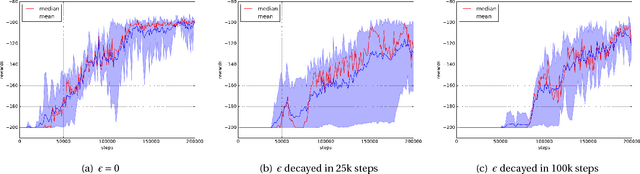
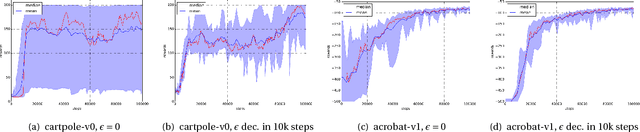
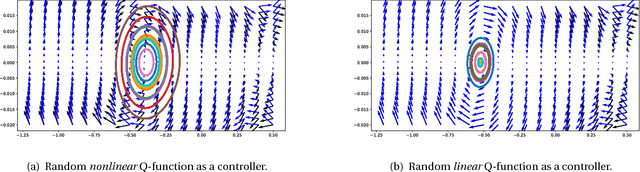
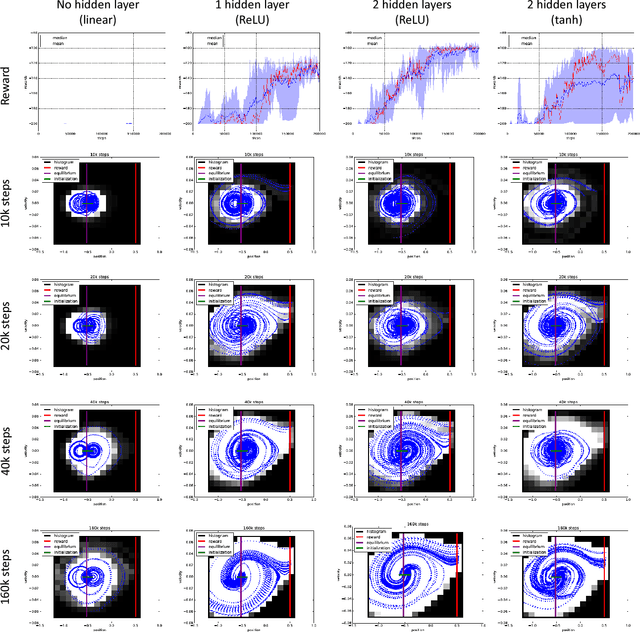
The question of how to explore, i.e., take actions with uncertain outcomes to learn about possible future rewards, is a key question in reinforcement learning (RL). Here, we show a surprising result: We show that Q-learning with nonlinear Q-function and no explicit exploration (i.e., a purely greedy policy) can learn several standard benchmark tasks, including mountain car, equally well as, or better than, the most commonly-used $\epsilon$-greedy exploration. We carefully examine this result and show that both the depth of the Q-network and the type of nonlinearity are important to induce such deterministic exploration.