 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiqu Liang
Introspective Planning: Guiding Language-Enabled Agents to Refine Their Own Uncertainty
Feb 18, 2024
Large language models (LLMs) exhibit advanced reasoning skills, enabling robots to comprehend natural language instructions and strategically plan high-level actions through proper grounding. However, LLM hallucination may result in robots confidently executing plans that are misaligned with user goals or, in extreme cases, unsafe. Additionally, inherent ambiguity in natural language instructions can induce task uncertainty, particularly in situations where multiple valid options exist. To address this issue, LLMs must identify such uncertainty and proactively seek clarification. This paper explores the concept of introspective planning as a systematic method for guiding LLMs in forming uncertainty--aware plans for robotic task execution without the need for fine-tuning. We investigate uncertainty quantification in task-level robot planning and demonstrate that introspection significantly improves both success rates and safety compared to state-of-the-art LLM-based planning approaches. Furthermore, we assess the effectiveness of introspective planning in conjunction with conformal prediction, revealing that this combination yields tighter confidence bounds, thereby maintaining statistical success guarantees with fewer superfluous user clarification queries.
Who Plays First? Optimizing the Order of Play in Stackelberg Games with Many Robots
Feb 14, 2024We consider the multi-agent spatial navigation problem of computing the socially optimal order of play, i.e., the sequence in which the agents commit to their decisions, and its associated equilibrium in an N-player Stackelberg trajectory game. We model this problem as a mixed-integer optimization problem over the space of all possible Stackelberg games associated with the order of play's permutations. To solve the problem, we introduce Branch and Play (B&P), an efficient and exact algorithm that provably converges to a socially optimal order of play and its Stackelberg equilibrium. As a subroutine for B&P, we employ and extend sequential trajectory planning, i.e., a popular multi-agent control approach, to scalably compute valid local Stackelberg equilibria for any given order of play. We demonstrate the practical utility of B&P to coordinate air traffic control, swarm formation, and delivery vehicle fleets. We find that B&P consistently outperforms various baselines, and computes the socially optimal equilibrium.
Simple Baselines for Interactive Video Retrieval with Questions and Answers
Aug 21, 2023To date, the majority of video retrieval systems have been optimized for a "single-shot" scenario in which the user submits a query in isolation, ignoring previous interactions with the system. Recently, there has been renewed interest in interactive systems to enhance retrieval, but existing approaches are complex and deliver limited gains in performance. In this work, we revisit this topic and propose several simple yet effective baselines for interactive video retrieval via question-answering. We employ a VideoQA model to simulate user interactions and show that this enables the productive study of the interactive retrieval task without access to ground truth dialogue data. Experiments on MSR-VTT, MSVD, and AVSD show that our framework using question-based interaction significantly improves the performance of text-based video retrieval systems.
Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
Nov 18, 2022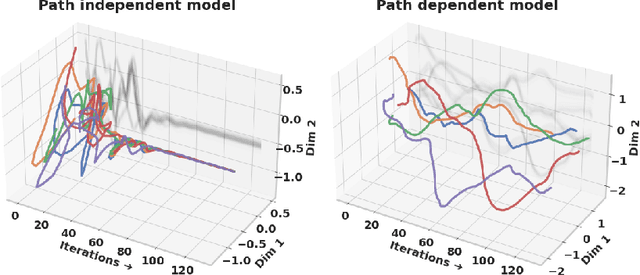

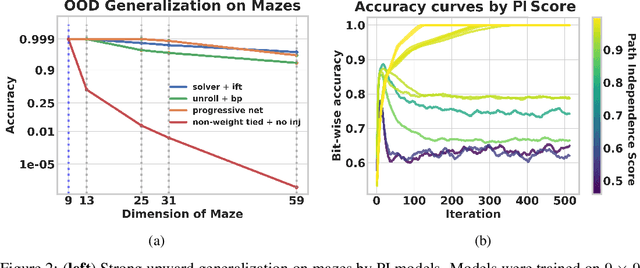
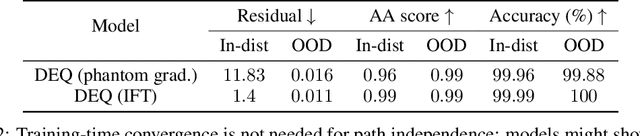
Designing networks capable of attaining better performance with an increased inference budget is important to facilitate generalization to harder problem instances. Recent efforts have shown promising results in this direction by making use of depth-wise recurrent networks. We show that a broad class of architectures named equilibrium models display strong upwards generalization, and find that stronger performance on harder examples (which require more iterations of inference to get correct) strongly correlates with the path independence of the system -- its tendency to converge to the same steady-state behaviour regardless of initialization, given enough computation. Experimental interventions made to promote path independence result in improved generalization on harder problem instances, while those that penalize it degrade this ability. Path independence analyses are also useful on a per-example basis: for equilibrium models that have good in-distribution performance, path independence on out-of-distribution samples strongly correlates with accuracy. Our results help explain why equilibrium models are capable of strong upwards generalization and motivates future work that harnesses path independence as a general modelling principle to facilitate scalable test-time usage.