 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaren Ullrich
On the Challenges and Opportunities in Generative AI
Feb 28, 2024
The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models
Jan 28, 2023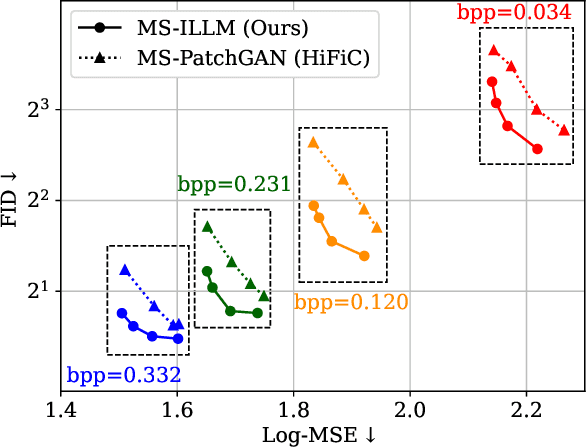
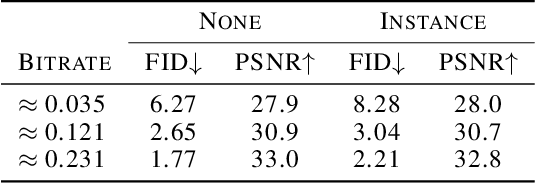
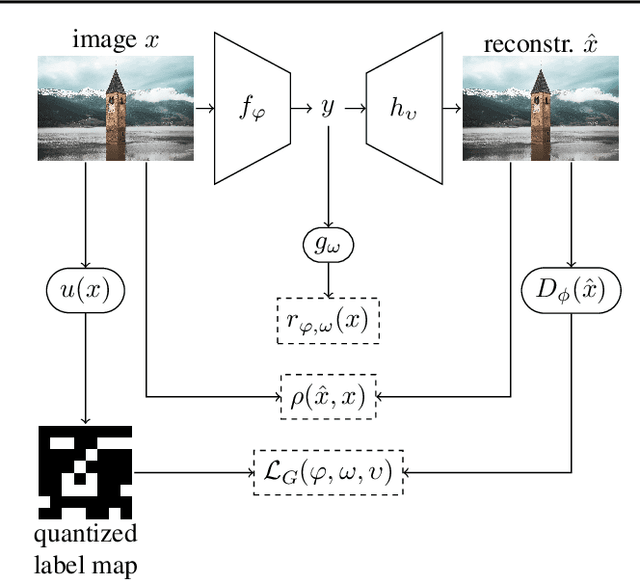

Lossy image compression aims to represent images in as few bits as possible while maintaining fidelity to the original. Theoretical results indicate that optimizing distortion metrics such as PSNR or MS-SSIM necessarily leads to a discrepancy in the statistics of original images from those of reconstructions, in particular at low bitrates, often manifested by the blurring of the compressed images. Previous work has leveraged adversarial discriminators to improve statistical fidelity. Yet these binary discriminators adopted from generative modeling tasks may not be ideal for image compression. In this paper, we introduce a non-binary discriminator that is conditioned on quantized local image representations obtained via VQ-VAE autoencoders. Our evaluations on the CLIC2020, DIV2K and Kodak datasets show that our discriminator is more effective for jointly optimizing distortion (e.g., PSNR) and statistical fidelity (e.g., FID) than the state-of-the-art HiFiC model. On the CLIC2020 test set, we obtain the same FID as HiFiC with 30-40% fewer bits.
Latent Discretization for Continuous-time Sequence Compression
Dec 28, 2022



Neural compression offers a domain-agnostic approach to creating codecs for lossy or lossless compression via deep generative models. For sequence compression, however, most deep sequence models have costs that scale with the sequence length rather than the sequence complexity. In this work, we instead treat data sequences as observations from an underlying continuous-time process and learn how to efficiently discretize while retaining information about the full sequence. As a consequence of decoupling sequential information from its temporal discretization, our approach allows for greater compression rates and smaller computational complexity. Moreover, the continuous-time approach naturally allows us to decode at different time intervals. We empirically verify our approach on multiple domains involving compression of video and motion capture sequences, showing that our approaches can automatically achieve reductions in bit rates by learning how to discretize.
Image Compression with Product Quantized Masked Image Modeling
Dec 14, 2022
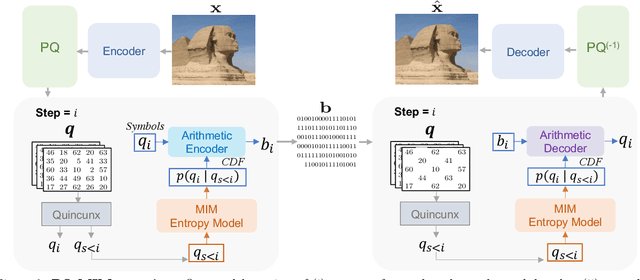
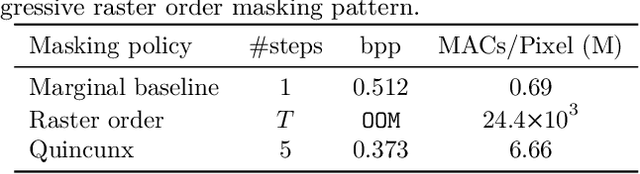
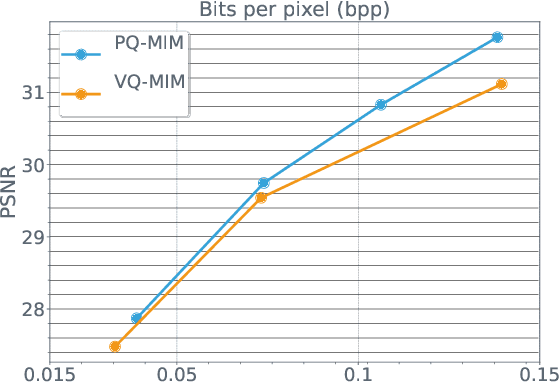
Recent neural compression methods have been based on the popular hyperprior framework. It relies on Scalar Quantization and offers a very strong compression performance. This contrasts from recent advances in image generation and representation learning, where Vector Quantization is more commonly employed. In this work, we attempt to bring these lines of research closer by revisiting vector quantization for image compression. We build upon the VQ-VAE framework and introduce several modifications. First, we replace the vanilla vector quantizer by a product quantizer. This intermediate solution between vector and scalar quantization allows for a much wider set of rate-distortion points: It implicitly defines high-quality quantizers that would otherwise require intractably large codebooks. Second, inspired by the success of Masked Image Modeling (MIM) in the context of self-supervised learning and generative image models, we propose a novel conditional entropy model which improves entropy coding by modelling the co-dependencies of the quantized latent codes. The resulting PQ-MIM model is surprisingly effective: its compression performance on par with recent hyperprior methods. It also outperforms HiFiC in terms of FID and KID metrics when optimized with perceptual losses (e.g. adversarial). Finally, since PQ-MIM is compatible with image generation frameworks, we show qualitatively that it can operate under a hybrid mode between compression and generation, with no further training or finetuning. As a result, we explore the extreme compression regime where an image is compressed into 200 bytes, i.e., less than a tweet.
An optimal control perspective on diffusion-based generative modeling
Nov 02, 2022
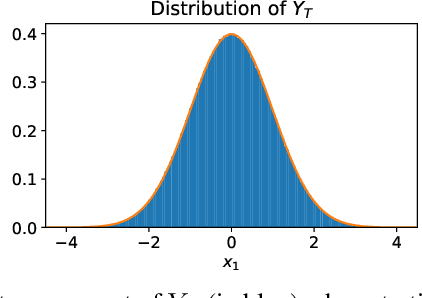
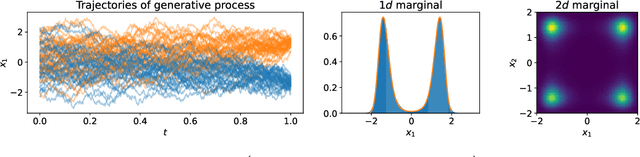
We establish a connection between stochastic optimal control and generative models based on stochastic differential equations (SDEs) such as recently developed diffusion probabilistic models. In particular, we derive a Hamilton-Jacobi-Bellman equation that governs the evolution of the log-densities of the underlying SDE marginals. This perspective allows to transfer methods from optimal control theory to generative modeling. First, we show that the evidence lower bound is a direct consequence of the well-known verification theorem from control theory. Further, we develop a novel diffusion-based method for sampling from unnormalized densities -- a problem frequently occurring in statistics and computational sciences.
Compressing Multisets with Large Alphabets
Jul 15, 2021



Current methods that optimally compress multisets are not suitable for high-dimensional symbols, as their compute time scales linearly with alphabet size. Compressing a multiset as an ordered sequence with off-the-shelf codecs is computationally more efficient, but has a sub-optimal compression rate, as bits are wasted encoding the order between symbols. We present a method that can recover those bits, assuming symbols are i.i.d., at the cost of an additional $\mathcal{O}(|\mathcal{M}|\log M)$ in average time complexity, where $|\mathcal{M}|$ and $M$ are the total and unique number of symbols in the multiset. Our method is compatible with any prefix-free code. Experiments show that, when paired with efficient coders, our method can efficiently compress high-dimensional sources such as multisets of images and collections of JSON files.
Lossy Compression for Lossless Prediction
Jul 07, 2021

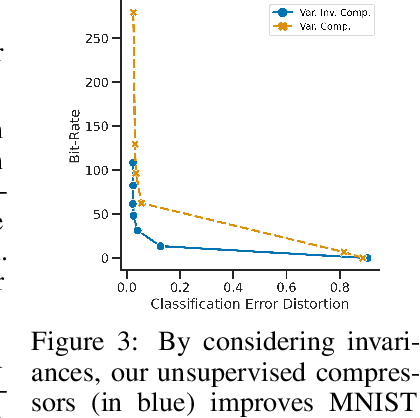
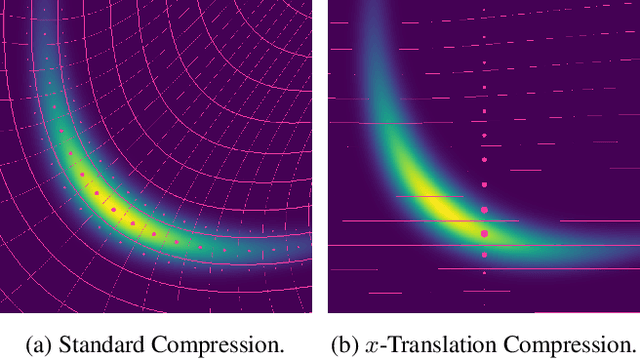
Most data is automatically collected and only ever "seen" by algorithms. Yet, data compressors preserve perceptual fidelity rather than just the information needed by algorithms performing downstream tasks. In this paper, we characterize the bit-rate required to ensure high performance on all predictive tasks that are invariant under a set of transformations, such as data augmentations. Based on our theory, we design unsupervised objectives for training neural compressors. Using these objectives, we train a generic image compressor that achieves substantial rate savings (more than $1000\times$ on ImageNet) compared to JPEG on 8 datasets, without decreasing downstream classification performance.
Improving Lossless Compression Rates via Monte Carlo Bits-Back Coding
Feb 22, 2021



Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, including entropy coding for lossy compression.
Neural Communication Systems with Bandwidth-limited Channel
Apr 01, 2020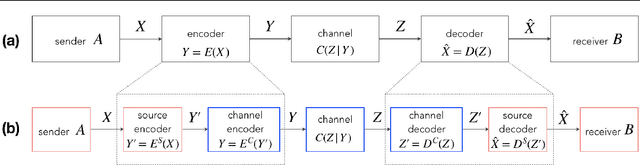
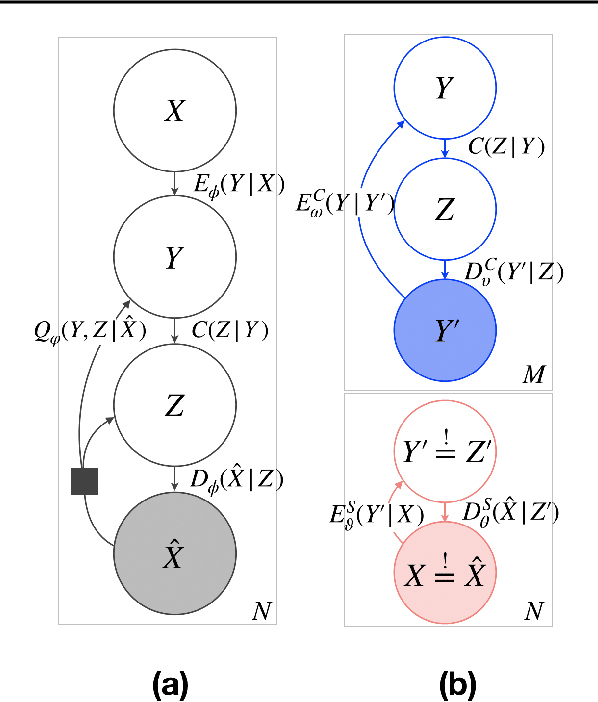
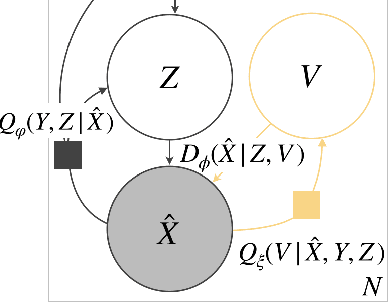
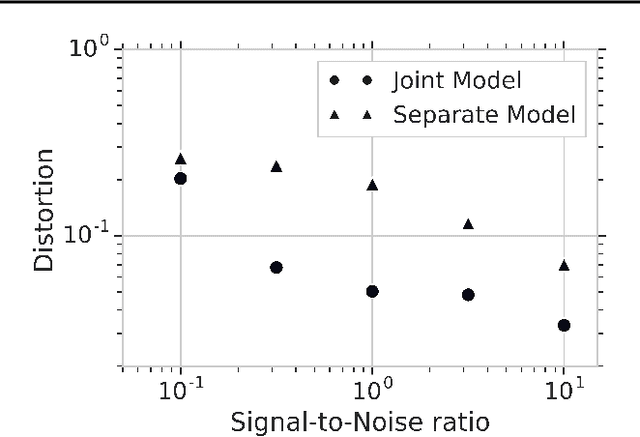
Reliably transmitting messages despite information loss due to a noisy channel is a core problem of information theory. One of the most important aspects of real world communication, e.g. via wifi, is that it may happen at varying levels of information transfer. The bandwidth-limited channel models this phenomenon. In this study we consider learning coding with the bandwidth-limited channel (BWLC). Recently, neural communication models such as variational autoencoders have been studied for the task of source compression. We build upon this work by studying neural communication systems with the BWLC. Specifically,we find three modelling choices that are relevant under expected information loss. First, instead of separating the sub-tasks of compression (source coding) and error correction (channel coding), we propose to model both jointly. Framing the problem as a variational learning problem, we conclude that joint systems outperform their separate counterparts when coding is performed by flexible learnable function approximators such as neural networks. To facilitate learning, we introduce a differentiable and computationally efficient version of the bandwidth-limited channel. Second, we propose a design to model missing information with a prior, and incorporate this into the channel model. Finally, sampling from the joint model is improved by introducing auxiliary latent variables in the decoder. Experimental results justify the validity of our design decisions through improved distortion and FID scores.
Differentiable probabilistic models of scientific imaging with the Fourier slice theorem
Jun 20, 2019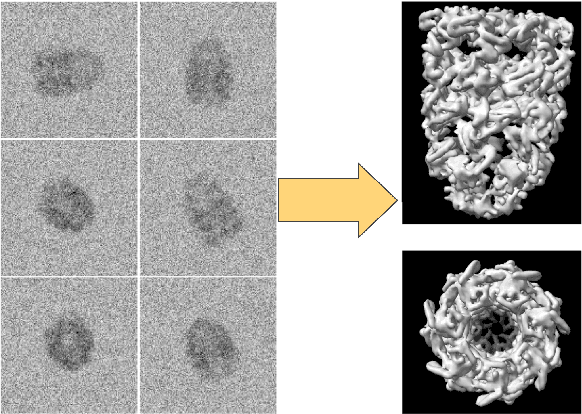


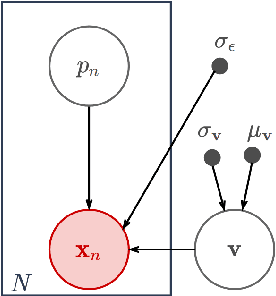
Scientific imaging techniques such as optical and electron microscopy and computed tomography (CT) scanning are used to study the 3D structure of an object through 2D observations. These observations are related to the original 3D object through orthogonal integral projections. For common 3D reconstruction algorithms, computational efficiency requires the modeling of the 3D structures to take place in Fourier space by applying the Fourier slice theorem. At present, it is unclear how to differentiate through the projection operator, and hence current learning algorithms can not rely on gradient based methods to optimize 3D structure models. In this paper we show how back-propagation through the projection operator in Fourier space can be achieved. We demonstrate the validity of the approach with experiments on 3D reconstruction of proteins. We further extend our approach to learning probabilistic models of 3D objects. This allows us to predict regions of low sampling rates or estimate noise. A higher sample efficiency can be reached by utilizing the learned uncertainties of the 3D structure as an unsupervised estimate of the model fit. Finally, we demonstrate how the reconstruction algorithm can be extended with an amortized inference scheme on unknown attributes such as object pose. Through empirical studies we show that joint inference of the 3D structure and the object pose becomes more difficult when the ground truth object contains more symmetries. Due to the presence of for instance (approximate) rotational symmetries, the pose estimation can easily get stuck in local optima, inhibiting a fine-grained high-quality estimate of the 3D structure.