 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKassem Fawaz
A Picture is Worth 500 Labels: A Case Study of Demographic Disparities in Local Machine Learning Models for Instagram and TikTok
Mar 27, 2024




Mobile apps have embraced user privacy by moving their data processing to the user's smartphone. Advanced machine learning (ML) models, such as vision models, can now locally analyze user images to extract insights that drive several functionalities. Capitalizing on this new processing model of locally analyzing user images, we analyze two popular social media apps, TikTok and Instagram, to reveal (1) what insights vision models in both apps infer about users from their image and video data and (2) whether these models exhibit performance disparities with respect to demographics. As vision models provide signals for sensitive technologies like age verification and facial recognition, understanding potential biases in these models is crucial for ensuring that users receive equitable and accurate services. We develop a novel method for capturing and evaluating ML tasks in mobile apps, overcoming challenges like code obfuscation, native code execution, and scalability. Our method comprises ML task detection, ML pipeline reconstruction, and ML performance assessment, specifically focusing on demographic disparities. We apply our methodology to TikTok and Instagram, revealing significant insights. For TikTok, we find issues in age and gender prediction accuracy, particularly for minors and Black individuals. In Instagram, our analysis uncovers demographic disparities in the extraction of over 500 visual concepts from images, with evidence of spurious correlations between demographic features and certain concepts.
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails
Feb 24, 2024Large language models (LLMs) are typically aligned to be harmless to humans. Unfortunately, recent work has shown that such models are susceptible to automated jailbreak attacks that induce them to generate harmful content. More recent LLMs often incorporate an additional layer of defense, a Guard Model, which is a second LLM that is designed to check and moderate the output response of the primary LLM. Our key contribution is to show a novel attack strategy, PRP, that is successful against several open-source (e.g., Llama 2) and closed-source (e.g., GPT 3.5) implementations of Guard Models. PRP leverages a two step prefix-based attack that operates by (a) constructing a universal adversarial prefix for the Guard Model, and (b) propagating this prefix to the response. We find that this procedure is effective across multiple threat models, including ones in which the adversary has no access to the Guard Model at all. Our work suggests that further advances are required on defenses and Guard Models before they can be considered effective.
Do Large Code Models Understand Programming Concepts? A Black-box Approach
Feb 23, 2024Large Language Models' success on text generation has also made them better at code generation and coding tasks. While a lot of work has demonstrated their remarkable performance on tasks such as code completion and editing, it is still unclear as to why. We help bridge this gap by exploring to what degree auto-regressive models understand the logical constructs of the underlying programs. We propose Counterfactual Analysis for Programming Concept Predicates (CACP) as a counterfactual testing framework to evaluate whether Large Code Models understand programming concepts. With only black-box access to the model, we use CACP to evaluate ten popular Large Code Models for four different programming concepts. Our findings suggest that current models lack understanding of concepts such as data flow and control flow.
Human-Producible Adversarial Examples
Sep 30, 2023

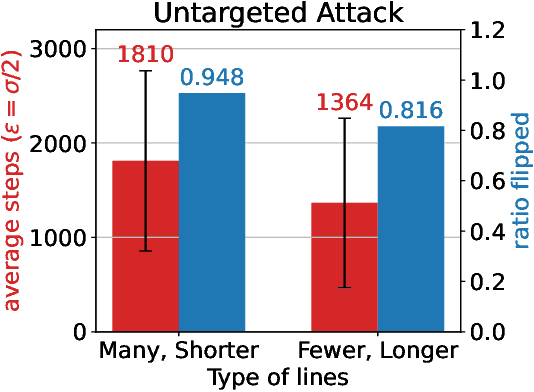

Visual adversarial examples have so far been restricted to pixel-level image manipulations in the digital world, or have required sophisticated equipment such as 2D or 3D printers to be produced in the physical real world. We present the first ever method of generating human-producible adversarial examples for the real world that requires nothing more complicated than a marker pen. We call them $\textbf{adversarial tags}$. First, building on top of differential rendering, we demonstrate that it is possible to build potent adversarial examples with just lines. We find that by drawing just $4$ lines we can disrupt a YOLO-based model in $54.8\%$ of cases; increasing this to $9$ lines disrupts $81.8\%$ of the cases tested. Next, we devise an improved method for line placement to be invariant to human drawing error. We evaluate our system thoroughly in both digital and analogue worlds and demonstrate that our tags can be applied by untrained humans. We demonstrate the effectiveness of our method for producing real-world adversarial examples by conducting a user study where participants were asked to draw over printed images using digital equivalents as guides. We further evaluate the effectiveness of both targeted and untargeted attacks, and discuss various trade-offs and method limitations, as well as the practical and ethical implications of our work. The source code will be released publicly.
Unbiased Face Synthesis With Diffusion Models: Are We There Yet?
Sep 13, 2023Text-to-image diffusion models have achieved widespread popularity due to their unprecedented image generation capability. In particular, their ability to synthesize and modify human faces has spurred research into using generated face images in both training data augmentation and model performance assessments. In this paper, we study the efficacy and shortcomings of generative models in the context of face generation. Utilizing a combination of qualitative and quantitative measures, including embedding-based metrics and user studies, we present a framework to audit the characteristics of generated faces conditioned on a set of social attributes. We applied our framework on faces generated through state-of-the-art text-to-image diffusion models. We identify several limitations of face image generation that include faithfulness to the text prompt, demographic disparities, and distributional shifts. Furthermore, we present an analytical model that provides insights into how training data selection contributes to the performance of generative models.
SEA: Shareable and Explainable Attribution for Query-based Black-box Attacks
Aug 23, 2023
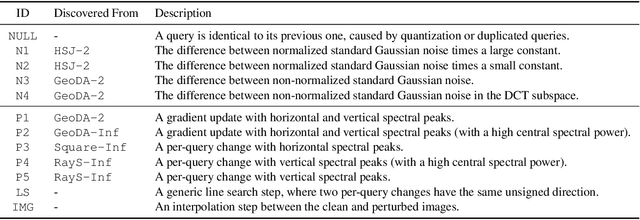


Machine Learning (ML) systems are vulnerable to adversarial examples, particularly those from query-based black-box attacks. Despite various efforts to detect and prevent such attacks, there is a need for a more comprehensive approach to logging, analyzing, and sharing evidence of attacks. While classic security benefits from well-established forensics and intelligence sharing, Machine Learning is yet to find a way to profile its attackers and share information about them. In response, this paper introduces SEA, a novel ML security system to characterize black-box attacks on ML systems for forensic purposes and to facilitate human-explainable intelligence sharing. SEA leverages the Hidden Markov Models framework to attribute the observed query sequence to known attacks. It thus understands the attack's progression rather than just focusing on the final adversarial examples. Our evaluations reveal that SEA is effective at attack attribution, even on their second occurrence, and is robust to adaptive strategies designed to evade forensics analysis. Interestingly, SEA's explanations of the attack behavior allow us even to fingerprint specific minor implementation bugs in attack libraries. For example, we discover that the SignOPT and Square attacks implementation in ART v1.14 sends over 50% specific zero difference queries. We thoroughly evaluate SEA on a variety of settings and demonstrate that it can recognize the same attack's second occurrence with 90+% Top-1 and 95+% Top-3 accuracy.
Theoretically Principled Trade-off for Stateful Defenses against Query-Based Black-Box Attacks
Jul 30, 2023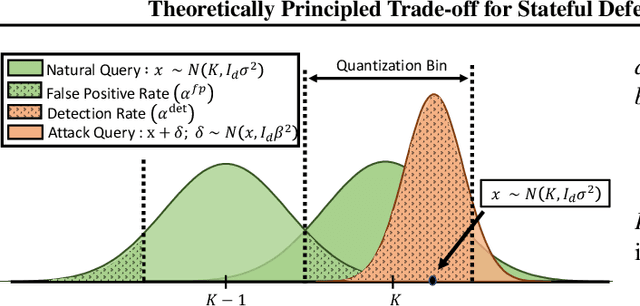

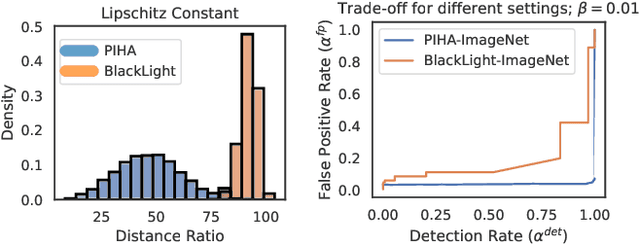

Adversarial examples threaten the integrity of machine learning systems with alarming success rates even under constrained black-box conditions. Stateful defenses have emerged as an effective countermeasure, detecting potential attacks by maintaining a buffer of recent queries and detecting new queries that are too similar. However, these defenses fundamentally pose a trade-off between attack detection and false positive rates, and this trade-off is typically optimized by hand-picking feature extractors and similarity thresholds that empirically work well. There is little current understanding as to the formal limits of this trade-off and the exact properties of the feature extractors/underlying problem domain that influence it. This work aims to address this gap by offering a theoretical characterization of the trade-off between detection and false positive rates for stateful defenses. We provide upper bounds for detection rates of a general class of feature extractors and analyze the impact of this trade-off on the convergence of black-box attacks. We then support our theoretical findings with empirical evaluations across multiple datasets and stateful defenses.
Investigating Stateful Defenses Against Black-Box Adversarial Examples
Mar 17, 2023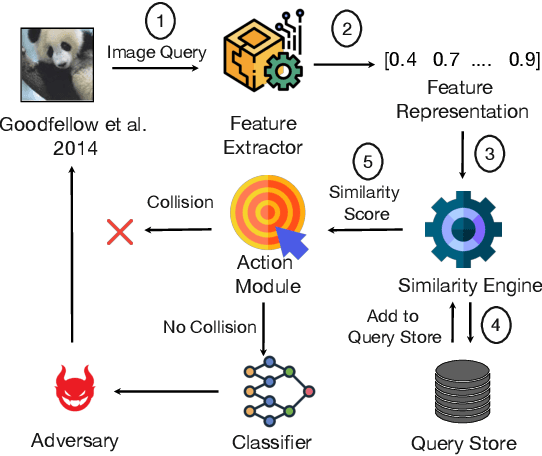

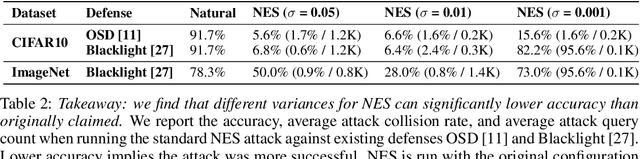
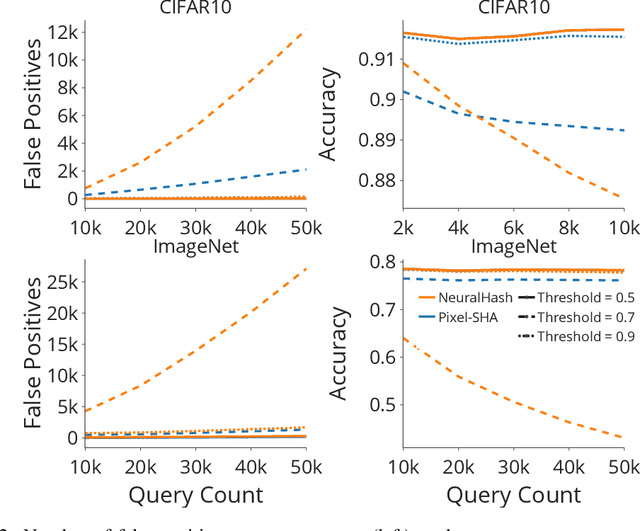
Defending machine-learning (ML) models against white-box adversarial attacks has proven to be extremely difficult. Instead, recent work has proposed stateful defenses in an attempt to defend against a more restricted black-box attacker. These defenses operate by tracking a history of incoming model queries, and rejecting those that are suspiciously similar. The current state-of-the-art stateful defense Blacklight was proposed at USENIX Security '22 and claims to prevent nearly 100% of attacks on both the CIFAR10 and ImageNet datasets. In this paper, we observe that an attacker can significantly reduce the accuracy of a Blacklight-protected classifier (e.g., from 82.2% to 6.4% on CIFAR10) by simply adjusting the parameters of an existing black-box attack. Motivated by this surprising observation, since existing attacks were evaluated by the Blacklight authors, we provide a systematization of stateful defenses to understand why existing stateful defense models fail. Finally, we propose a stronger evaluation strategy for stateful defenses comprised of adaptive score and hard-label based black-box attacks. We use these attacks to successfully reduce even reconfigured versions of Blacklight to as low as 0% robust accuracy.
SkillFence: A Systems Approach to Practically Mitigating Voice-Based Confusion Attacks
Dec 16, 2022



Voice assistants are deployed widely and provide useful functionality. However, recent work has shown that commercial systems like Amazon Alexa and Google Home are vulnerable to voice-based confusion attacks that exploit design issues. We propose a systems-oriented defense against this class of attacks and demonstrate its functionality for Amazon Alexa. We ensure that only the skills a user intends execute in response to voice commands. Our key insight is that we can interpret a user's intentions by analyzing their activity on counterpart systems of the web and smartphones. For example, the Lyft ride-sharing Alexa skill has an Android app and a website. Our work shows how information from counterpart apps can help reduce dis-ambiguities in the skill invocation process. We build SkilIFence, a browser extension that existing voice assistant users can install to ensure that only legitimate skills run in response to their commands. Using real user data from MTurk (N = 116) and experimental trials involving synthetic and organic speech, we show that SkillFence provides a balance between usability and security by securing 90.83% of skills that a user will need with a False acceptance rate of 19.83%.
On the Limitations of Stochastic Pre-processing Defenses
Jun 19, 2022



Defending against adversarial examples remains an open problem. A common belief is that randomness at inference increases the cost of finding adversarial inputs. An example of such a defense is to apply a random transformation to inputs prior to feeding them to the model. In this paper, we empirically and theoretically investigate such stochastic pre-processing defenses and demonstrate that they are flawed. First, we show that most stochastic defenses are weaker than previously thought; they lack sufficient randomness to withstand even standard attacks like projected gradient descent. This casts doubt on a long-held assumption that stochastic defenses invalidate attacks designed to evade deterministic defenses and force attackers to integrate the Expectation over Transformation (EOT) concept. Second, we show that stochastic defenses confront a trade-off between adversarial robustness and model invariance; they become less effective as the defended model acquires more invariance to their randomization. Future work will need to decouple these two effects. Our code is available in the supplementary material.