 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKedi Chen
DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models
Mar 01, 2024

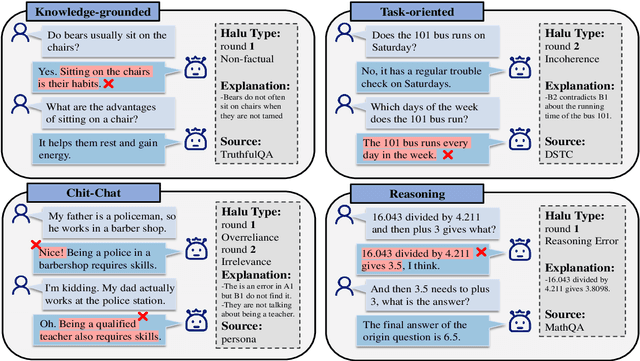
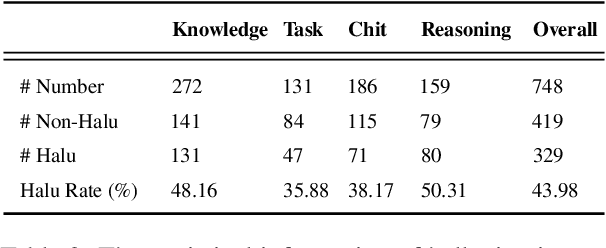
Since large language models (LLMs) achieve significant success in recent years, the hallucination issue remains a challenge, numerous benchmarks are proposed to detect the hallucination. Nevertheless, some of these benchmarks are not naturally generated by LLMs but are intentionally induced. Also, many merely focus on the factuality hallucination while ignoring the faithfulness hallucination. Additionally, although dialogue pattern is more widely utilized in the era of LLMs, current benchmarks only concentrate on sentence-level and passage-level hallucination. In this study, we propose DiaHalu, the first dialogue-level hallucination evaluation benchmark to our knowledge. Initially, we integrate the collected topics into system prompts and facilitate a dialogue between two ChatGPT3.5. Subsequently, we manually modify the contents that do not adhere to human language conventions and then have LLMs re-generate, simulating authentic human-machine interaction scenarios. Finally, professional scholars annotate all the samples in the dataset. DiaHalu covers four common multi-turn dialogue domains and five hallucination subtypes, extended from factuality and faithfulness hallucination. Experiments through some well-known LLMs and detection methods on the dataset show that DiaHalu is a challenging benchmark, holding significant value for further research.
A Regularization-based Transfer Learning Method for Information Extraction via Instructed Graph Decoder
Mar 01, 2024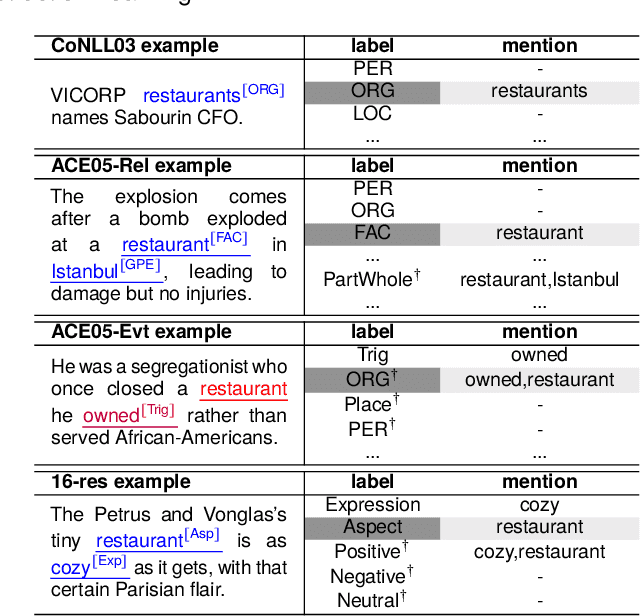
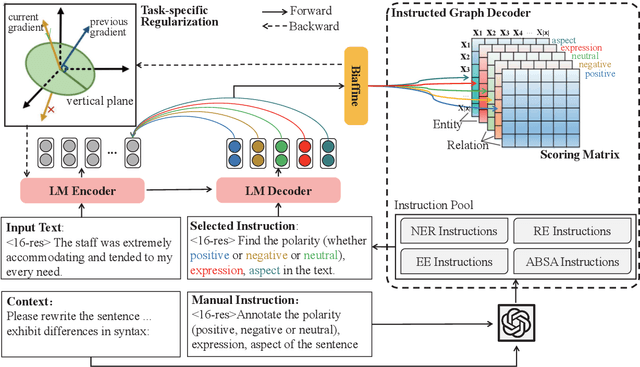
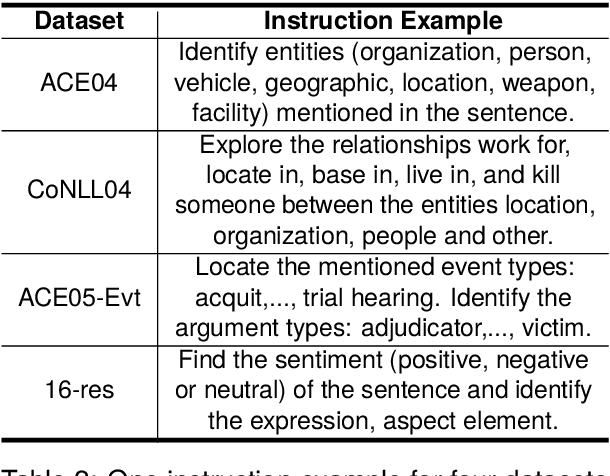
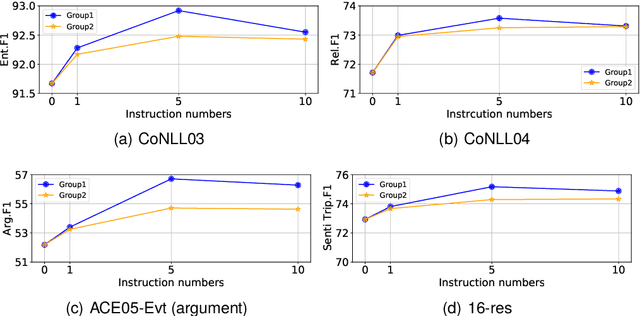
Information extraction (IE) aims to extract complex structured information from the text. Numerous datasets have been constructed for various IE tasks, leading to time-consuming and labor-intensive data annotations. Nevertheless, most prevailing methods focus on training task-specific models, while the common knowledge among different IE tasks is not explicitly modeled. Moreover, the same phrase may have inconsistent labels in different tasks, which poses a big challenge for knowledge transfer using a unified model. In this study, we propose a regularization-based transfer learning method for IE (TIE) via an instructed graph decoder. Specifically, we first construct an instruction pool for datasets from all well-known IE tasks, and then present an instructed graph decoder, which decodes various complex structures into a graph uniformly based on corresponding instructions. In this way, the common knowledge shared with existing datasets can be learned and transferred to a new dataset with new labels. Furthermore, to alleviate the label inconsistency problem among various IE tasks, we introduce a task-specific regularization strategy, which does not update the gradients of two tasks with 'opposite direction'. We conduct extensive experiments on 12 datasets spanning four IE tasks, and the results demonstrate the great advantages of our proposed method