 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeke He
T-Pixel2Mesh: Combining Global and Local Transformer for 3D Mesh Generation from a Single Image
Mar 20, 2024
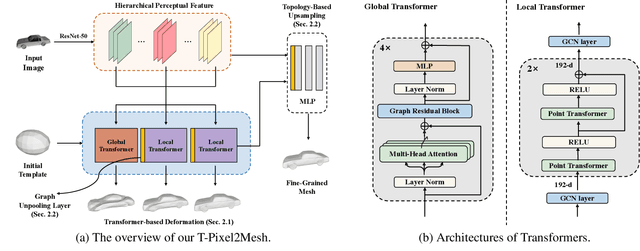
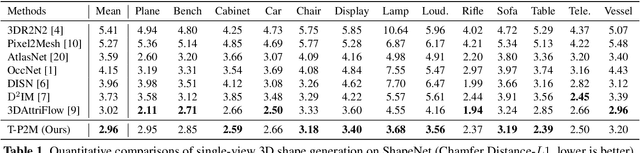
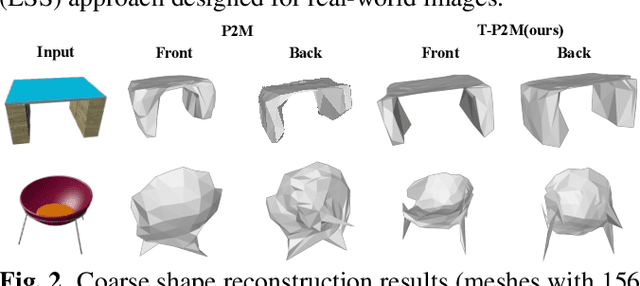
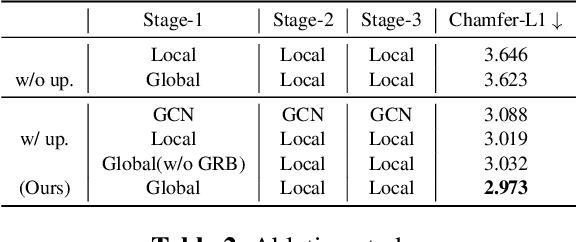
Pixel2Mesh (P2M) is a classical approach for reconstructing 3D shapes from a single color image through coarse-to-fine mesh deformation. Although P2M is capable of generating plausible global shapes, its Graph Convolution Network (GCN) often produces overly smooth results, causing the loss of fine-grained geometry details. Moreover, P2M generates non-credible features for occluded regions and struggles with the domain gap from synthetic data to real-world images, which is a common challenge for single-view 3D reconstruction methods. To address these challenges, we propose a novel Transformer-boosted architecture, named T-Pixel2Mesh, inspired by the coarse-to-fine approach of P2M. Specifically, we use a global Transformer to control the holistic shape and a local Transformer to progressively refine the local geometry details with graph-based point upsampling. To enhance real-world reconstruction, we present the simple yet effective Linear Scale Search (LSS), which serves as prompt tuning during the input preprocessing. Our experiments on ShapeNet demonstrate state-of-the-art performance, while results on real-world data show the generalization capability.
A Jointly Learned Deep Architecture for Facial Attribute Analysis and Face Detection in the Wild
Jul 27, 2017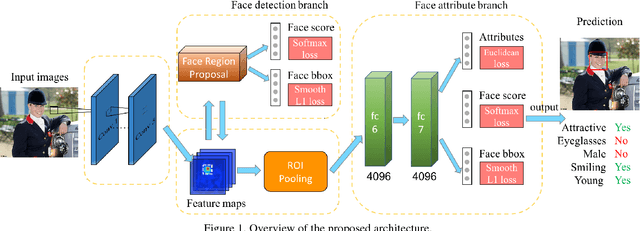
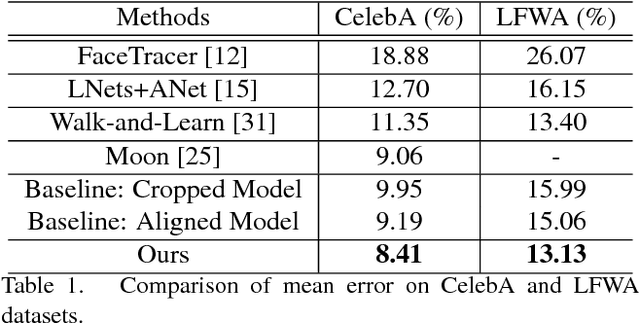
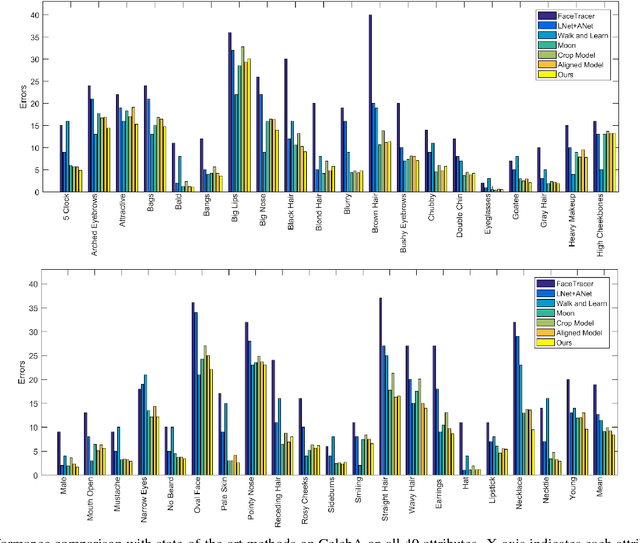
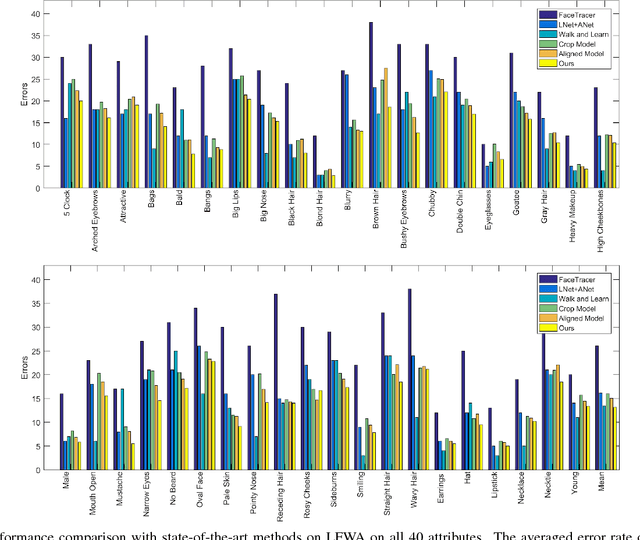
Facial attribute analysis in the real world scenario is very challenging mainly because of complex face variations. Existing works of analyzing face attributes are mostly based on the cropped and aligned face images. However, this result in the capability of attribute prediction heavily relies on the preprocessing of face detector. To address this problem, we present a novel jointly learned deep architecture for both facial attribute analysis and face detection. Our framework can process the natural images in the wild and our experiments on CelebA and LFWA datasets clearly show that the state-of-the-art performance is obtained.