 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKenji Doya
Numerical Data Imputation for Multimodal Data Sets: A Probabilistic Nearest-Neighbor Kernel Density Approach
Jul 10, 2023




Numerical data imputation algorithms replace missing values by estimates to leverage incomplete data sets. Current imputation methods seek to minimize the error between the unobserved ground truth and the imputed values. But this strategy can create artifacts leading to poor imputation in the presence of multimodal or complex distributions. To tackle this problem, we introduce the $k$NN$\times$KDE algorithm: a data imputation method combining nearest neighbor estimation ($k$NN) and density estimation with Gaussian kernels (KDE). We compare our method with previous data imputation methods using artificial and real-world data with different data missing scenarios and various data missing rates, and show that our method can cope with complex original data structure, yields lower data imputation errors, and provides probabilistic estimates with higher likelihood than current methods. We release the code in open-source for the community: https://github.com/DeltaFloflo/knnxkde
* 30 pages, 8 figures, accepted in TMLR (Reproducibility certification)
Habits and goals in synergy: a variational Bayesian framework for behavior
Apr 11, 2023



How to behave efficiently and flexibly is a central problem for understanding biological agents and creating intelligent embodied AI. It has been well known that behavior can be classified as two types: reward-maximizing habitual behavior, which is fast while inflexible; and goal-directed behavior, which is flexible while slow. Conventionally, habitual and goal-directed behaviors are considered handled by two distinct systems in the brain. Here, we propose to bridge the gap between the two behaviors, drawing on the principles of variational Bayesian theory. We incorporate both behaviors in one framework by introducing a Bayesian latent variable called "intention". The habitual behavior is generated by using prior distribution of intention, which is goal-less; and the goal-directed behavior is generated by the posterior distribution of intention, which is conditioned on the goal. Building on this idea, we present a novel Bayesian framework for modeling behaviors. Our proposed framework enables skill sharing between the two kinds of behaviors, and by leveraging the idea of predictive coding, it enables an agent to seamlessly generalize from habitual to goal-directed behavior without requiring additional training. The proposed framework suggests a fresh perspective for cognitive science and embodied AI, highlighting the potential for greater integration between habitual and goal-directed behaviors.
Goal-Directed Planning by Reinforcement Learning and Active Inference
Jun 22, 2021



What is the difference between goal-directed and habitual behavior? We propose a novel computational framework of decision making with Bayesian inference, in which everything is integrated as an entire neural network model. The model learns to predict environmental state transitions by self-exploration and generating motor actions by sampling stochastic internal states ${z}$. Habitual behavior, which is obtained from the prior distribution of ${z}$, is acquired by reinforcement learning. Goal-directed behavior is determined from the posterior distribution of ${z}$ by planning, using active inference which optimizes the past, current and future ${z}$ by minimizing the variational free energy for the desired future observation constrained by the observed sensory sequence. We demonstrate the effectiveness of the proposed framework by experiments in a sensorimotor navigation task with camera observations and continuous motor actions.
Whole brain Probabilistic Generative Model toward Realizing Cognitive Architecture for Developmental Robots
Mar 15, 2021Building a humanlike integrative artificial cognitive system, that is, an artificial general intelligence, is one of the goals in artificial intelligence and developmental robotics. Furthermore, a computational model that enables an artificial cognitive system to achieve cognitive development will be an excellent reference for brain and cognitive science. This paper describes the development of a cognitive architecture using probabilistic generative models (PGMs) to fully mirror the human cognitive system. The integrative model is called a whole-brain PGM (WB-PGM). It is both brain-inspired and PGMbased. In this paper, the process of building the WB-PGM and learning from the human brain to build cognitive architectures is described.
Imitation learning based on entropy-regularized forward and inverse reinforcement learning
Aug 17, 2020



This paper proposes Entropy-Regularized Imitation Learning (ERIL), which is a combination of forward and inverse reinforcement learning under the framework of the entropy-regularized Markov decision process. ERIL minimizes the reverse Kullback-Leibler (KL) divergence between two probability distributions induced by a learner and an expert. Inverse reinforcement learning (RL) in ERIL evaluates the log-ratio between two distributions using the density ratio trick, which is widely used in generative adversarial networks. More specifically, the log-ratio is estimated by building two binary discriminators. The first discriminator is a state-only function, and it tries to distinguish the state generated by the forward RL step from the expert's state. The second discriminator is a function of current state, action, and transitioned state, and it distinguishes the generated experiences from the ones provided by the expert. Since the second discriminator has the same hyperparameters of the forward RL step, it can be used to control the discriminator's ability. The forward RL minimizes the reverse KL estimated by the inverse RL. We show that minimizing the reverse KL divergence is equivalent to finding an optimal policy under entropy regularization. Consequently, a new policy is derived from an algorithm that resembles Dynamic Policy Programming and Soft Actor-Critic. Our experimental results on MuJoCo-simulated environments show that ERIL is more sample-efficient than such previous methods. We further apply the method to human behaviors in performing a pole-balancing task and show that the estimated reward functions show how every subject achieves the goal.
Variational Recurrent Models for Solving Partially Observable Control Tasks
Dec 24, 2019



In partially observable (PO) environments, deep reinforcement learning (RL) agents often suffer from unsatisfactory performance, since two problems need to be tackled together: how to extract information from the raw observations to solve the task, and how to improve the policy. In this study, we propose an RL algorithm for solving PO tasks. Our method comprises two parts: a variational recurrent model (VRM) for modeling the environment, and an RL controller that has access to both the environment and the VRM. The proposed algorithm was tested in two types of PO robotic control tasks, those in which either coordinates or velocities were not observable and those that require long-term memorization. Our experiments show that the proposed algorithm achieved better data efficiency and/or learned more optimal policy than other alternative approaches in tasks in which unobserved states cannot be inferred from raw observations in a simple manner.
MarmoNet: a pipeline for automated projection mapping of the common marmoset brain from whole-brain serial two-photon tomography
Aug 02, 2019



Understanding the connectivity in the brain is an important prerequisite for understanding how the brain processes information. In the Brain/MINDS project, a connectivity study on marmoset brains uses two-photon microscopy fluorescence images of axonal projections to collect the neuron connectivity from defined brain regions at the mesoscopic scale. The processing of the images requires the detection and segmentation of the axonal tracer signal. The objective is to detect as much tracer signal as possible while not misclassifying other background structures as the signal. This can be challenging because of imaging noise, a cluttered image background, distortions or varying image contrast cause problems. We are developing MarmoNet, a pipeline that processes and analyzes tracer image data of the common marmoset brain. The pipeline incorporates state-of-the-art machine learning techniques based on artificial convolutional neural networks (CNN) and image registration techniques to extract and map all relevant information in a robust manner. The pipeline processes new images in a fully automated way. This report introduces the current state of the tracer signal analysis part of the pipeline.
Gap-Increasing Policy Evaluation for Efficient and Noise-Tolerant Reinforcement Learning
Jun 18, 2019



In real-world applications of reinforcement learning (RL), noise from inherent stochasticity of environments is inevitable. However, current policy evaluation algorithms, which plays a key role in many RL algorithms, are either prone to noise or inefficient. To solve this issue, we introduce a novel policy evaluation algorithm, which we call Gap-increasing RetrAce Policy Evaluation (GRAPE). It leverages two recent ideas: (1) gap-increasing value update operators in advantage learning for noise-tolerance and (2) off-policy eligibility trace in Retrace algorithm for efficient learning. We provide detailed theoretical analysis of the new algorithm that shows its efficiency and noise-tolerance inherited from Retrace and advantage learning. Furthermore, our analysis shows that GRAPE's learning is significantly efficient than that of a simple learning-rate-based approach while keeping the same level of noise-tolerance. We applied GRAPE to control problems and obtained experimental results supporting our theoretical analysis.
PIPPS: Flexible Model-Based Policy Search Robust to the Curse of Chaos
Feb 04, 2019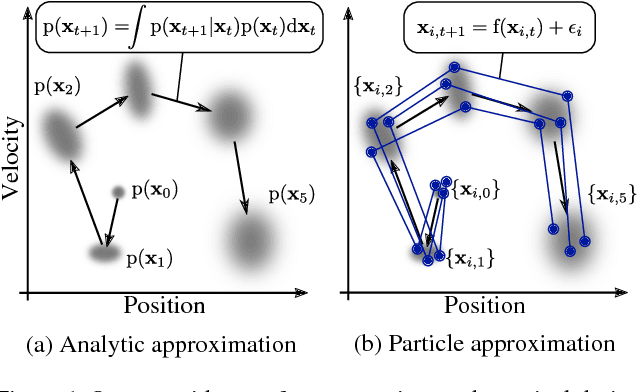
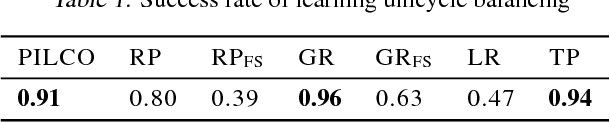
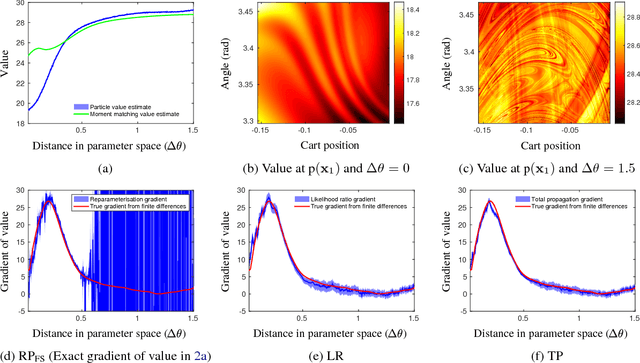

Previously, the exploding gradient problem has been explained to be central in deep learning and model-based reinforcement learning, because it causes numerical issues and instability in optimization. Our experiments in model-based reinforcement learning imply that the problem is not just a numerical issue, but it may be caused by a fundamental chaos-like nature of long chains of nonlinear computations. Not only do the magnitudes of the gradients become large, the direction of the gradients becomes essentially random. We show that reparameterization gradients suffer from the problem, while likelihood ratio gradients are robust. Using our insights, we develop a model-based policy search framework, Probabilistic Inference for Particle-Based Policy Search (PIPPS), which is easily extensible, and allows for almost arbitrary models and policies, while simultaneously matching the performance of previous data-efficient learning algorithms. Finally, we invent the total propagation algorithm, which efficiently computes a union over all pathwise derivative depths during a single backwards pass, automatically giving greater weight to estimators with lower variance, sometimes improving over reparameterization gradients by $10^6$ times.
Emergence of Hierarchy via Reinforcement Learning Using a Multiple Timescale Stochastic RNN
Jan 29, 2019



Although recurrent neural networks (RNNs) for reinforcement learning (RL) have addressed unique advantages in various aspects, e. g., solving memory-dependent tasks and meta-learning, very few studies have demonstrated how RNNs can solve the problem of hierarchical RL by autonomously developing hierarchical control. In this paper, we propose a novel model-free RL framework called ReMASTER, which combines an off-policy actor-critic algorithm with a multiple timescale stochastic recurrent neural network for solving memory-dependent and hierarchical tasks. We performed experiments using a challenging continuous control task and showed that: (1) Internal representation necessary for achieving hierarchical control autonomously develops through exploratory learning. (2) Stochastic neurons in RNNs enable faster relearning when adapting to a new task which is a recomposition of sub-goals previously learned.