 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeren Shao
Music Enhancement with Deep Filters: A Technical Report for The ICASSP 2024 Cadenza Challenge
Apr 17, 2024
In this challenge, we disentangle the deep filters from the original DeepfilterNet and incorporate them into our Spec-UNet-based network to further improve a hybrid Demucs (hdemucs) based remixing pipeline. The motivation behind the use of the deep filter component lies at its potential in better handling temporal fine structures. We demonstrate an incremental improvement in both the Signal-to-Distortion Ratio (SDR) and the Hearing Aid Audio Quality Index (HAAQI) metrics when comparing the performance of hdemucs against different versions of our model.
Towards Improving Harmonic Sensitivity and Prediction Stability for Singing Melody Extraction
Aug 04, 2023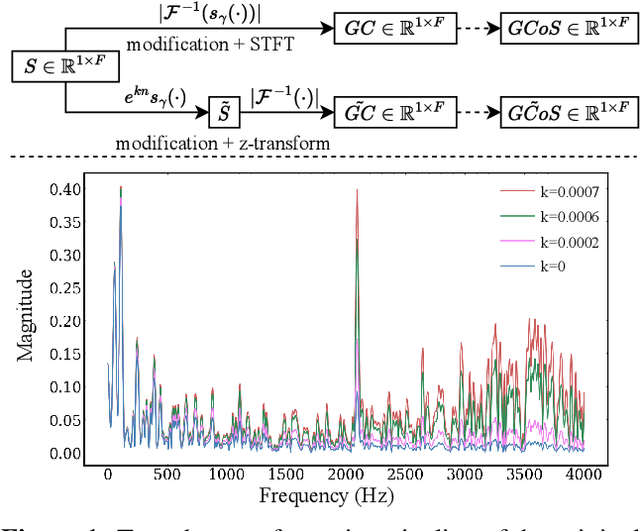
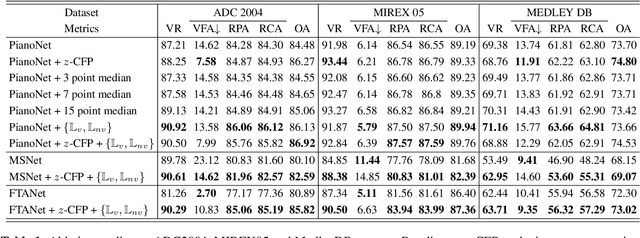
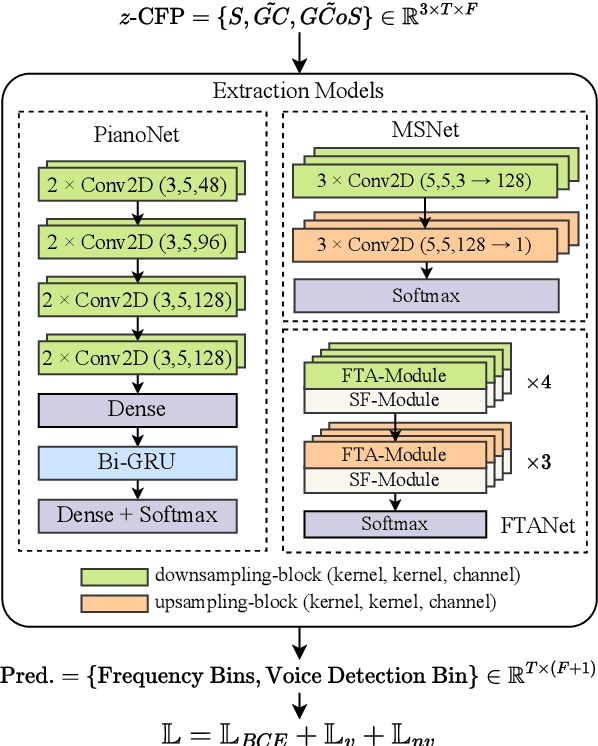
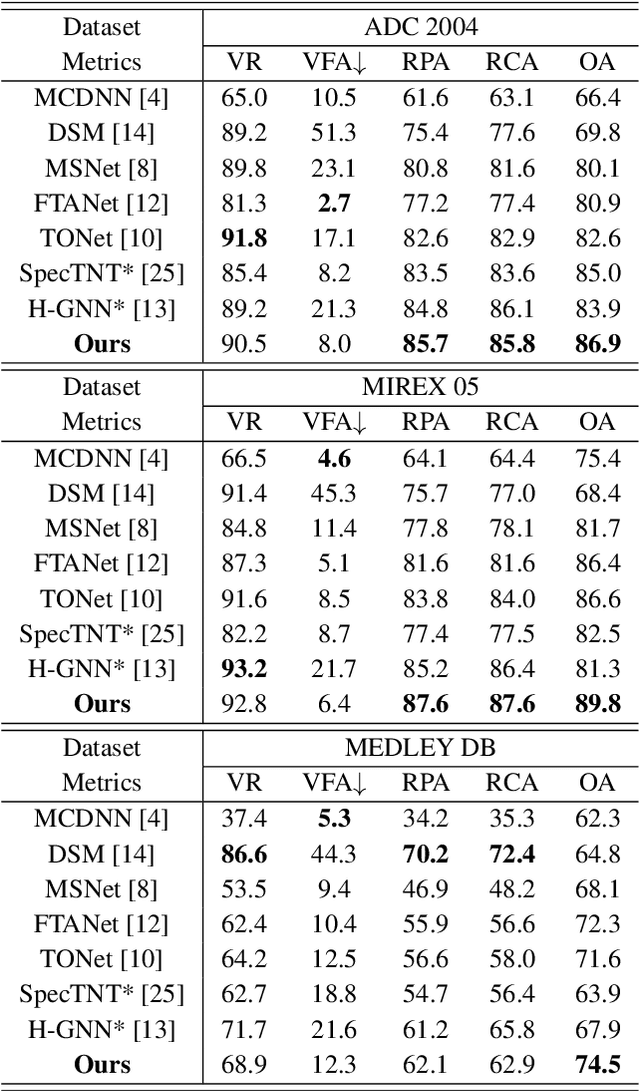
In deep learning research, many melody extraction models rely on redesigning neural network architectures to improve performance. In this paper, we propose an input feature modification and a training objective modification based on two assumptions. First, harmonics in the spectrograms of audio data decay rapidly along the frequency axis. To enhance the model's sensitivity on the trailing harmonics, we modify the Combined Frequency and Periodicity (CFP) representation using discrete z-transform. Second, the vocal and non-vocal segments with extremely short duration are uncommon. To ensure a more stable melody contour, we design a differentiable loss function that prevents the model from predicting such segments. We apply these modifications to several models, including MSNet, FTANet, and a newly introduced model, PianoNet, modified from a piano transcription network. Our experimental results demonstrate that the proposed modifications are empirically effective for singing melody extraction.