 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKevin G. Jamieson
Query Complexity of Derivative-Free Optimization
Sep 11, 2012
This paper provides lower bounds on the convergence rate of Derivative Free Optimization (DFO) with noisy function evaluations, exposing a fundamental and unavoidable gap between the performance of algorithms with access to gradients and those with access to only function evaluations. However, there are situations in which DFO is unavoidable, and for such situations we propose a new DFO algorithm that is proved to be near optimal for the class of strongly convex objective functions. A distinctive feature of the algorithm is that it uses only Boolean-valued function comparisons, rather than function evaluations. This makes the algorithm useful in an even wider range of applications, such as optimization based on paired comparisons from human subjects, for example. We also show that regardless of whether DFO is based on noisy function evaluations or Boolean-valued function comparisons, the convergence rate is the same.
Active Ranking using Pairwise Comparisons
Dec 10, 2011
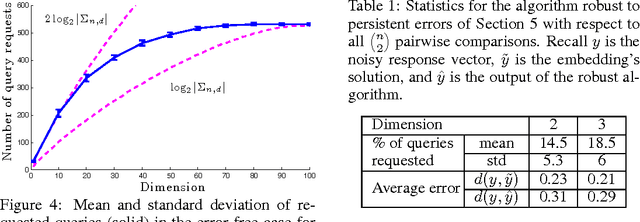
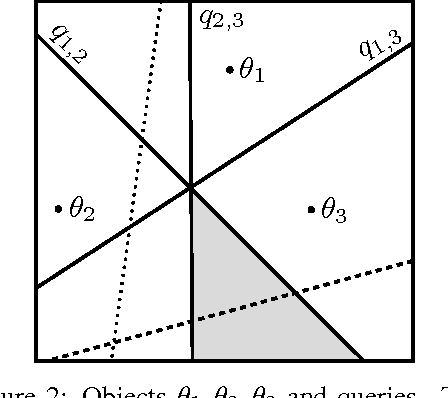

This paper examines the problem of ranking a collection of objects using pairwise comparisons (rankings of two objects). In general, the ranking of $n$ objects can be identified by standard sorting methods using $n log_2 n$ pairwise comparisons. We are interested in natural situations in which relationships among the objects may allow for ranking using far fewer pairwise comparisons. Specifically, we assume that the objects can be embedded into a $d$-dimensional Euclidean space and that the rankings reflect their relative distances from a common reference point in $R^d$. We show that under this assumption the number of possible rankings grows like $n^{2d}$ and demonstrate an algorithm that can identify a randomly selected ranking using just slightly more than $d log n$ adaptively selected pairwise comparisons, on average. If instead the comparisons are chosen at random, then almost all pairwise comparisons must be made in order to identify any ranking. In addition, we propose a robust, error-tolerant algorithm that only requires that the pairwise comparisons are probably correct. Experimental studies with synthetic and real datasets support the conclusions of our theoretical analysis.