 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhalid Saifullah
Coercing LLMs to do and reveal (almost) anything
Feb 21, 2024
It has recently been shown that adversarial attacks on large language models (LLMs) can "jailbreak" the model into making harmful statements. In this work, we argue that the spectrum of adversarial attacks on LLMs is much larger than merely jailbreaking. We provide a broad overview of possible attack surfaces and attack goals. Based on a series of concrete examples, we discuss, categorize and systematize attacks that coerce varied unintended behaviors, such as misdirection, model control, denial-of-service, or data extraction. We analyze these attacks in controlled experiments, and find that many of them stem from the practice of pre-training LLMs with coding capabilities, as well as the continued existence of strange "glitch" tokens in common LLM vocabularies that should be removed for security reasons.
On the Reliability of Watermarks for Large Language Models
Jun 30, 2023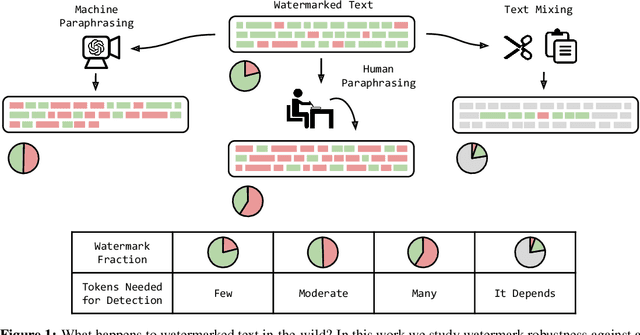

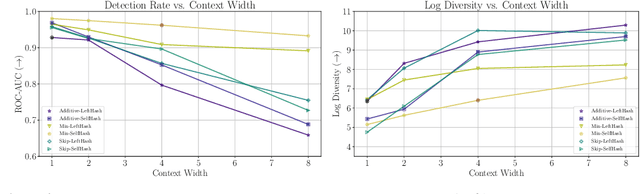

As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
Bring Your Own Data! Self-Supervised Evaluation for Large Language Models
Jun 29, 2023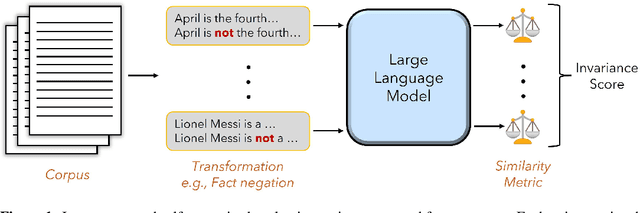

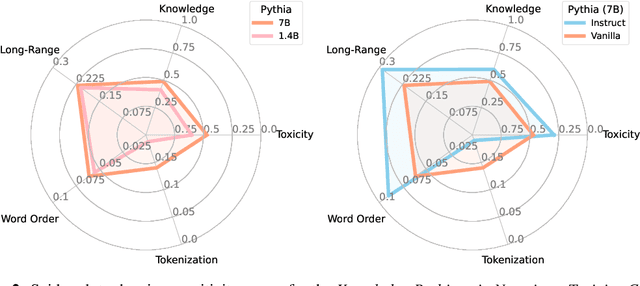

With the rise of Large Language Models (LLMs) and their ubiquitous deployment in diverse domains, measuring language model behavior on realistic data is imperative. For example, a company deploying a client-facing chatbot must ensure that the model will not respond to client requests with profanity. Current evaluations approach this problem using small, domain-specific datasets with human-curated labels. These evaluation sets are often sampled from a narrow and simplified distribution, and data sources can unknowingly be leaked into the training set which can lead to misleading evaluations. To bypass these drawbacks, we propose a framework for self-supervised evaluation of LLMs by analyzing their sensitivity or invariance to transformations on the input text. Self-supervised evaluation can directly monitor LLM behavior on datasets collected in the wild or streamed during live model deployment. We demonstrate self-supervised evaluation strategies for measuring closed-book knowledge, toxicity, and long-range context dependence, in addition to sensitivity to grammatical structure and tokenization errors. When comparisons to similar human-labeled benchmarks are available, we find strong correlations between self-supervised and human-supervised evaluations. The self-supervised paradigm complements current evaluation strategies that rely on labeled data.
Seeing in Words: Learning to Classify through Language Bottlenecks
Jun 29, 2023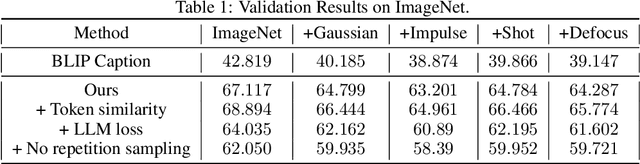

Neural networks for computer vision extract uninterpretable features despite achieving high accuracy on benchmarks. In contrast, humans can explain their predictions using succinct and intuitive descriptions. To incorporate explainability into neural networks, we train a vision model whose feature representations are text. We show that such a model can effectively classify ImageNet images, and we discuss the challenges we encountered when training it.
Reinforcement Learning finetuned Vision-Code Transformer for UI-to-Code Generation
May 24, 2023



Automated HTML/CSS code generation from screenshots is an important yet challenging problem with broad applications in website development and design. In this paper, we present a novel vision-code transformer approach that leverages an Encoder-Decoder architecture as well as explore actor-critic fine-tuning as a method for improving upon the baseline. For this purpose, two image encoders are compared: Vision Transformer (ViT) and Document Image Transformer (DiT). We propose an end-to-end pipeline that can generate high-quality code snippets directly from screenshots, streamlining the website creation process for developers. To train and evaluate our models, we created a synthetic dataset of 30,000 unique pairs of code and corresponding screenshots. We evaluate the performance of our approach using a combination of automated metrics such as MSE, BLEU, IoU, and a novel htmlBLEU score, where our models demonstrated strong performance. We establish a strong baseline with the DiT-GPT2 model and show that actor-critic can be used to improve IoU score from the baseline of 0.64 to 0.79 and lower MSE from 12.25 to 9.02. We achieved similar performance as when using larger models, with much lower computational cost.