 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKihyun Kim
Generative Autoregressive Networks for 3D Dancing Move Synthesis from Music
Nov 11, 2019
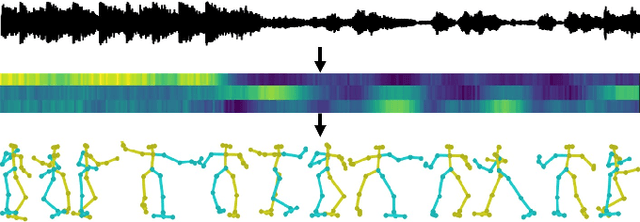

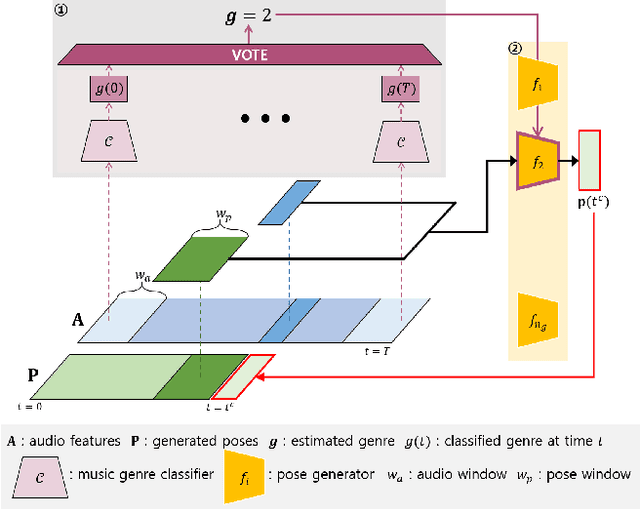
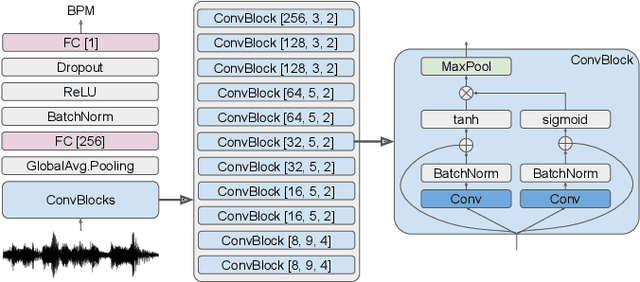
This paper proposes a framework which is able to generate a sequence of three-dimensional human dance poses for a given music. The proposed framework consists of three components: a music feature encoder, a pose generator, and a music genre classifier. We focus on integrating these components for generating a realistic 3D human dancing move from music, which can be applied to artificial agents and humanoid robots. The trained dance pose generator, which is a generative autoregressive model, is able to synthesize a dance sequence longer than 5,000 pose frames. Experimental results of generated dance sequences from various songs show how the proposed method generates human-like dancing move to a given music. In addition, a generated 3D dance sequence is applied to a humanoid robot, showing that the proposed framework can make a robot to dance just by listening to music.
Differential Generative Adversarial Networks: Synthesizing Non-linear Facial Variations with Limited Number of Training Data
Dec 29, 2017



In face-related applications with a public available dataset, synthesizing non-linear facial variations (e.g., facial expression, head-pose, illumination, etc.) through a generative model is helpful in addressing the lack of training data. In reality, however, there is insufficient data to even train the generative model for face synthesis. In this paper, we propose Differential Generative Adversarial Networks (D-GAN) that can perform photo-realistic face synthesis even when training data is small. Two discriminators are devised to ensure the generator to approximate a face manifold, which can express face changes as it wants. Experimental results demonstrate that the proposed method is robust to the amount of training data and synthesized images are useful to improve the performance of a face expression classifier.