 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKira Radinsky
Leveraging Prototypical Representations for Mitigating Social Bias without Demographic Information
Mar 14, 2024
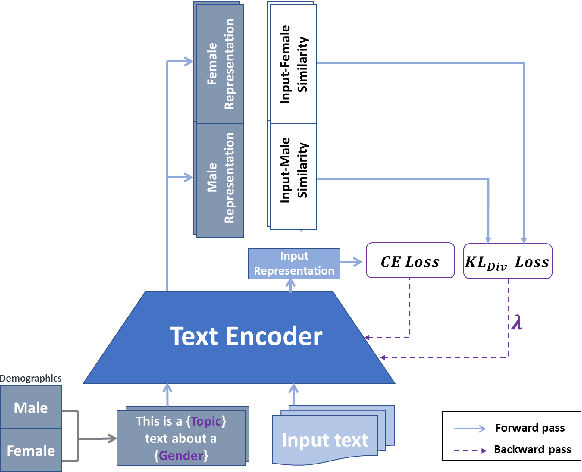
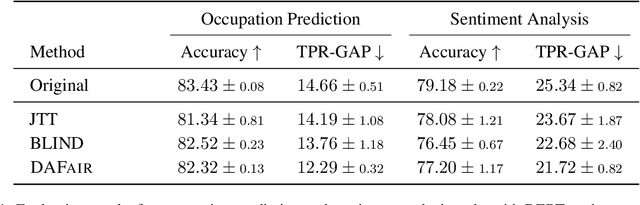

Mitigating social biases typically requires identifying the social groups associated with each data sample. In this paper, we present DAFair, a novel approach to address social bias in language models. Unlike traditional methods that rely on explicit demographic labels, our approach does not require any such information. Instead, we leverage predefined prototypical demographic texts and incorporate a regularization term during the fine-tuning process to mitigate bias in the model's representations. Our empirical results across two tasks and two models demonstrate the effectiveness of our method compared to previous approaches that do not rely on labeled data. Moreover, with limited demographic-annotated data, our approach outperforms common debiasing approaches.
Shielded Representations: Protecting Sensitive Attributes Through Iterative Gradient-Based Projection
May 17, 2023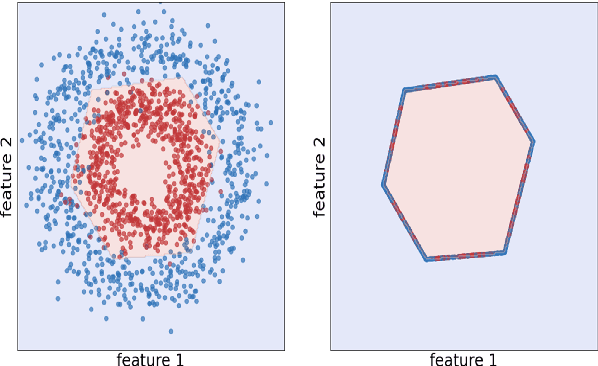
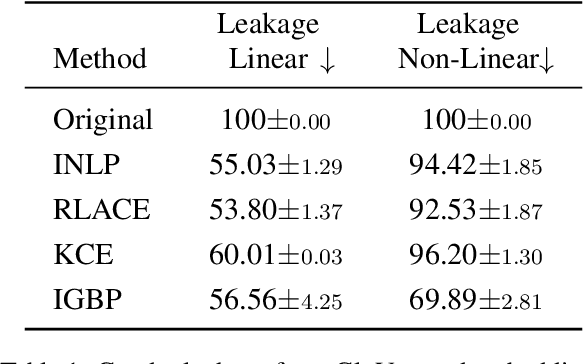
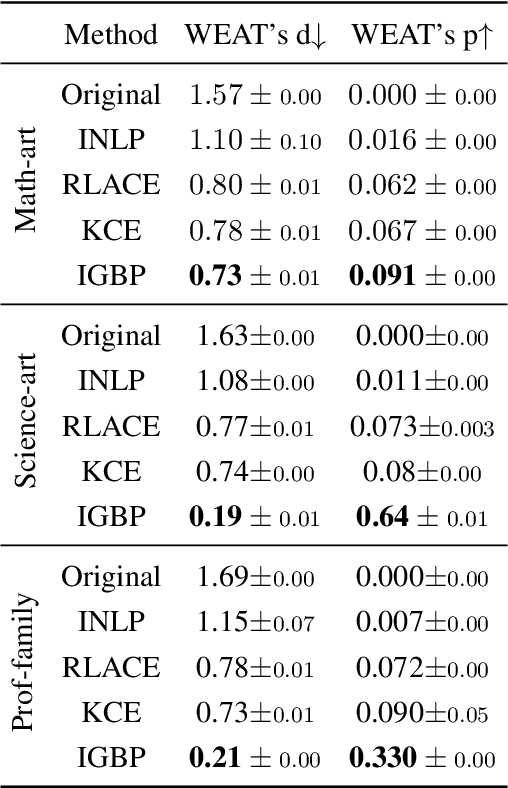
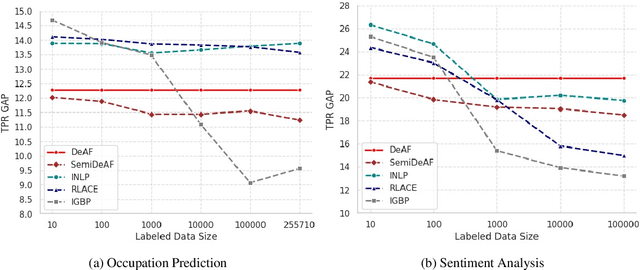
Natural language processing models tend to learn and encode social biases present in the data. One popular approach for addressing such biases is to eliminate encoded information from the model's representations. However, current methods are restricted to removing only linearly encoded information. In this work, we propose Iterative Gradient-Based Projection (IGBP), a novel method for removing non-linear encoded concepts from neural representations. Our method consists of iteratively training neural classifiers to predict a particular attribute we seek to eliminate, followed by a projection of the representation on a hypersurface, such that the classifiers become oblivious to the target attribute. We evaluate the effectiveness of our method on the task of removing gender and race information as sensitive attributes. Our results demonstrate that IGBP is effective in mitigating bias through intrinsic and extrinsic evaluations, with minimal impact on downstream task accuracy.
tBDFS: Temporal Graph Neural Network Leveraging DFS
Jun 12, 2022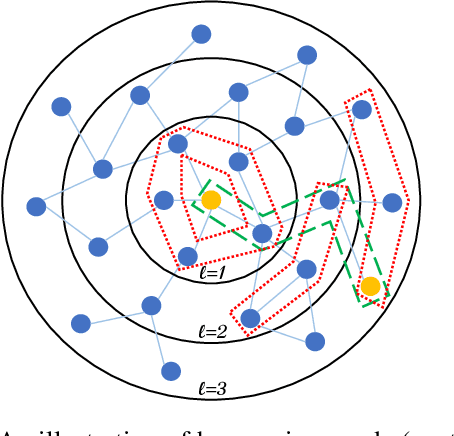
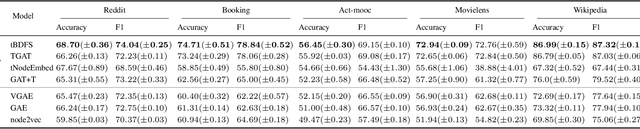

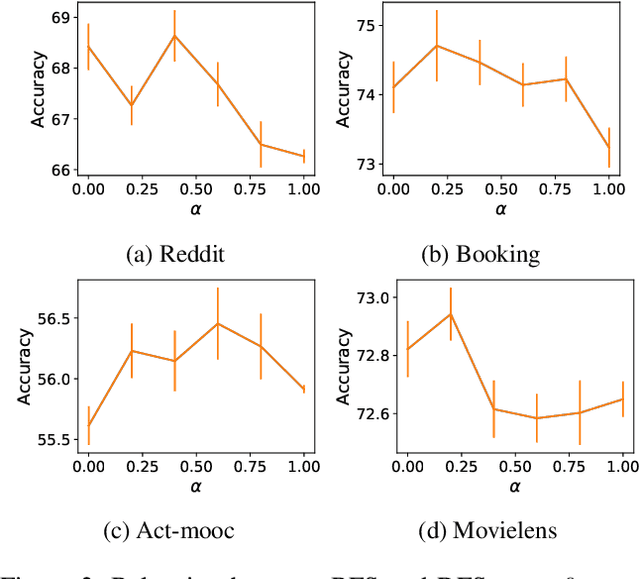
Temporal graph neural networks (temporal GNNs) have been widely researched, reaching state-of-the-art results on multiple prediction tasks. A common approach employed by most previous works is to apply a layer that aggregates information from the historical neighbors of a node. Taking a different research direction, in this work, we propose tBDFS -- a novel temporal GNN architecture. tBDFS applies a layer that efficiently aggregates information from temporal paths to a given (target) node in the graph. For each given node, the aggregation is applied in two stages: (1) A single representation is learned for each temporal path ending in that node, and (2) all path representations are aggregated into a final node representation. Overall, our goal is not to add new information to a node, but rather observe the same exact information in a new perspective. This allows our model to directly observe patterns that are path-oriented rather than neighborhood-oriented. This can be thought as a Depth-First Search (DFS) traversal over the temporal graph, compared to the popular Breath-First Search (BFS) traversal that is applied in previous works. We evaluate tBDFS over multiple link prediction tasks and show its favorable performance compared to state-of-the-art baselines. To the best of our knowledge, we are the first to apply a temporal-DFS neural network.
What If: Generating Code to Answer Simulation Questions
Apr 16, 2022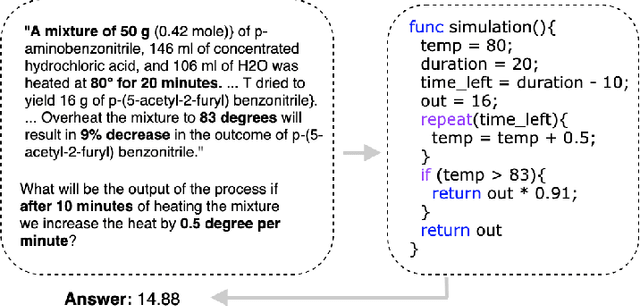
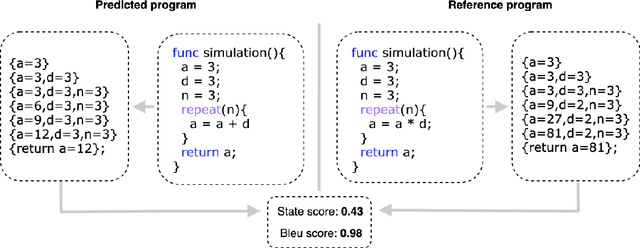
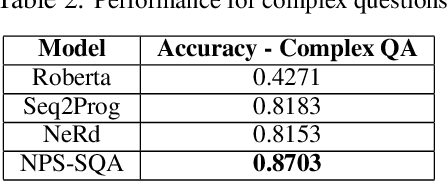
Many texts, especially in chemistry and biology, describe complex processes. We focus on texts that describe a chemical reaction process and questions that ask about the process's outcome under different environmental conditions. To answer questions about such processes, one needs to understand the interactions between the different entities involved in the process and to simulate their state transitions during the process execution under different conditions. A state transition is defined as the memory modification the program does to the variables during the execution. We hypothesize that generating code and executing it to simulate the process will allow answering such questions. We, therefore, define a domain-specific language (DSL) to represent processes. We contribute to the community a unique dataset curated by chemists and annotated by computer scientists. The dataset is composed of process texts, simulation questions, and their corresponding computer codes represented by the DSL.We propose a neural program synthesis approach based on reinforcement learning with a novel state-transition semantic reward. The novel reward is based on the run-time semantic similarity between the predicted code and the reference code. This allows simulating complex process transitions and thus answering simulation questions. Our approach yields a significant boost in accuracy for simulation questions: 88\% accuracy as opposed to 83\% accuracy of the state-of-the-art neural program synthesis approaches and 54\% accuracy of state-of-the-art end-to-end text-based approaches.
Temporal Attention for Language Models
Feb 04, 2022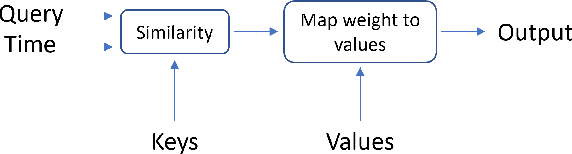

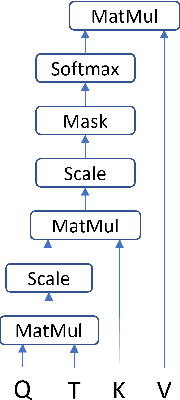
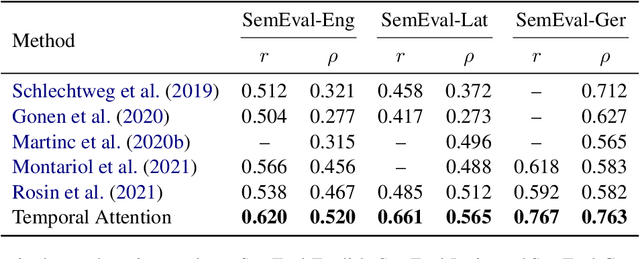
Pretrained language models based on the transformer architecture have shown great success in NLP. Textual training data often comes from the web and is thus tagged with time-specific information, but most language models ignore this information. They are trained on the textual data alone, limiting their ability to generalize temporally. In this work, we extend the key component of the transformer architecture, i.e., the self-attention mechanism, and propose temporal attention - a time-aware self-attention mechanism. Temporal attention can be applied to any transformer model and requires the input texts to be accompanied with their relevant time points. It allows the transformer to capture this temporal information and create time-specific contextualized word representations. We leverage these representations for the task of semantic change detection; we apply our proposed mechanism to BERT and experiment on three datasets in different languages (English, German, and Latin) that also vary in time, size, and genre. Our proposed model achieves state-of-the-art results on all the datasets.
Time Masking for Temporal Language Models
Oct 22, 2021

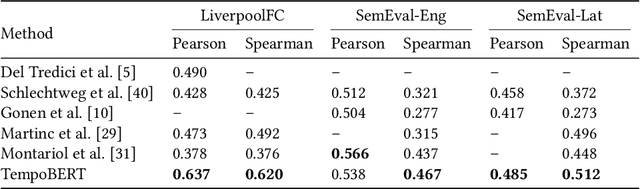
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
EqGNN: Equalized Node Opportunity in Graphs
Aug 19, 2021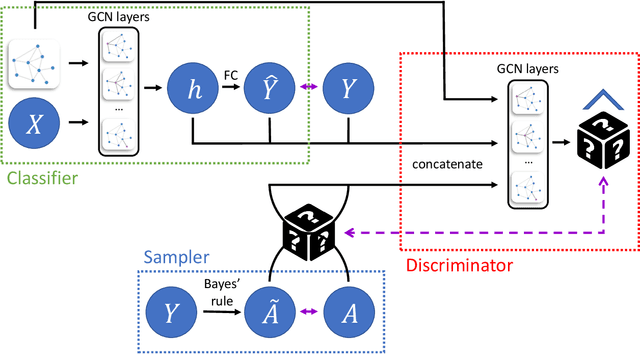
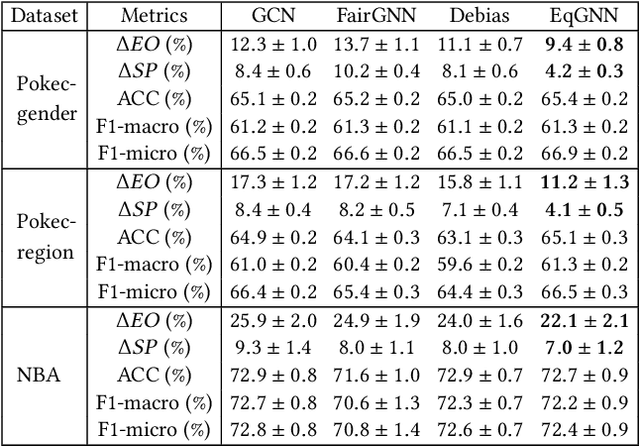
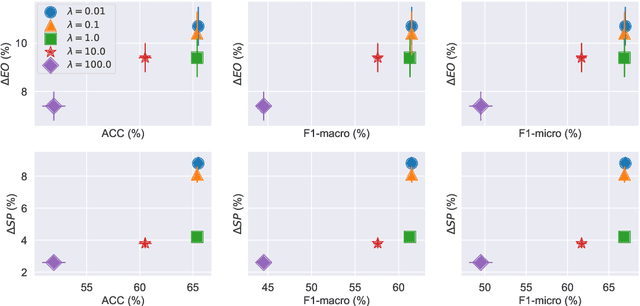
Graph neural networks (GNNs), has been widely used for supervised learning tasks in graphs reaching state-of-the-art results. However, little work was dedicated to creating unbiased GNNs, i.e., where the classification is uncorrelated with sensitive attributes, such as race or gender. Some ignore the sensitive attributes or optimize for the criteria of statistical parity for fairness. However, it has been shown that neither approaches ensure fairness, but rather cripple the utility of the prediction task. In this work, we present a GNN framework that allows optimizing representations for the notion of Equalized Odds fairness criteria. The architecture is composed of three components: (1) a GNN classifier predicting the utility class, (2) a sampler learning the distribution of the sensitive attributes of the nodes given their labels. It generates samples fed into a (3) discriminator that discriminates between true and sampled sensitive attributes using a novel "permutation loss" function. Using these components, we train a model to neglect information regarding the sensitive attribute only with respect to its label. To the best of our knowledge, we are the first to optimize GNNs for the equalized odds criteria. We evaluate our classifier over several graph datasets and sensitive attributes and show our algorithm reaches state-of-the-art results.
Event-Driven Query Expansion
Dec 22, 2020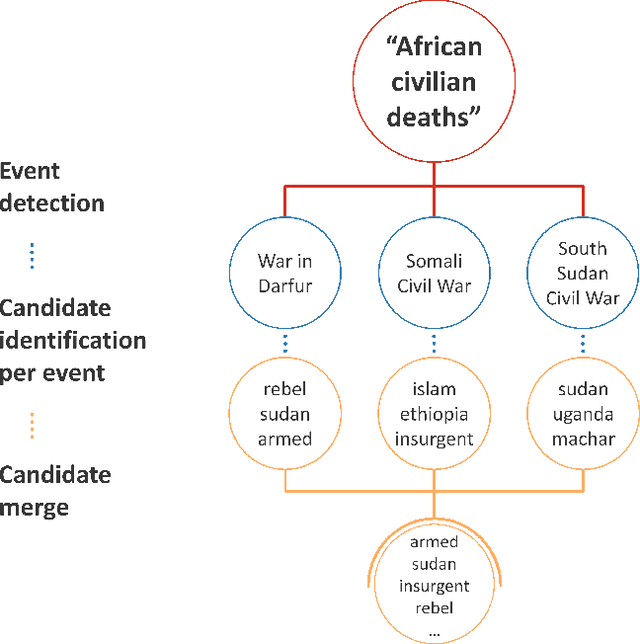
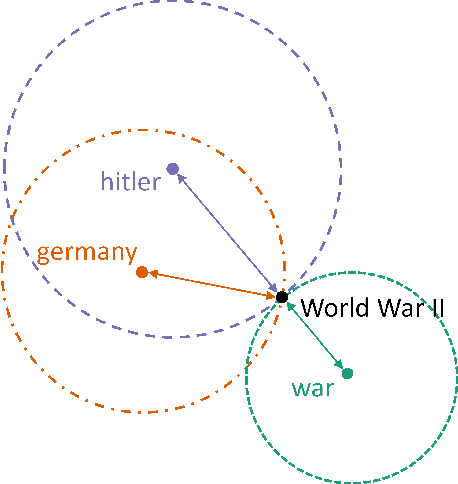
A significant number of event-related queries are issued in Web search. In this paper, we seek to improve retrieval performance by leveraging events and specifically target the classic task of query expansion. We propose a method to expand an event-related query by first detecting the events related to it. Then, we derive the candidates for expansion as terms semantically related to both the query and the events. To identify the candidates, we utilize a novel mechanism to simultaneously embed words and events in the same vector space. We show that our proposed method of leveraging events improves query expansion performance significantly compared with state-of-the-art methods on various newswire TREC datasets.
SimGANs: Simulator-Based Generative Adversarial Networks for ECG Synthesis to Improve Deep ECG Classification
Jun 27, 2020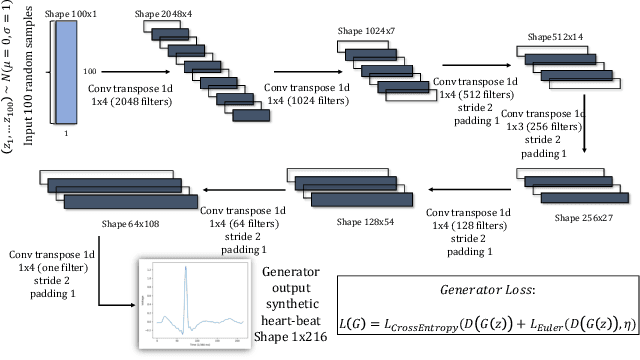

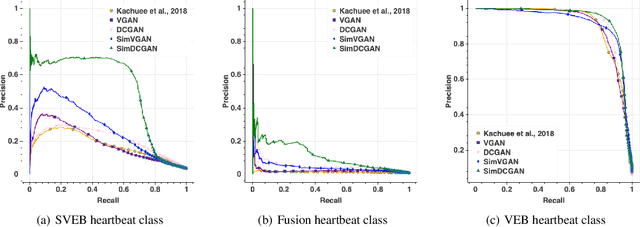

Generating training examples for supervised tasks is a long sought after goal in AI. We study the problem of heart signal electrocardiogram (ECG) synthesis for improved heartbeat classification. ECG synthesis is challenging: the generation of training examples for such biological-physiological systems is not straightforward, due to their dynamic nature in which the various parts of the system interact in complex ways. However, an understanding of these dynamics has been developed for years in the form of mathematical process simulators. We study how to incorporate this knowledge into the generative process by leveraging a biological simulator for the task of ECG classification. Specifically, we use a system of ordinary differential equations representing heart dynamics, and incorporate this ODE system into the optimization process of a generative adversarial network to create biologically plausible ECG training examples. We perform empirical evaluation and show that heart simulation knowledge during the generation process improves ECG classification.
Generating Timelines by Modeling Semantic Change
Sep 21, 2019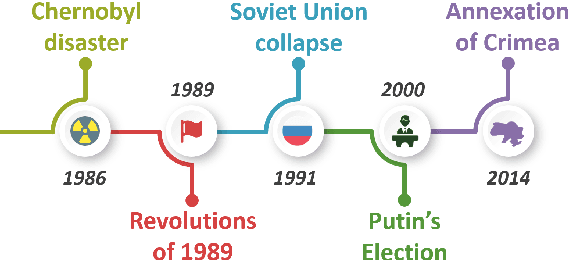
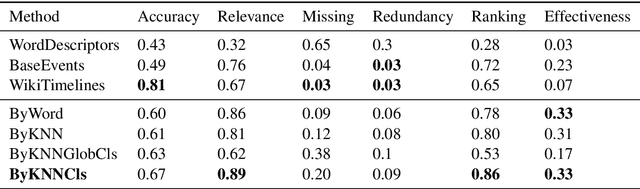
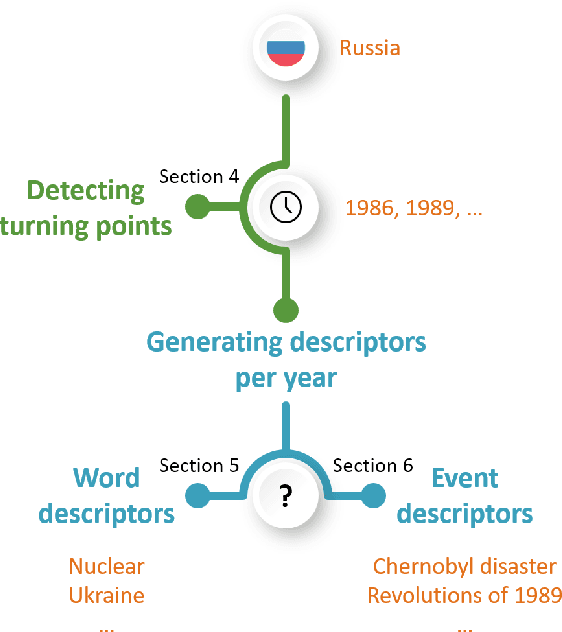
Though languages can evolve slowly, they can also react strongly to dramatic world events. By studying the connection between words and events, it is possible to identify which events change our vocabulary and in what way. In this work, we tackle the task of creating timelines - records of historical "turning points", represented by either words or events, to understand the dynamics of a target word. Our approach identifies these points by leveraging both static and time-varying word embeddings to measure the influence of words and events. In addition to quantifying changes, we show how our technique can help isolate semantic changes. Our qualitative and quantitative evaluations show that we are able to capture this semantic change and event influence.