 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiwoo Shin
Improving a Quality of 3D Object Detection by Spatial Transformation Mechanism
Sep 27, 2019
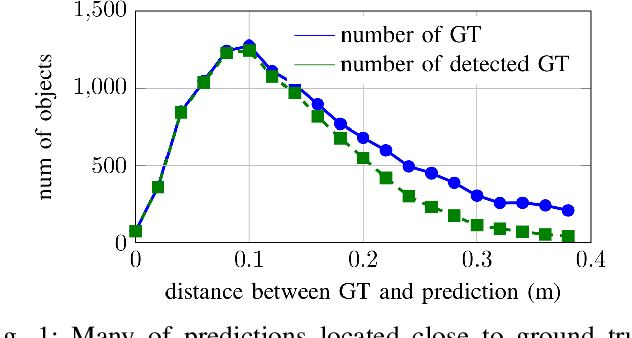
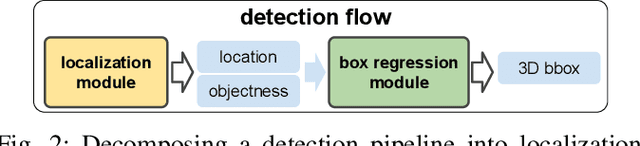

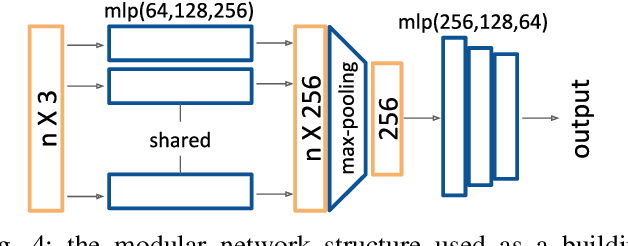
We present an endpoint box regression module(epBRM), which is designed for predicting precise 3D bounding boxes using raw LiDAR 3D point clouds. The proposed epBRM is built with sequence of small networks and is computationally lightweight. Our approach can improve a 3D object detection performance by predicting more precise 3D bounding box coordinates. The proposed approach requires 40 minutes of training to improve the detection performance. Moreover, epBRM imposes less than 12ms to network inference time for up-to 20 objects. The proposed approach utilizes a spatial transformation mechanism to simplify the box regression task. Adopting spatial transformation mechanism into epBRM makes it possible to improve the quality of detection with a small sized network. We conduct in-depth analysis of the effect of various spatial transformation mechanisms applied on raw LiDAR 3D point clouds. We also evaluate the proposed epBRM by applying it to several state-of-the-art 3D object detection systems. We evaluate our approach on KITTI dataset, a standard 3D object detection benchmark for autonomous vehicles. The proposed epBRM enhances the overlaps between ground truth bounding boxes and detected bounding boxes, and improves 3D object detection. Our proposed method evaluated in KITTI test server outperforms current state-of-the-art approaches.
RoarNet: A Robust 3D Object Detection based on RegiOn Approximation Refinement
Nov 09, 2018
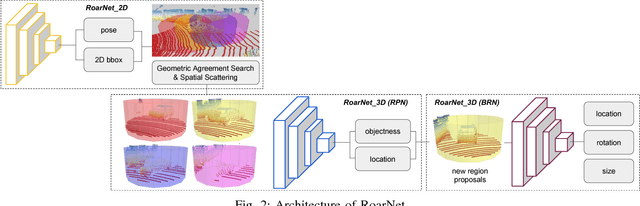
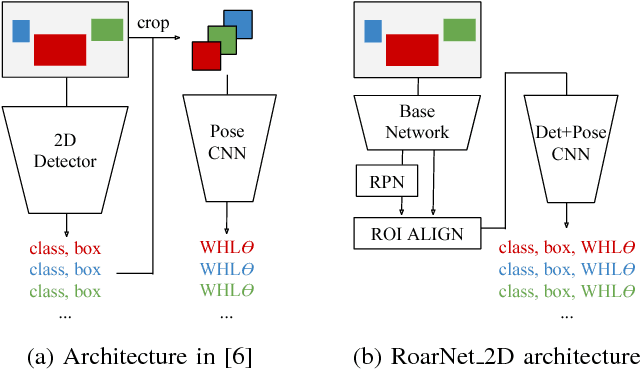
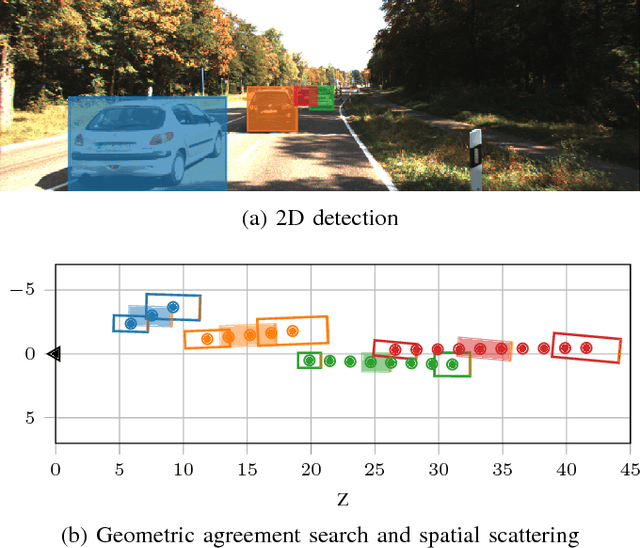
We present RoarNet, a new approach for 3D object detection from a 2D image and 3D Lidar point clouds. Based on two-stage object detection framework with PointNet as our backbone network, we suggest several novel ideas to improve 3D object detection performance. The first part of our method, RoarNet_2D, estimates the 3D poses of objects from a monocular image, which approximates where to examine further, and derives multiple candidates that are geometrically feasible. This step significantly narrows down feasible 3D regions, which otherwise requires demanding processing of 3D point clouds in a huge search space. Then the second part, RoarNet_3D, takes the candidate regions and conducts in-depth inferences to conclude final poses in a recursive manner. Inspired by PointNet, RoarNet_3D processes 3D point clouds directly without any loss of data, leading to precise detection. We evaluate our method in KITTI, a 3D object detection benchmark. Our result shows that RoarNet has superior performance to state-of-the-art methods that are publicly available. Remarkably, RoarNet also outperforms state-of-the-art methods even in settings where Lidar and camera are not time synchronized, which is practically important for actual driving environments. RoarNet is implemented in Tensorflow and publicly available with pre-trained models.