 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoichi Miyazaki
Structured State Space Decoder for Speech Recognition and Synthesis
Oct 31, 2022




Automatic speech recognition (ASR) systems developed in recent years have shown promising results with self-attention models (e.g., Transformer and Conformer), which are replacing conventional recurrent neural networks. Meanwhile, a structured state space model (S4) has been recently proposed, producing promising results for various long-sequence modeling tasks, including raw speech classification. The S4 model can be trained in parallel, same as the Transformer model. In this study, we applied S4 as a decoder for ASR and text-to-speech (TTS) tasks by comparing it with the Transformer decoder. For the ASR task, our experimental results demonstrate that the proposed model achieves a competitive word error rate (WER) of 1.88%/4.25% on LibriSpeech test-clean/test-other set and a character error rate (CER) of 3.80%/2.63%/2.98% on the CSJ eval1/eval2/eval3 set. Furthermore, the proposed model is more robust than the standard Transformer model, particularly for long-form speech on both the datasets. For the TTS task, the proposed method outperforms the Transformer baseline.
Acoustic Event Detection with Classifier Chains
Feb 17, 2022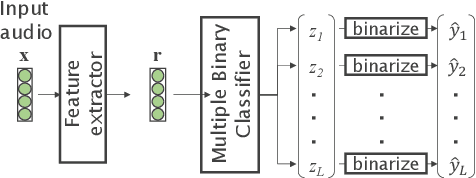

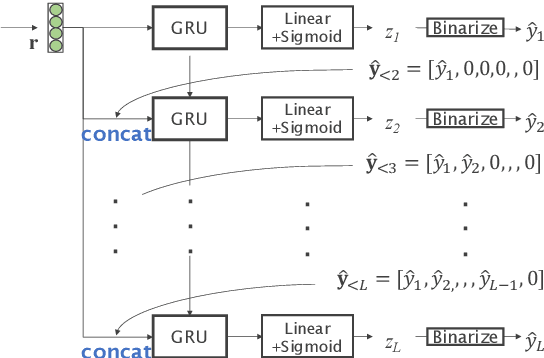
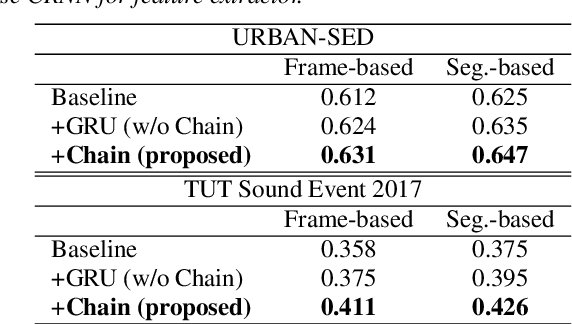
This paper proposes acoustic event detection (AED) with classifier chains, a new classifier based on the probabilistic chain rule. The proposed AED with classifier chains consists of a gated recurrent unit and performs iterative binary detection of each event one by one. In each iteration, the event's activity is estimated and used to condition the next output based on the probabilistic chain rule to form classifier chains. Therefore, the proposed method can handle the interdependence among events upon classification, while the conventional AED methods with multiple binary classifiers with a linear layer and sigmoid function have placed an assumption of conditional independence. In the experiments with a real-recording dataset, the proposed method demonstrates its superior AED performance to a relative 14.80% improvement compared to a convolutional recurrent neural network baseline system with the multiple binary classifiers.