 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoichiro Niinuma
CoGS: Controllable Gaussian Splatting
Dec 09, 2023
Capturing and re-animating the 3D structure of articulated objects present significant barriers. On one hand, methods requiring extensively calibrated multi-view setups are prohibitively complex and resource-intensive, limiting their practical applicability. On the other hand, while single-camera Neural Radiance Fields (NeRFs) offer a more streamlined approach, they have excessive training and rendering costs. 3D Gaussian Splatting would be a suitable alternative but for two reasons. Firstly, existing methods for 3D dynamic Gaussians require synchronized multi-view cameras, and secondly, the lack of controllability in dynamic scenarios. We present CoGS, a method for Controllable Gaussian Splatting, that enables the direct manipulation of scene elements, offering real-time control of dynamic scenes without the prerequisite of pre-computing control signals. We evaluated CoGS using both synthetic and real-world datasets that include dynamic objects that differ in degree of difficulty. In our evaluations, CoGS consistently outperformed existing dynamic and controllable neural representations in terms of visual fidelity.
Zero-Shot Video Question Answering with Procedural Programs
Dec 01, 2023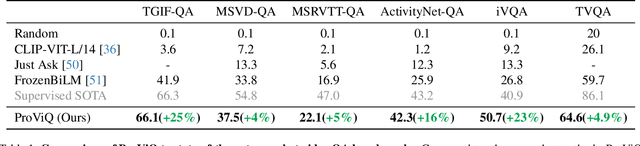
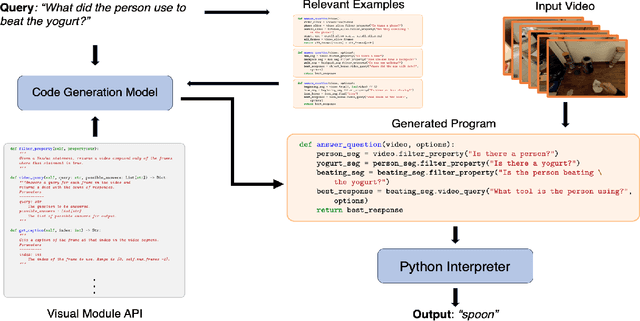
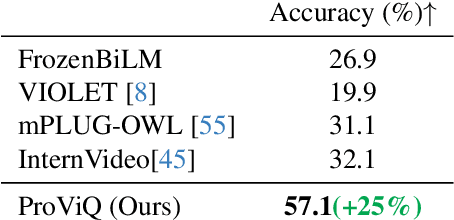
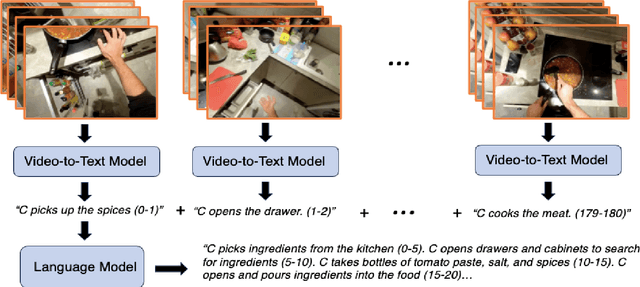
We propose to answer zero-shot questions about videos by generating short procedural programs that derive a final answer from solving a sequence of visual subtasks. We present Procedural Video Querying (ProViQ), which uses a large language model to generate such programs from an input question and an API of visual modules in the prompt, then executes them to obtain the output. Recent similar procedural approaches have proven successful for image question answering, but videos remain challenging: we provide ProViQ with modules intended for video understanding, allowing it to generalize to a wide variety of videos. This code generation framework additionally enables ProViQ to perform other video tasks in addition to question answering, such as multi-object tracking or basic video editing. ProViQ achieves state-of-the-art results on a diverse range of benchmarks, with improvements of up to 25% on short, long, open-ended, and multimodal video question-answering datasets. Our project page is at https://rccchoudhury.github.io/proviq2023.
Occlusion Sensitivity Analysis with Augmentation Subspace Perturbation in Deep Feature Space
Nov 25, 2023Deep Learning of neural networks has gained prominence in multiple life-critical applications like medical diagnoses and autonomous vehicle accident investigations. However, concerns about model transparency and biases persist. Explainable methods are viewed as the solution to address these challenges. In this study, we introduce the Occlusion Sensitivity Analysis with Deep Feature Augmentation Subspace (OSA-DAS), a novel perturbation-based interpretability approach for computer vision. While traditional perturbation methods make only use of occlusions to explain the model predictions, OSA-DAS extends standard occlusion sensitivity analysis by enabling the integration with diverse image augmentations. Distinctly, our method utilizes the output vector of a DNN to build low-dimensional subspaces within the deep feature vector space, offering a more precise explanation of the model prediction. The structural similarity between these subspaces encompasses the influence of diverse augmentations and occlusions. We test extensively on the ImageNet-1k, and our class- and model-agnostic approach outperforms commonly used interpreters, setting it apart in the realm of explainable AI.
DyLiN: Making Light Field Networks Dynamic
Mar 24, 2023



Light Field Networks, the re-formulations of radiance fields to oriented rays, are magnitudes faster than their coordinate network counterparts, and provide higher fidelity with respect to representing 3D structures from 2D observations. They would be well suited for generic scene representation and manipulation, but suffer from one problem: they are limited to holistic and static scenes. In this paper, we propose the Dynamic Light Field Network (DyLiN) method that can handle non-rigid deformations, including topological changes. We learn a deformation field from input rays to canonical rays, and lift them into a higher dimensional space to handle discontinuities. We further introduce CoDyLiN, which augments DyLiN with controllable attribute inputs. We train both models via knowledge distillation from pretrained dynamic radiance fields. We evaluated DyLiN using both synthetic and real world datasets that include various non-rigid deformations. DyLiN qualitatively outperformed and quantitatively matched state-of-the-art methods in terms of visual fidelity, while being 25 - 71x computationally faster. We also tested CoDyLiN on attribute annotated data and it surpassed its teacher model. Project page: https://dylin2023.github.io .
CoNFies: Controllable Neural Face Avatars
Nov 16, 2022



Neural Radiance Fields (NeRF) are compelling techniques for modeling dynamic 3D scenes from 2D image collections. These volumetric representations would be well suited for synthesizing novel facial expressions but for two problems. First, deformable NeRFs are object agnostic and model holistic movement of the scene: they can replay how the motion changes over time, but they cannot alter it in an interpretable way. Second, controllable volumetric representations typically require either time-consuming manual annotations or 3D supervision to provide semantic meaning to the scene. We propose a controllable neural representation for face self-portraits (CoNFies), that solves both of these problems within a common framework, and it can rely on automated processing. We use automated facial action recognition (AFAR) to characterize facial expressions as a combination of action units (AU) and their intensities. AUs provide both the semantic locations and control labels for the system. CoNFies outperformed competing methods for novel view and expression synthesis in terms of visual and anatomic fidelity of expressions.
Visually explaining 3D-CNN predictions for video classification with an adaptive occlusion sensitivity analysis
Jul 26, 2022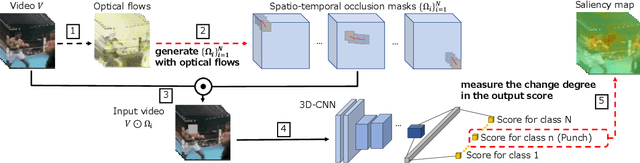
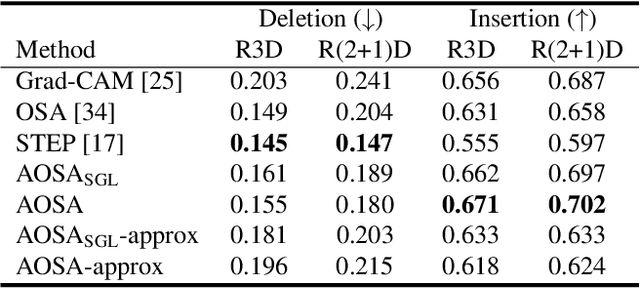
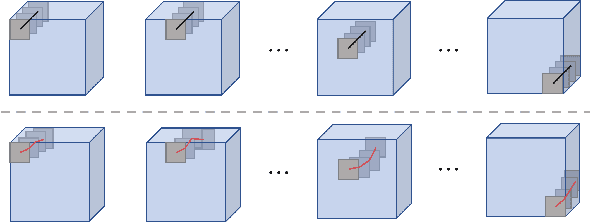
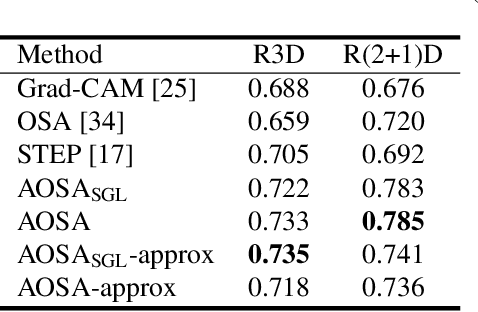
This paper proposes a method for visually explaining the decision-making process of 3D convolutional neural networks (CNN) with a temporal extension of occlusion sensitivity analysis. The key idea here is to occlude a specific volume of data by a 3D mask in an input 3D temporal-spatial data space and then measure the change degree in the output score. The occluded volume data that produces a larger change degree is regarded as a more critical element for classification. However, while the occlusion sensitivity analysis is commonly used to analyze single image classification, it is not so straightforward to apply this idea to video classification as a simple fixed cuboid cannot deal with the motions. To this end, we adapt the shape of a 3D occlusion mask to complicated motions of target objects. Our flexible mask adaptation is performed by considering the temporal continuity and spatial co-occurrence of the optical flows extracted from the input video data. We further propose to approximate our method by using the first-order partial derivative of the score with respect to an input image to reduce its computational cost. We demonstrate the effectiveness of our method through various and extensive comparisons with the conventional methods in terms of the deletion/insertion metric and the pointing metric on the UCF-101. The code is available at: https://github.com/uchiyama33/AOSA.
Synthetic Expressions are Better Than Real for Learning to Detect Facial Actions
Oct 21, 2020



Critical obstacles in training classifiers to detect facial actions are the limited sizes of annotated video databases and the relatively low frequencies of occurrence of many actions. To address these problems, we propose an approach that makes use of facial expression generation. Our approach reconstructs the 3D shape of the face from each video frame, aligns the 3D mesh to a canonical view, and then trains a GAN-based network to synthesize novel images with facial action units of interest. To evaluate this approach, a deep neural network was trained on two separate datasets: One network was trained on video of synthesized facial expressions generated from FERA17; the other network was trained on unaltered video from the same database. Both networks used the same train and validation partitions and were tested on the test partition of actual video from FERA17. The network trained on synthesized facial expressions outperformed the one trained on actual facial expressions and surpassed current state-of-the-art approaches.