 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrishnakumar Balasubramanian
Minimax Optimal Goodness-of-Fit Testing with Kernel Stein Discrepancy
Apr 12, 2024
We explore the minimax optimality of goodness-of-fit tests on general domains using the kernelized Stein discrepancy (KSD). The KSD framework offers a flexible approach for goodness-of-fit testing, avoiding strong distributional assumptions, accommodating diverse data structures beyond Euclidean spaces, and relying only on partial knowledge of the reference distribution, while maintaining computational efficiency. We establish a general framework and an operator-theoretic representation of the KSD, encompassing many existing KSD tests in the literature, which vary depending on the domain. We reveal the characteristics and limitations of KSD and demonstrate its non-optimality under a certain alternative space, defined over general domains when considering $\chi^2$-divergence as the separation metric. To address this issue of non-optimality, we propose a modified, minimax optimal test by incorporating a spectral regularizer, thereby overcoming the shortcomings of standard KSD tests. Our results are established under a weak moment condition on the Stein kernel, which relaxes the bounded kernel assumption required by prior work in the analysis of kernel-based hypothesis testing. Additionally, we introduce an adaptive test capable of achieving minimax optimality up to a logarithmic factor by adapting to unknown parameters. Through numerical experiments, we illustrate the superior performance of our proposed tests across various domains compared to their unregularized counterparts.
Meta-Learning with Generalized Ridge Regression: High-dimensional Asymptotics, Optimality and Hyper-covariance Estimation
Mar 27, 2024

Meta-learning involves training models on a variety of training tasks in a way that enables them to generalize well on new, unseen test tasks. In this work, we consider meta-learning within the framework of high-dimensional multivariate random-effects linear models and study generalized ridge-regression based predictions. The statistical intuition of using generalized ridge regression in this setting is that the covariance structure of the random regression coefficients could be leveraged to make better predictions on new tasks. Accordingly, we first characterize the precise asymptotic behavior of the predictive risk for a new test task when the data dimension grows proportionally to the number of samples per task. We next show that this predictive risk is optimal when the weight matrix in generalized ridge regression is chosen to be the inverse of the covariance matrix of random coefficients. Finally, we propose and analyze an estimator of the inverse covariance matrix of random regression coefficients based on data from the training tasks. As opposed to intractable MLE-type estimators, the proposed estimators could be computed efficiently as they could be obtained by solving (global) geodesically-convex optimization problems. Our analysis and methodology use tools from random matrix theory and Riemannian optimization. Simulation results demonstrate the improved generalization performance of the proposed method on new unseen test tasks within the considered framework.
Multivariate Gaussian Approximation for Random Forest via Region-based Stabilization
Mar 26, 2024
We derive Gaussian approximation bounds for random forest predictions based on a set of training points given by a Poisson process, under fairly mild regularity assumptions on the data generating process. Our approach is based on the key observation that the random forest predictions satisfy a certain geometric property called region-based stabilization. In the process of developing our results for the random forest, we also establish a probabilistic result, which might be of independent interest, on multivariate Gaussian approximation bounds for general functionals of Poisson process that are region-based stabilizing. This general result makes use of the Malliavin-Stein method, and is potentially applicable to various related statistical problems.
Nonsmooth Nonparametric Regression via Fractional Laplacian Eigenmaps
Feb 22, 2024We develop nonparametric regression methods for the case when the true regression function is not necessarily smooth. More specifically, our approach is using the fractional Laplacian and is designed to handle the case when the true regression function lies in an $L_2$-fractional Sobolev space with order $s\in (0,1)$. This function class is a Hilbert space lying between the space of square-integrable functions and the first-order Sobolev space consisting of differentiable functions. It contains fractional power functions, piecewise constant or polynomial functions and bump function as canonical examples. For the proposed approach, we prove upper bounds on the in-sample mean-squared estimation error of order $n^{-\frac{2s}{2s+d}}$, where $d$ is the dimension, $s$ is the aforementioned order parameter and $n$ is the number of observations. We also provide preliminary empirical results validating the practical performance of the developed estimators.
Adaptive and non-adaptive minimax rates for weighted Laplacian-eigenmap based nonparametric regression
Oct 31, 2023We show both adaptive and non-adaptive minimax rates of convergence for a family of weighted Laplacian-Eigenmap based nonparametric regression methods, when the true regression function belongs to a Sobolev space and the sampling density is bounded from above and below. The adaptation methodology is based on extensions of Lepski's method and is over both the smoothness parameter ($s\in\mathbb{N}_{+}$) and the norm parameter ($M>0$) determining the constraints on the Sobolev space. Our results extend the non-adaptive result in \cite{green2021minimax}, established for a specific normalized graph Laplacian, to a wide class of weighted Laplacian matrices used in practice, including the unnormalized Laplacian and random walk Laplacian.
From Stability to Chaos: Analyzing Gradient Descent Dynamics in Quadratic Regression
Oct 02, 2023
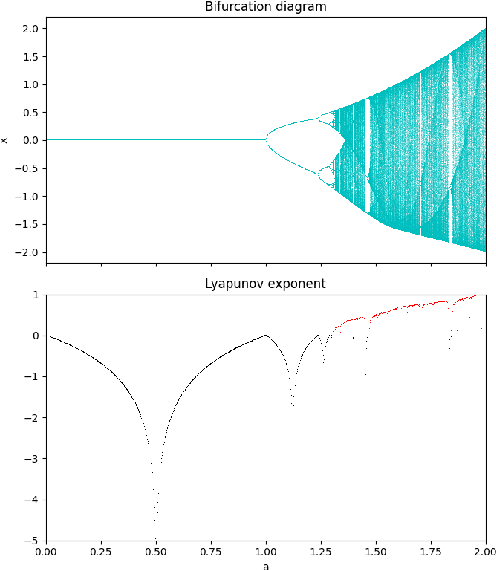
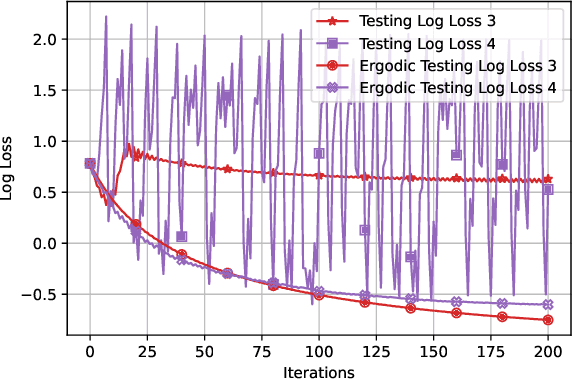
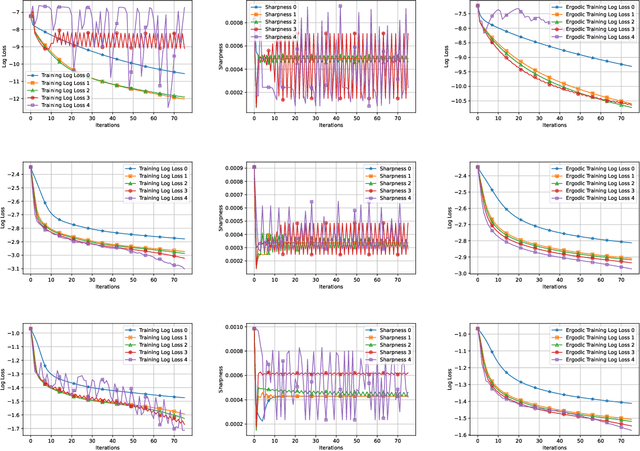
We conduct a comprehensive investigation into the dynamics of gradient descent using large-order constant step-sizes in the context of quadratic regression models. Within this framework, we reveal that the dynamics can be encapsulated by a specific cubic map, naturally parameterized by the step-size. Through a fine-grained bifurcation analysis concerning the step-size parameter, we delineate five distinct training phases: (1) monotonic, (2) catapult, (3) periodic, (4) chaotic, and (5) divergent, precisely demarcating the boundaries of each phase. As illustrations, we provide examples involving phase retrieval and two-layer neural networks employing quadratic activation functions and constant outer-layers, utilizing orthogonal training data. Our simulations indicate that these five phases also manifest with generic non-orthogonal data. We also empirically investigate the generalization performance when training in the various non-monotonic (and non-divergent) phases. In particular, we observe that performing an ergodic trajectory averaging stabilizes the test error in non-monotonic (and non-divergent) phases.
Zeroth-order Riemannian Averaging Stochastic Approximation Algorithms
Sep 25, 2023We present Zeroth-order Riemannian Averaging Stochastic Approximation (\texttt{Zo-RASA}) algorithms for stochastic optimization on Riemannian manifolds. We show that \texttt{Zo-RASA} achieves optimal sample complexities for generating $\epsilon$-approximation first-order stationary solutions using only one-sample or constant-order batches in each iteration. Our approach employs Riemannian moving-average stochastic gradient estimators, and a novel Riemannian-Lyapunov analysis technique for convergence analysis. We improve the algorithm's practicality by using retractions and vector transport, instead of exponential mappings and parallel transports, thereby reducing per-iteration complexity. Additionally, we introduce a novel geometric condition, satisfied by manifolds with bounded second fundamental form, which enables new error bounds for approximating parallel transport with vector transport.
Online covariance estimation for stochastic gradient descent under Markovian sampling
Aug 03, 2023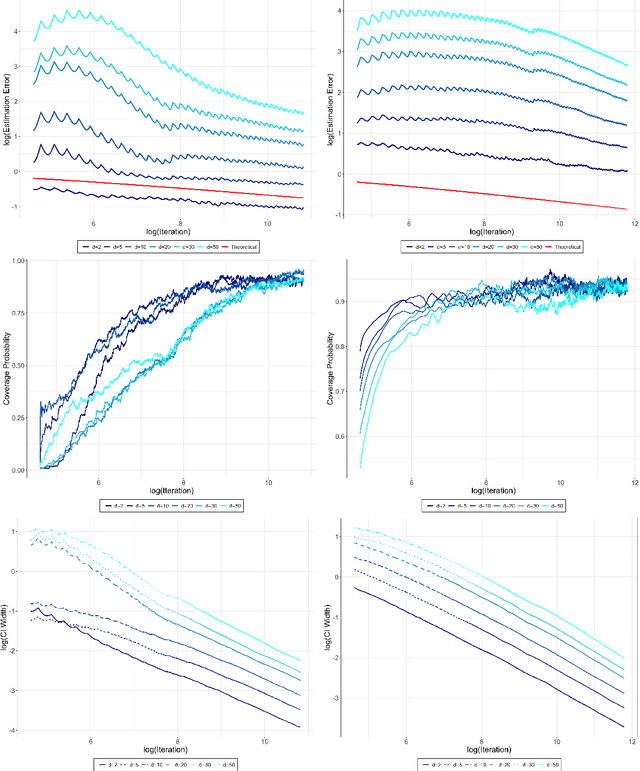
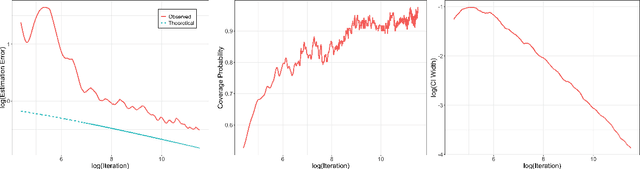
We study the online overlapping batch-means covariance estimator for Stochastic Gradient Descent (SGD) under Markovian sampling. We show that the convergence rates of the covariance estimator are $O\big(\sqrt{d}\,n^{-1/8}(\log n)^{1/4}\big)$ and $O\big(\sqrt{d}\,n^{-1/8}\big)$ under state-dependent and state-independent Markovian sampling, respectively, with $d$ representing dimensionality and $n$ denoting the number of observations or SGD iterations. Remarkably, these rates match the best-known convergence rate previously established for the independent and identically distributed ($\iid$) case by \cite{zhu2021online}, up to logarithmic factors. Our analysis overcomes significant challenges that arise due to Markovian sampling, leading to the introduction of additional error terms and complex dependencies between the blocks of the batch-means covariance estimator. Moreover, we establish the convergence rate for the first four moments of the $\ell_2$ norm of the error of SGD dynamics under state-dependent Markovian data, which holds potential interest as an independent result. To validate our theoretical findings, we provide numerical illustrations to derive confidence intervals for SGD when training linear and logistic regression models under Markovian sampling. Additionally, we apply our approach to tackle the intriguing problem of strategic classification with logistic regression, where adversaries can adaptively modify features during the training process to increase their chances of being classified in a specific target class.
Stochastic Nested Compositional Bi-level Optimization for Robust Feature Learning
Jul 11, 2023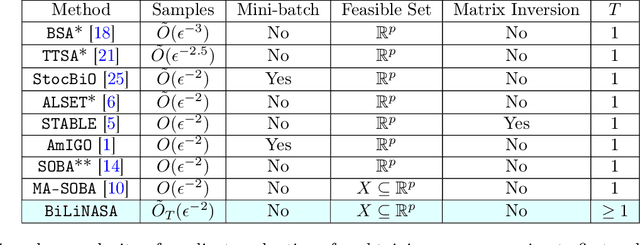
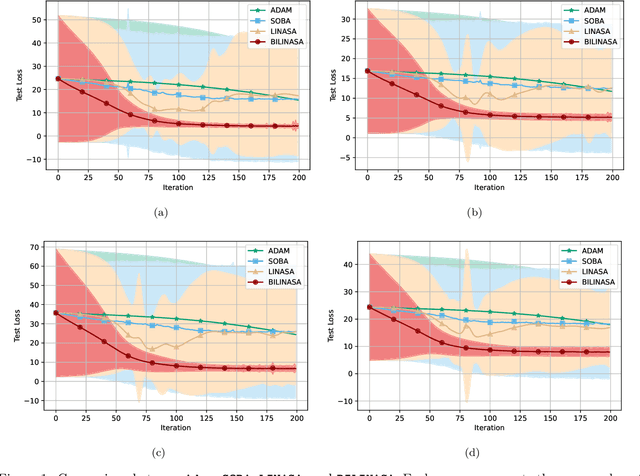
We develop and analyze stochastic approximation algorithms for solving nested compositional bi-level optimization problems. These problems involve a nested composition of $T$ potentially non-convex smooth functions in the upper-level, and a smooth and strongly convex function in the lower-level. Our proposed algorithm does not rely on matrix inversions or mini-batches and can achieve an $\epsilon$-stationary solution with an oracle complexity of approximately $\tilde{O}_T(1/\epsilon^{2})$, assuming the availability of stochastic first-order oracles for the individual functions in the composition and the lower-level, which are unbiased and have bounded moments. Here, $\tilde{O}_T$ hides polylog factors and constants that depend on $T$. The key challenge we address in establishing this result relates to handling three distinct sources of bias in the stochastic gradients. The first source arises from the compositional nature of the upper-level, the second stems from the bi-level structure, and the third emerges due to the utilization of Neumann series approximations to avoid matrix inversion. To demonstrate the effectiveness of our approach, we apply it to the problem of robust feature learning for deep neural networks under covariate shift, showcasing the benefits and advantages of our methodology in that context.
Gaussian random field approximation via Stein's method with applications to wide random neural networks
Jun 28, 2023
We derive upper bounds on the Wasserstein distance ($W_1$), with respect to $\sup$-norm, between any continuous $\mathbb{R}^d$ valued random field indexed by the $n$-sphere and the Gaussian, based on Stein's method. We develop a novel Gaussian smoothing technique that allows us to transfer a bound in a smoother metric to the $W_1$ distance. The smoothing is based on covariance functions constructed using powers of Laplacian operators, designed so that the associated Gaussian process has a tractable Cameron-Martin or Reproducing Kernel Hilbert Space. This feature enables us to move beyond one dimensional interval-based index sets that were previously considered in the literature. Specializing our general result, we obtain the first bounds on the Gaussian random field approximation of wide random neural networks of any depth and Lipschitz activation functions at the random field level. Our bounds are explicitly expressed in terms of the widths of the network and moments of the random weights. We also obtain tighter bounds when the activation function has three bounded derivatives.