 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunal Chelani
Privacy-Preserving Representations are not Enough -- Recovering Scene Content from Camera Poses
May 08, 2023



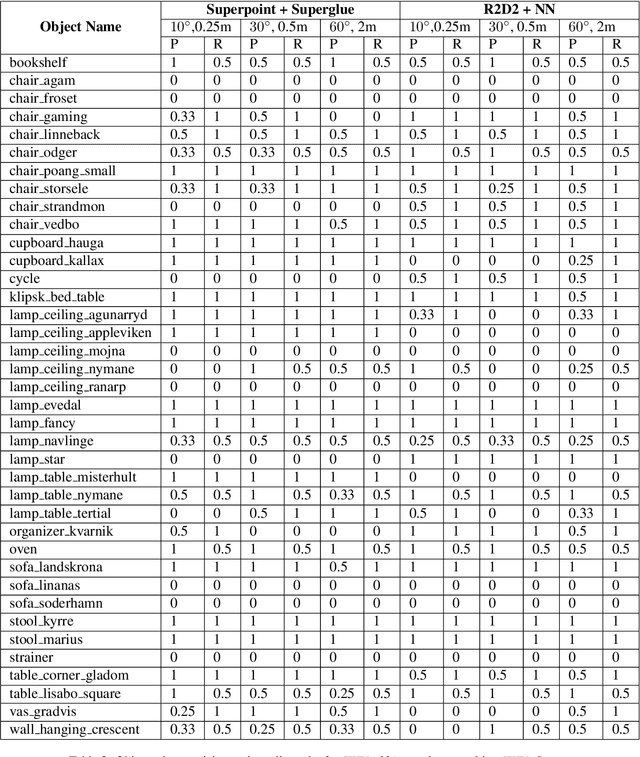
Visual localization is the task of estimating the camera pose from which a given image was taken and is central to several 3D computer vision applications. With the rapid growth in the popularity of AR/VR/MR devices and cloud-based applications, privacy issues are becoming a very important aspect of the localization process. Existing work on privacy-preserving localization aims to defend against an attacker who has access to a cloud-based service. In this paper, we show that an attacker can learn about details of a scene without any access by simply querying a localization service. The attack is based on the observation that modern visual localization algorithms are robust to variations in appearance and geometry. While this is in general a desired property, it also leads to algorithms localizing objects that are similar enough to those present in a scene. An attacker can thus query a server with a large enough set of images of objects, \eg, obtained from the Internet, and some of them will be localized. The attacker can thus learn about object placements from the camera poses returned by the service (which is the minimal information returned by such a service). In this paper, we develop a proof-of-concept version of this attack and demonstrate its practical feasibility. The attack does not place any requirements on the localization algorithm used, and thus also applies to privacy-preserving representations. Current work on privacy-preserving representations alone is thus insufficient.
How Privacy-Preserving are Line Clouds? Recovering Scene Details from 3D Lines
Mar 08, 2021


Visual localization is the problem of estimating the camera pose of a given image with respect to a known scene. Visual localization algorithms are a fundamental building block in advanced computer vision applications, including Mixed and Virtual Reality systems. Many algorithms used in practice represent the scene through a Structure-from-Motion (SfM) point cloud and use 2D-3D matches between a query image and the 3D points for camera pose estimation. As recently shown, image details can be accurately recovered from SfM point clouds by translating renderings of the sparse point clouds to images. To address the resulting potential privacy risks for user-generated content, it was recently proposed to lift point clouds to line clouds by replacing 3D points by randomly oriented 3D lines passing through these points. The resulting representation is unintelligible to humans and effectively prevents point cloud-to-image translation. This paper shows that a significant amount of information about the 3D scene geometry is preserved in these line clouds, allowing us to (approximately) recover the 3D point positions and thus to (approximately) recover image content. Our approach is based on the observation that the closest points between lines can yield a good approximation to the original 3D points. Code is available at https://github.com/kunalchelani/Line2Point.
LiDAR-Camera Calibration using 3D-3D Point correspondences
May 27, 2017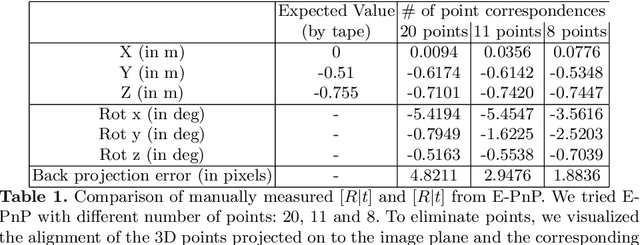

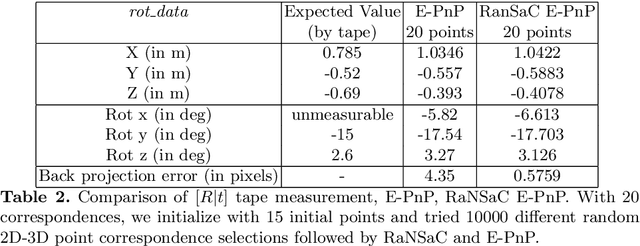
With the advent of autonomous vehicles, LiDAR and cameras have become an indispensable combination of sensors. They both provide rich and complementary data which can be used by various algorithms and machine learning to sense and make vital inferences about the surroundings. We propose a novel pipeline and experimental setup to find accurate rigid-body transformation for extrinsically calibrating a LiDAR and a camera. The pipeling uses 3D-3D point correspondences in LiDAR and camera frame and gives a closed form solution. We further show the accuracy of the estimate by fusing point clouds from two stereo cameras which align perfectly with the rotation and translation estimated by our method, confirming the accuracy of our method's estimates both mathematically and visually. Taking our idea of extrinsic LiDAR-camera calibration forward, we demonstrate how two cameras with no overlapping field-of-view can also be calibrated extrinsically using 3D point correspondences. The code has been made available as open-source software in the form of a ROS package, more information about which can be sought here: https://github.com/ankitdhall/lidar_camera_calibration .