 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKurt Partridge
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022


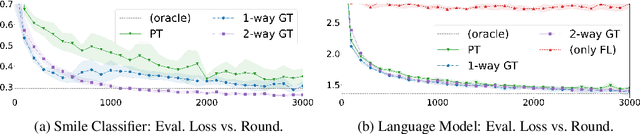
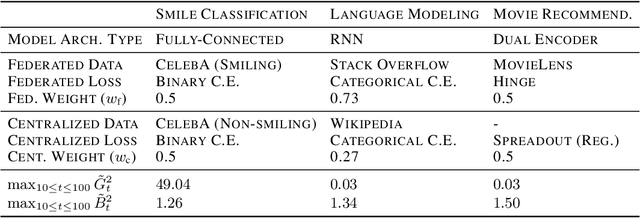
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
Production federated keyword spotting via distillation, filtering, and joint federated-centralized training
Apr 11, 2022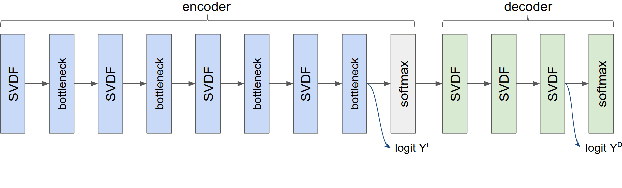
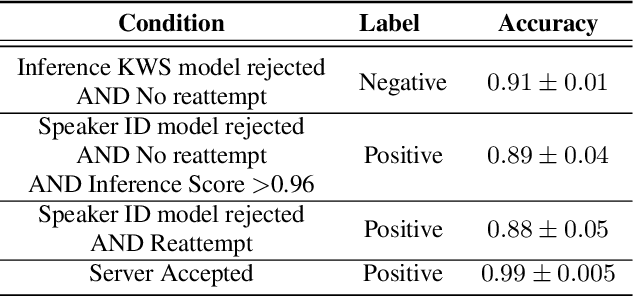
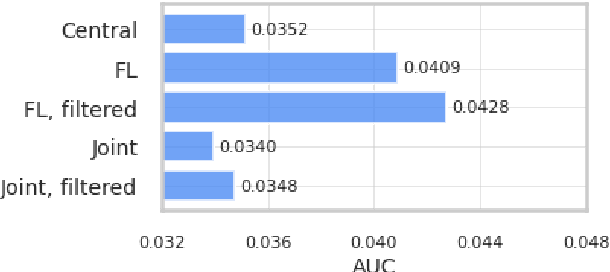

We trained a keyword spotting model using federated learning on real user devices and observed significant improvements when the model was deployed for inference on phones. To compensate for data domains that are missing from on-device training caches, we employed joint federated-centralized training. And to learn in the absence of curated labels on-device, we formulated a confidence filtering strategy based on user-feedback signals for federated distillation. These techniques created models that significantly improved quality metrics in offline evaluations and user-experience metrics in live A/B experiments.
Jointly Learning from Decentralized (Federated) and Centralized Data to Mitigate Distribution Shift
Nov 23, 2021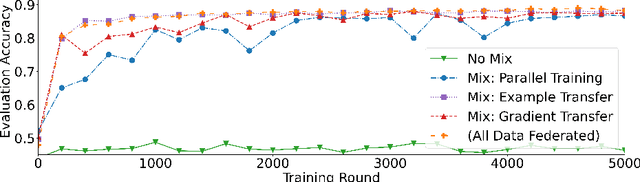
With privacy as a motivation, Federated Learning (FL) is an increasingly used paradigm where learning takes place collectively on edge devices, each with a cache of user-generated training examples that remain resident on the local device. These on-device training examples are gathered in situ during the course of users' interactions with their devices, and thus are highly reflective of at least part of the inference data distribution. Yet a distribution shift may still exist; the on-device training examples may lack for some data inputs expected to be encountered at inference time. This paper proposes a way to mitigate this shift: selective usage of datacenter data, mixed in with FL. By mixing decentralized (federated) and centralized (datacenter) data, we can form an effective training data distribution that better matches the inference data distribution, resulting in more useful models while still meeting the private training data access constraints imposed by FL.
Training Keyword Spotting Models on Non-IID Data with Federated Learning
Jun 04, 2020
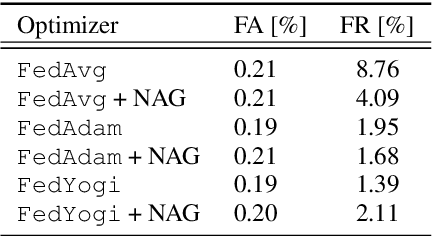


We demonstrate that a production-quality keyword-spotting model can be trained on-device using federated learning and achieve comparable false accept and false reject rates to a centrally-trained model. To overcome the algorithmic constraints associated with fitting on-device data (which are inherently non-independent and identically distributed), we conduct thorough empirical studies of optimization algorithms and hyperparameter configurations using large-scale federated simulations. To overcome resource constraints, we replace memory intensive MTR data augmentation with SpecAugment, which reduces the false reject rate by 56%. Finally, to label examples (given the zero visibility into on-device data), we explore teacher-student training.