 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwang-Sung Jun
Efficient Low-Rank Matrix Estimation, Experimental Design, and Arm-Set-Dependent Low-Rank Bandits
Feb 17, 2024
We study low-rank matrix trace regression and the related problem of low-rank matrix bandits. Assuming access to the distribution of the covariates, we propose a novel low-rank matrix estimation method called LowPopArt and provide its recovery guarantee that depends on a novel quantity denoted by B(Q) that characterizes the hardness of the problem, where Q is the covariance matrix of the measurement distribution. We show that our method can provide tighter recovery guarantees than classical nuclear norm penalized least squares (Koltchinskii et al., 2011) in several problems. To perform efficient estimation with a limited number of measurements from an arbitrarily given measurement set A, we also propose a novel experimental design criterion that minimizes B(Q) with computational efficiency. We leverage our novel estimator and design of experiments to derive two low-rank linear bandit algorithms for general arm sets that enjoy improved regret upper bounds. This improves over previous works on low-rank bandits, which make somewhat restrictive assumptions that the arm set is the unit ball or that an efficient exploration distribution is given. To our knowledge, our experimental design criterion is the first one tailored to low-rank matrix estimation beyond the naive reduction to linear regression, which can be of independent interest.
Better-than-KL PAC-Bayes Bounds
Feb 14, 2024Let $f(\theta, X_1),$ $ \dots,$ $ f(\theta, X_n)$ be a sequence of random elements, where $f$ is a fixed scalar function, $X_1, \dots, X_n$ are independent random variables (data), and $\theta$ is a random parameter distributed according to some data-dependent posterior distribution $P_n$. In this paper, we consider the problem of proving concentration inequalities to estimate the mean of the sequence. An example of such a problem is the estimation of the generalization error of some predictor trained by a stochastic algorithm, such as a neural network where $f$ is a loss function. Classically, this problem is approached through a PAC-Bayes analysis where, in addition to the posterior, we choose a prior distribution which captures our belief about the inductive bias of the learning problem. Then, the key quantity in PAC-Bayes concentration bounds is a divergence that captures the complexity of the learning problem where the de facto standard choice is the KL divergence. However, the tightness of this choice has rarely been questioned. In this paper, we challenge the tightness of the KL-divergence-based bounds by showing that it is possible to achieve a strictly tighter bound. In particular, we demonstrate new high-probability PAC-Bayes bounds with a novel and better-than-KL divergence that is inspired by Zhang et al. (2022). Our proof is inspired by recent advances in regret analysis of gambling algorithms, and its use to derive concentration inequalities. Our result is first-of-its-kind in that existing PAC-Bayes bounds with non-KL divergences are not known to be strictly better than KL. Thus, we believe our work marks the first step towards identifying optimal rates of PAC-Bayes bounds.
Noise-Adaptive Confidence Sets for Linear Bandits and Application to Bayesian Optimization
Feb 12, 2024Adapting to a priori unknown noise level is a very important but challenging problem in sequential decision-making as efficient exploration typically requires knowledge of the noise level, which is often loosely specified. We report significant progress in addressing this issue in linear bandits in two respects. First, we propose a novel confidence set that is `semi-adaptive' to the unknown sub-Gaussian parameter $\sigma_*^2$ in the sense that the (normalized) confidence width scales with $\sqrt{d\sigma_*^2 + \sigma_0^2}$ where $d$ is the dimension and $\sigma_0^2$ is the specified sub-Gaussian parameter (known) that can be much larger than $\sigma_*^2$. This is a significant improvement over $\sqrt{d\sigma_0^2}$ of the standard confidence set of Abbasi-Yadkori et al. (2011), especially when $d$ is large. We show that this leads to an improved regret bound in linear bandits. Second, for bounded rewards, we propose a novel variance-adaptive confidence set that has a much improved numerical performance upon prior art. We then apply this confidence set to develop, as we claim, the first practical variance-adaptive linear bandit algorithm via an optimistic approach, which is enabled by our novel regret analysis technique. Both of our confidence sets rely critically on `regret equality' from online learning. Our empirical evaluation in Bayesian optimization tasks shows that our algorithms demonstrate better or comparable performance compared to existing methods.
Graph Sparsifications using Neural Network Assisted Monte Carlo Tree Search
Nov 17, 2023Graph neural networks have been successful for machine learning, as well as for combinatorial and graph problems such as the Subgraph Isomorphism Problem and the Traveling Salesman Problem. We describe an approach for computing graph sparsifiers by combining a graph neural network and Monte Carlo Tree Search. We first train a graph neural network that takes as input a partial solution and proposes a new node to be added as output. This neural network is then used in a Monte Carlo search to compute a sparsifier. The proposed method consistently outperforms several standard approximation algorithms on different types of graphs and often finds the optimal solution.
Improved Regret Bounds of (Multinomial) Logistic Bandits via Regret-to-Confidence-Set Conversion
Oct 28, 2023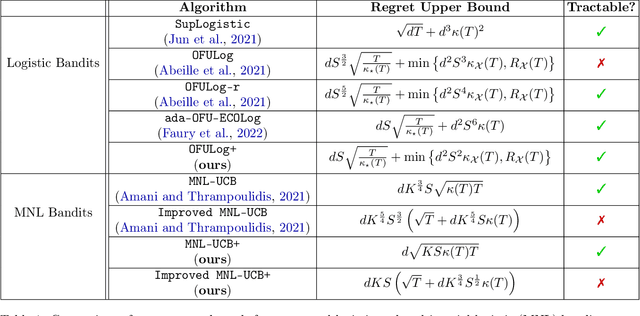
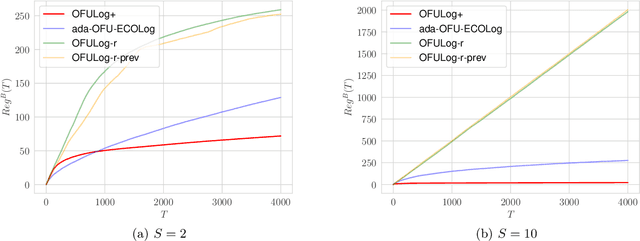
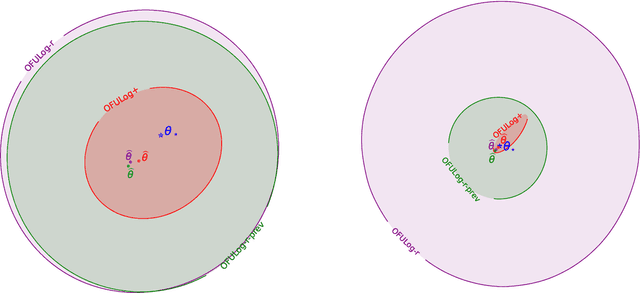
Logistic bandit is a ubiquitous framework of modeling users' choices, e.g., click vs. no click for advertisement recommender system. We observe that the prior works overlook or neglect dependencies in $S \geq \lVert \theta_\star \rVert_2$, where $\theta_\star \in \mathbb{R}^d$ is the unknown parameter vector, which is particularly problematic when $S$ is large, e.g., $S \geq d$. In this work, we improve the dependency on $S$ via a novel approach called {\it regret-to-confidence set conversion (R2CS)}, which allows us to construct a convex confidence set based on only the \textit{existence} of an online learning algorithm with a regret guarantee. Using R2CS, we obtain a strict improvement in the regret bound w.r.t. $S$ in logistic bandits while retaining computational feasibility and the dependence on other factors such as $d$ and $T$. We apply our new confidence set to the regret analyses of logistic bandits with a new martingale concentration step that circumvents an additional factor of $S$. We then extend this analysis to multinomial logistic bandits and obtain similar improvements in the regret, showing the efficacy of R2CS. While we applied R2CS to the (multinomial) logistic model, R2CS is a generic approach for developing confidence sets that can be used for various models, which can be of independent interest.
Nearly Optimal Steiner Trees using Graph Neural Network Assisted Monte Carlo Tree Search
Apr 30, 2023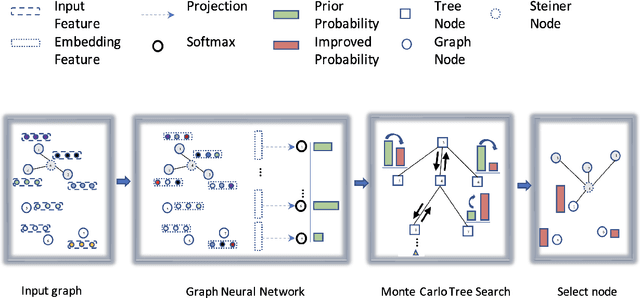

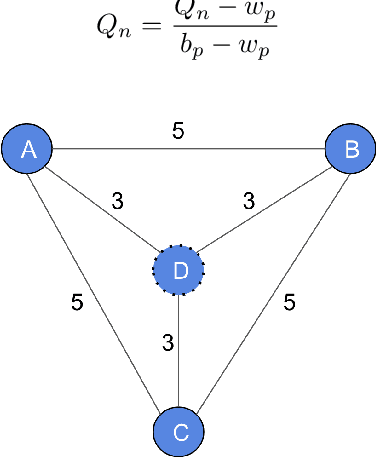
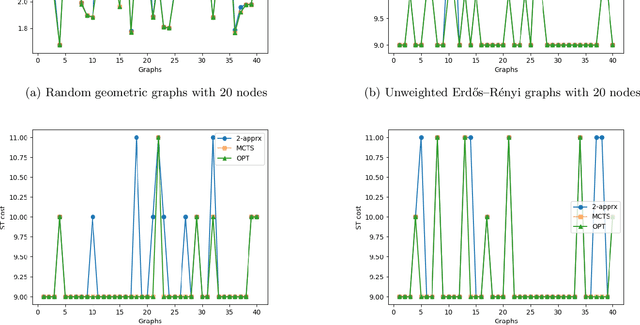
Graph neural networks are useful for learning problems, as well as for combinatorial and graph problems such as the Subgraph Isomorphism Problem and the Traveling Salesman Problem. We describe an approach for computing Steiner Trees by combining a graph neural network and Monte Carlo Tree Search. We first train a graph neural network that takes as input a partial solution and proposes a new node to be added as output. This neural network is then used in a Monte Carlo search to compute a Steiner tree. The proposed method consistently outperforms the standard 2-approximation algorithm on many different types of graphs and often finds the optimal solution.
Kullback-Leibler Maillard Sampling for Multi-armed Bandits with Bounded Rewards
Apr 28, 2023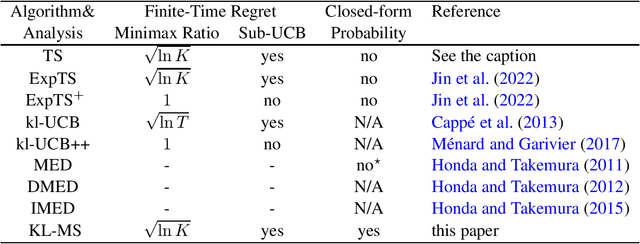
We study $K$-armed bandit problems where the reward distributions of the arms are all supported on the $[0,1]$ interval. It has been a challenge to design regret-efficient randomized exploration algorithms in this setting. Maillard sampling~\cite{maillard13apprentissage}, an attractive alternative to Thompson sampling, has recently been shown to achieve competitive regret guarantees in the sub-Gaussian reward setting~\cite{bian2022maillard} while maintaining closed-form action probabilities, which is useful for offline policy evaluation. In this work, we propose the Kullback-Leibler Maillard Sampling (KL-MS) algorithm, a natural extension of Maillard sampling for achieving KL-style gap-dependent regret bound. We show that KL-MS enjoys the asymptotic optimality when the rewards are Bernoulli and has a worst-case regret bound of the form $O(\sqrt{\mu^*(1-\mu^*) K T \ln K} + K \ln T)$, where $\mu^*$ is the expected reward of the optimal arm, and $T$ is the time horizon length.
Tighter PAC-Bayes Bounds Through Coin-Betting
Feb 12, 2023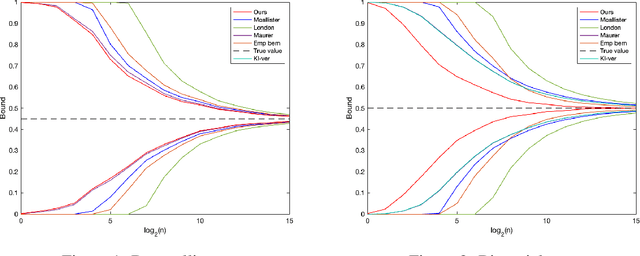
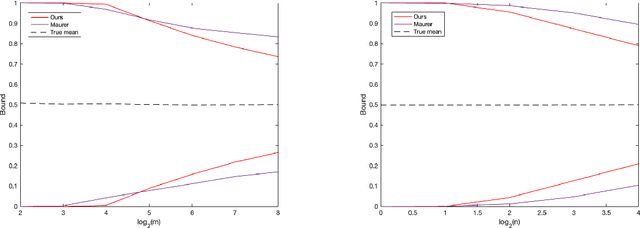
We consider the problem of estimating the mean of a sequence of random elements $f(X_1, \theta)$ $, \ldots, $ $f(X_n, \theta)$ where $f$ is a fixed scalar function, $S=(X_1, \ldots, X_n)$ are independent random variables, and $\theta$ is a possibly $S$-dependent parameter. An example of such a problem would be to estimate the generalization error of a neural network trained on $n$ examples where $f$ is a loss function. Classically, this problem is approached through concentration inequalities holding uniformly over compact parameter sets of functions $f$, for example as in Rademacher or VC type analysis. However, in many problems, such inequalities often yield numerically vacuous estimates. Recently, the \emph{PAC-Bayes} framework has been proposed as a better alternative for this class of problems for its ability to often give numerically non-vacuous bounds. In this paper, we show that we can do even better: we show how to refine the proof strategy of the PAC-Bayes bounds and achieve \emph{even tighter} guarantees. Our approach is based on the \emph{coin-betting} framework that derives the numerically tightest known time-uniform concentration inequalities from the regret guarantees of online gambling algorithms. In particular, we derive the first PAC-Bayes concentration inequality based on the coin-betting approach that holds simultaneously for all sample sizes. We demonstrate its tightness showing that by \emph{relaxing} it we obtain a number of previous results in a closed form including Bernoulli-KL and empirical Bernstein inequalities. Finally, we propose an efficient algorithm to numerically calculate confidence sequences from our bound, which often generates nonvacuous confidence bounds even with one sample, unlike the state-of-the-art PAC-Bayes bounds.
Revisiting Simple Regret Minimization in Multi-Armed Bandits
Oct 30, 2022
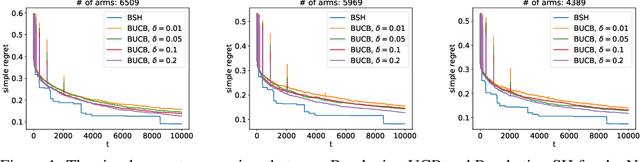

Simple regret is a natural and parameter-free performance criterion for identifying a good arm in multi-armed bandits yet is less popular than the probability of missing the best arm or an $\epsilon$-good arm, perhaps due to lack of easy ways to characterize it. In this paper, we achieve improved simple regret upper bounds for both data-rich ($T\ge n$) and data-poor regime ($T \le n$) where $n$ is the number of arms and $T$ is the number of samples. At its heart is an improved analysis of the well-known Sequential Halving (SH) algorithm that bounds the probability of returning an arm whose mean reward is not within $\epsilon$ from the best (i.e., not $\epsilon$-good) for any choice of $\epsilon>0$, although $\epsilon$ is not an input to SH. We show that this directly implies an optimal simple regret bound of $\mathcal{O}(\sqrt{n/T})$. Furthermore, our upper bound gets smaller as a function of the number of $\epsilon$-good arms. This results in an accelerated rate for the $(\epsilon,\delta)$-PAC criterion, which closes the gap between the upper and lower bounds in prior art. For the more challenging data-poor regime, we propose Bracketing SH (BSH) that enjoys the same improvement even without sampling each arm at least once. Our empirical study shows that BSH outperforms existing methods on real-world tasks.
PopArt: Efficient Sparse Regression and Experimental Design for Optimal Sparse Linear Bandits
Oct 25, 2022
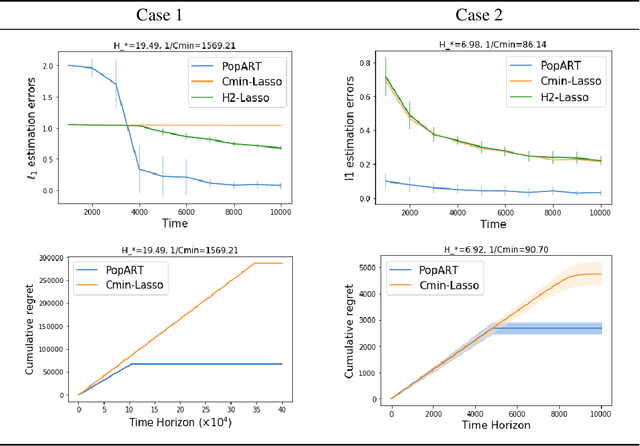
In sparse linear bandits, a learning agent sequentially selects an action and receive reward feedback, and the reward function depends linearly on a few coordinates of the covariates of the actions. This has applications in many real-world sequential decision making problems. In this paper, we propose a simple and computationally efficient sparse linear estimation method called PopArt that enjoys a tighter $\ell_1$ recovery guarantee compared to Lasso (Tibshirani, 1996) in many problems. Our bound naturally motivates an experimental design criterion that is convex and thus computationally efficient to solve. Based on our novel estimator and design criterion, we derive sparse linear bandit algorithms that enjoy improved regret upper bounds upon the state of the art (Hao et al., 2020), especially w.r.t. the geometry of the given action set. Finally, we prove a matching lower bound for sparse linear bandits in the data-poor regime, which closes the gap between upper and lower bounds in prior work.