 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwanyong Park
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024
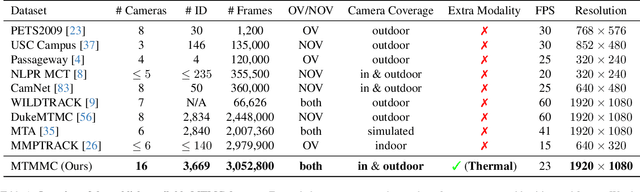
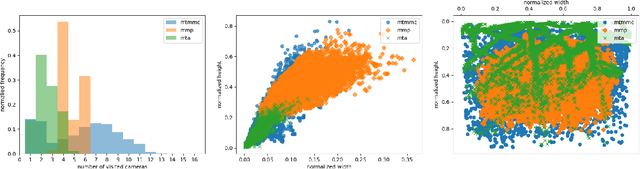

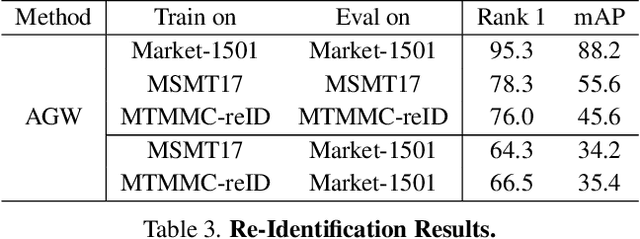
Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis
Dec 07, 2023Stable diffusion is the mainstay of the text-to-image (T2I) synthesis in the community due to its generation performance and open-source nature. Recently, Stable Diffusion XL (SDXL), the successor of stable diffusion, has received a lot of attention due to its significant performance improvements with a higher resolution of 1024x1024 and a larger model. However, its increased computation cost and model size require higher-end hardware(e.g., bigger VRAM GPU) for end-users, incurring higher costs of operation. To address this problem, in this work, we propose an efficient latent diffusion model for text-to-image synthesis obtained by distilling the knowledge of SDXL. To this end, we first perform an in-depth analysis of the denoising U-Net in SDXL, which is the main bottleneck of the model, and then design a more efficient U-Net based on the analysis. Secondly, we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and eventually identify four essential factors, the core of which is that self-attention is the most important part. With our efficient U-Net and self-attention-based knowledge distillation strategy, we build our efficient T2I models, called KOALA-1B & -700M, while reducing the model size up to 54% and 69% of the original SDXL model. In particular, the KOALA-700M is more than twice as fast as SDXL while still retaining a decent generation quality. We hope that due to its balanced speed-performance tradeoff, our KOALA models can serve as a cost-effective alternative to SDXL in resource-constrained environments.
Bidirectional Domain Mixup for Domain Adaptive Semantic Segmentation
Mar 17, 2023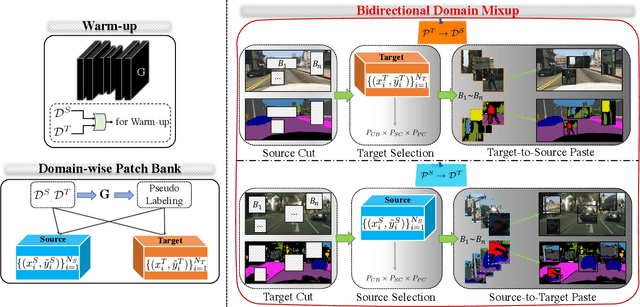
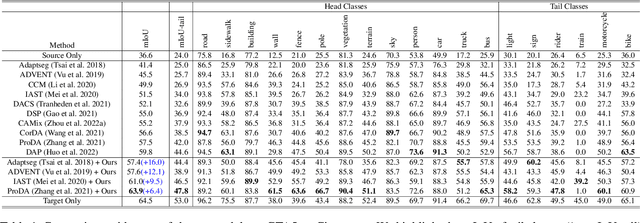
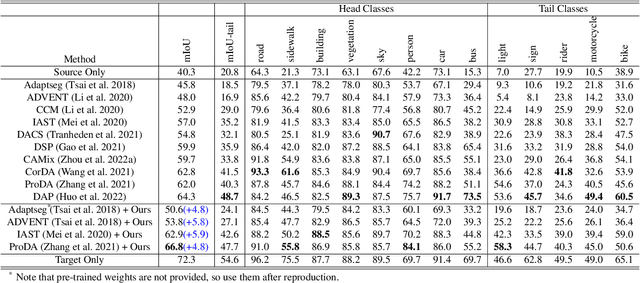

Mixup provides interpolated training samples and allows the model to obtain smoother decision boundaries for better generalization. The idea can be naturally applied to the domain adaptation task, where we can mix the source and target samples to obtain domain-mixed samples for better adaptation. However, the extension of the idea from classification to segmentation (i.e., structured output) is nontrivial. This paper systematically studies the impact of mixup under the domain adaptaive semantic segmentation task and presents a simple yet effective mixup strategy called Bidirectional Domain Mixup (BDM). In specific, we achieve domain mixup in two-step: cut and paste. Given the warm-up model trained from any adaptation techniques, we forward the source and target samples and perform a simple threshold-based cut out of the unconfident regions (cut). After then, we fill-in the dropped regions with the other domain region patches (paste). In doing so, we jointly consider class distribution, spatial structure, and pseudo label confidence. Based on our analysis, we found that BDM leaves domain transferable regions by cutting, balances the dataset-level class distribution while preserving natural scene context by pasting. We coupled our proposal with various state-of-the-art adaptation models and observe significant improvement consistently. We also provide extensive ablation experiments to empirically verify our main components of the framework. Visit our project page with the code at https://sites.google.com/view/bidirectional-domain-mixup
Tracking by Associating Clips
Dec 20, 2022The tracking-by-detection paradigm today has become the dominant method for multi-object tracking and works by detecting objects in each frame and then performing data association across frames. However, its sequential frame-wise matching property fundamentally suffers from the intermediate interruptions in a video, such as object occlusions, fast camera movements, and abrupt light changes. Moreover, it typically overlooks temporal information beyond the two frames for matching. In this paper, we investigate an alternative by treating object association as clip-wise matching. Our new perspective views a single long video sequence as multiple short clips, and then the tracking is performed both within and between the clips. The benefits of this new approach are two folds. First, our method is robust to tracking error accumulation or propagation, as the video chunking allows bypassing the interrupted frames, and the short clip tracking avoids the conventional error-prone long-term track memory management. Second, the multiple frame information is aggregated during the clip-wise matching, resulting in a more accurate long-range track association than the current frame-wise matching. Given the state-of-the-art tracking-by-detection tracker, QDTrack, we showcase how the tracking performance improves with our new tracking formulation. We evaluate our proposals on two tracking benchmarks, TAO and MOT17 that have complementary characteristics and challenges each other.
Bridging Images and Videos: A Simple Learning Framework for Large Vocabulary Video Object Detection
Dec 20, 2022Scaling object taxonomies is one of the important steps toward a robust real-world deployment of recognition systems. We have faced remarkable progress in images since the introduction of the LVIS benchmark. To continue this success in videos, a new video benchmark, TAO, was recently presented. Given the recent encouraging results from both detection and tracking communities, we are interested in marrying those two advances and building a strong large vocabulary video tracker. However, supervisions in LVIS and TAO are inherently sparse or even missing, posing two new challenges for training the large vocabulary trackers. First, no tracking supervisions are in LVIS, which leads to inconsistent learning of detection (with LVIS and TAO) and tracking (only with TAO). Second, the detection supervisions in TAO are partial, which results in catastrophic forgetting of absent LVIS categories during video fine-tuning. To resolve these challenges, we present a simple but effective learning framework that takes full advantage of all available training data to learn detection and tracking while not losing any LVIS categories to recognize. With this new learning scheme, we show that consistent improvements of various large vocabulary trackers are capable, setting strong baseline results on the challenging TAO benchmarks.
CD-TTA: Compound Domain Test-time Adaptation for Semantic Segmentation
Dec 16, 2022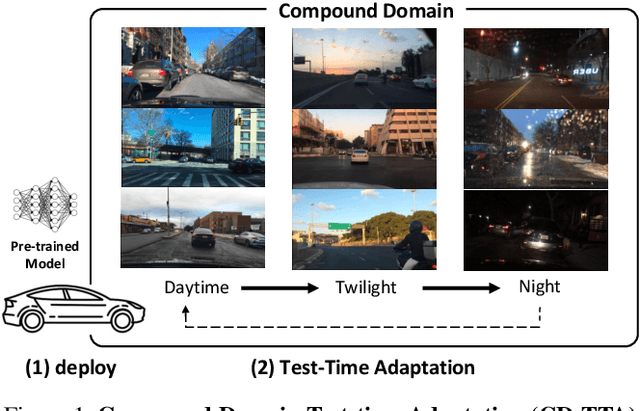

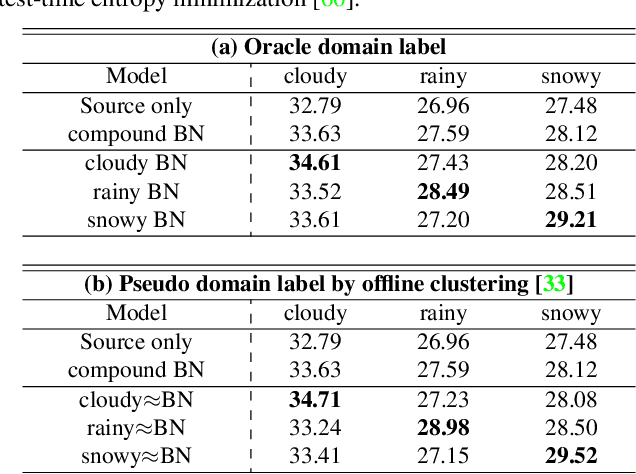
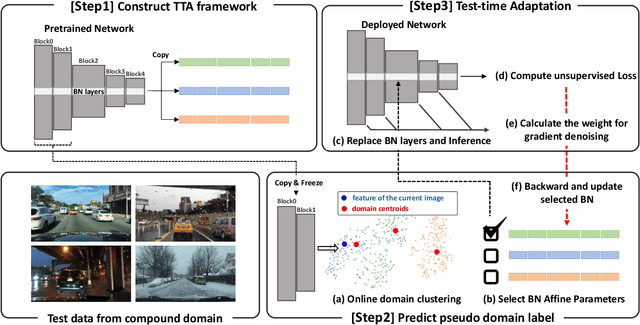
Test-time adaptation (TTA) has attracted significant attention due to its practical properties which enable the adaptation of a pre-trained model to a new domain with only target dataset during the inference stage. Prior works on TTA assume that the target dataset comes from the same distribution and thus constitutes a single homogeneous domain. In practice, however, the target domain can contain multiple homogeneous domains which are sufficiently distinctive from each other and those multiple domains might occur cyclically. Our preliminary investigation shows that domain-specific TTA outperforms vanilla TTA treating compound domain (CD) as a single one. However, domain labels are not available for CD, which makes domain-specific TTA not practicable. To this end, we propose an online clustering algorithm for finding pseudo-domain labels to obtain similar benefits as domain-specific configuration and accumulating knowledge of cyclic domains effectively. Moreover, we observe that there is a significant discrepancy in terms of prediction quality among samples, especially in the CD context. This further motivates us to boost its performance with gradient denoising by considering the image-wise similarity with the source distribution. Overall, the key contribution of our work lies in proposing a highly significant new task compound domain test-time adaptation (CD-TTA) on semantic segmentation as well as providing a strong baseline to facilitate future works to benchmark.
Learning Classifiers of Prototypes and Reciprocal Points for Universal Domain Adaptation
Dec 16, 2022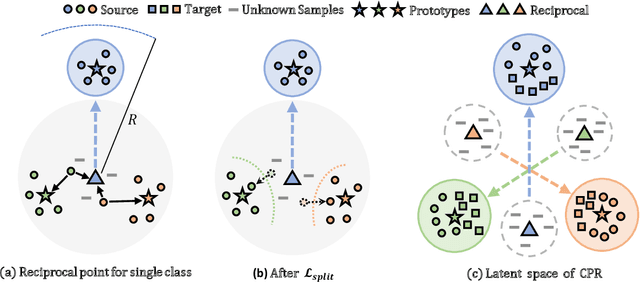

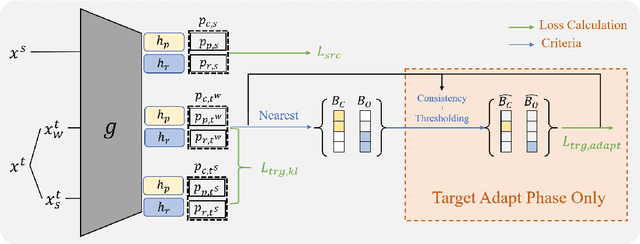
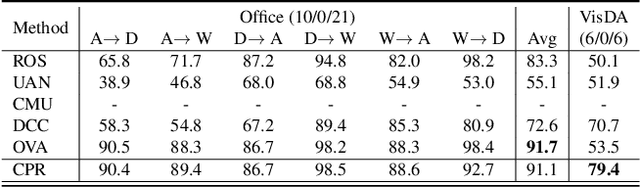
Universal Domain Adaptation aims to transfer the knowledge between the datasets by handling two shifts: domain-shift and category-shift. The main challenge is correctly distinguishing the unknown target samples while adapting the distribution of known class knowledge from source to target. Most existing methods approach this problem by first training the target adapted known classifier and then relying on the single threshold to distinguish unknown target samples. However, this simple threshold-based approach prevents the model from considering the underlying complexities existing between the known and unknown samples in the high-dimensional feature space. In this paper, we propose a new approach in which we use two sets of feature points, namely dual Classifiers for Prototypes and Reciprocals (CPR). Our key idea is to associate each prototype with corresponding known class features while pushing the reciprocals apart from these prototypes to locate them in the potential unknown feature space. The target samples are then classified as unknown if they fall near any reciprocals at test time. To successfully train our framework, we collect the partial, confident target samples that are classified as known or unknown through on our proposed multi-criteria selection. We then additionally apply the entropy loss regularization to them. For further adaptation, we also apply standard consistency regularization that matches the predictions of two different views of the input to make more compact target feature space. We evaluate our proposal, CPR, on three standard benchmarks and achieve comparable or new state-of-the-art results. We also provide extensive ablation experiments to verify our main design choices in our framework.
Per-Clip Video Object Segmentation
Aug 03, 2022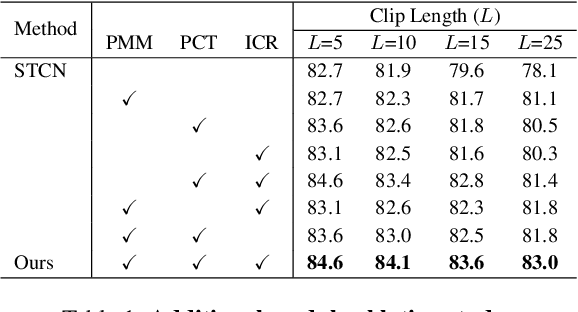
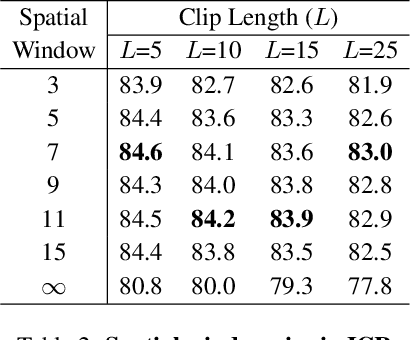
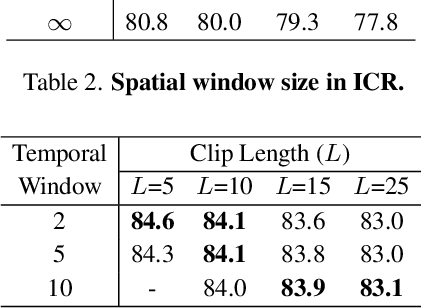

Recently, memory-based approaches show promising results on semi-supervised video object segmentation. These methods predict object masks frame-by-frame with the help of frequently updated memory of the previous mask. Different from this per-frame inference, we investigate an alternative perspective by treating video object segmentation as clip-wise mask propagation. In this per-clip inference scheme, we update the memory with an interval and simultaneously process a set of consecutive frames (i.e. clip) between the memory updates. The scheme provides two potential benefits: accuracy gain by clip-level optimization and efficiency gain by parallel computation of multiple frames. To this end, we propose a new method tailored for the per-clip inference. Specifically, we first introduce a clip-wise operation to refine the features based on intra-clip correlation. In addition, we employ a progressive matching mechanism for efficient information-passing within a clip. With the synergy of two modules and a newly proposed per-clip based training, our network achieves state-of-the-art performance on Youtube-VOS 2018/2019 val (84.6% and 84.6%) and DAVIS 2016/2017 val (91.9% and 86.1%). Furthermore, our model shows a great speed-accuracy trade-off with varying memory update intervals, which leads to huge flexibility.
LabOR: Labeling Only if Required for Domain Adaptive Semantic Segmentation
Aug 12, 2021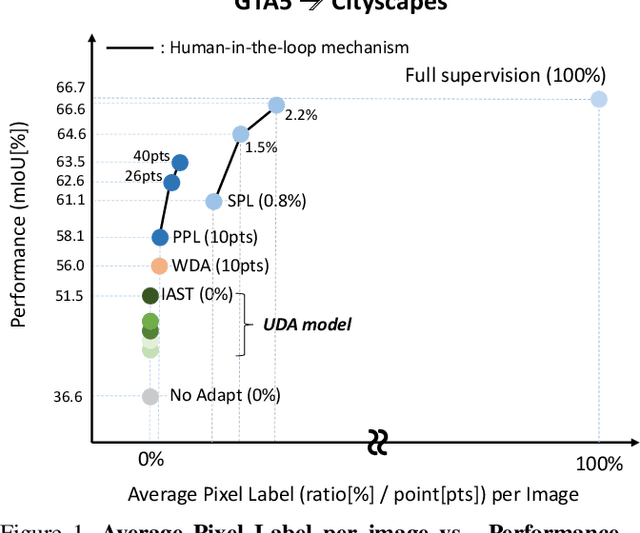
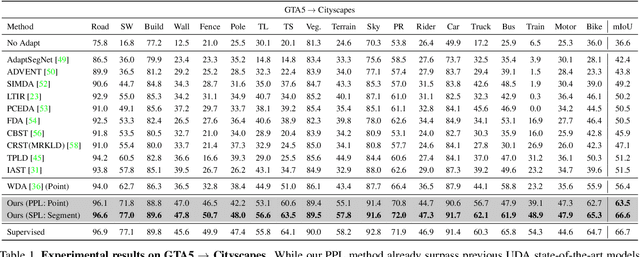
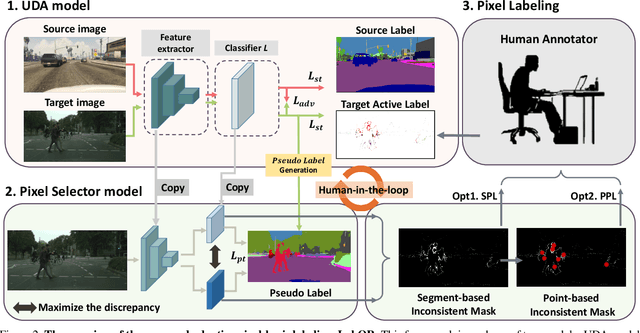
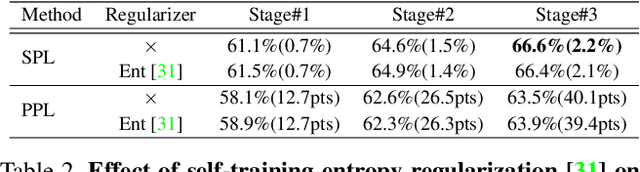
Unsupervised Domain Adaptation (UDA) for semantic segmentation has been actively studied to mitigate the domain gap between label-rich source data and unlabeled target data. Despite these efforts, UDA still has a long way to go to reach the fully supervised performance. To this end, we propose a Labeling Only if Required strategy, LabOR, where we introduce a human-in-the-loop approach to adaptively give scarce labels to points that a UDA model is uncertain about. In order to find the uncertain points, we generate an inconsistency mask using the proposed adaptive pixel selector and we label these segment-based regions to achieve near supervised performance with only a small fraction (about 2.2%) ground truth points, which we call "Segment based Pixel-Labeling (SPL)". To further reduce the efforts of the human annotator, we also propose "Point-based Pixel-Labeling (PPL)", which finds the most representative points for labeling within the generated inconsistency mask. This reduces efforts from 2.2% segment label to 40 points label while minimizing performance degradation. Through extensive experimentation, we show the advantages of this new framework for domain adaptive semantic segmentation while minimizing human labor costs.
Unsupervised Domain Adaptation for Video Semantic Segmentation
Jul 23, 2021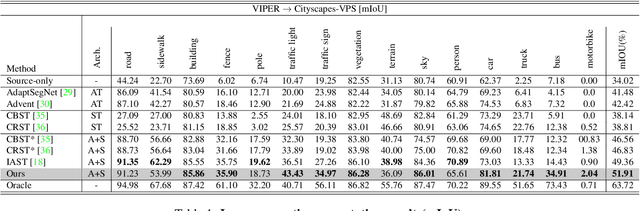
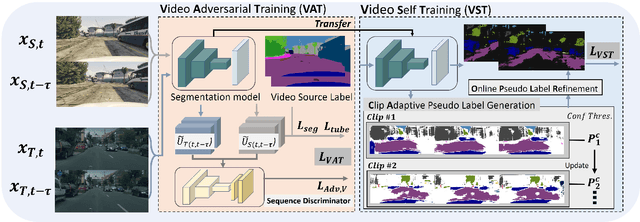
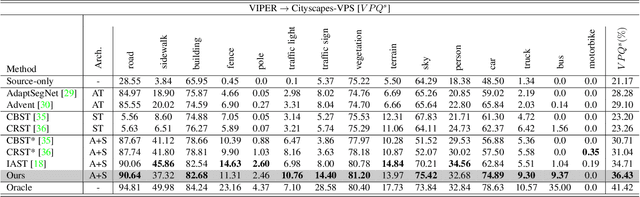
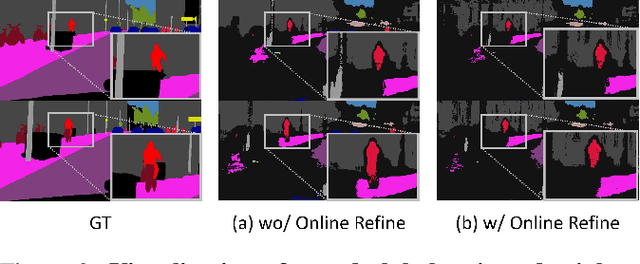
Unsupervised Domain Adaptation for semantic segmentation has gained immense popularity since it can transfer knowledge from simulation to real (Sim2Real) by largely cutting out the laborious per pixel labeling efforts at real. In this work, we present a new video extension of this task, namely Unsupervised Domain Adaptation for Video Semantic Segmentation. As it became easy to obtain large-scale video labels through simulation, we believe attempting to maximize Sim2Real knowledge transferability is one of the promising directions for resolving the fundamental data-hungry issue in the video. To tackle this new problem, we present a novel two-phase adaptation scheme. In the first step, we exhaustively distill source domain knowledge using supervised loss functions. Simultaneously, video adversarial training (VAT) is employed to align the features from source to target utilizing video context. In the second step, we apply video self-training (VST), focusing only on the target data. To construct robust pseudo labels, we exploit the temporal information in the video, which has been rarely explored in the previous image-based self-training approaches. We set strong baseline scores on 'VIPER to CityscapeVPS' adaptation scenario. We show that our proposals significantly outperform previous image-based UDA methods both on image-level (mIoU) and video-level (VPQ) evaluation metrics.