 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKyuhong Shim
Role of Sensing and Computer Vision in 6G Wireless Communications
May 07, 2024
Recently, we are witnessing the remarkable progress and widespread adoption of sensing technologies in autonomous driving, robotics, and metaverse. Considering the rapid advancement of computer vision (CV) technology to analyze the sensing information, we anticipate a proliferation of wireless applications exploiting the sensing and CV technologies in 6G. In this article, we provide a holistic overview of the sensing and CV-aided wireless communications (SVWC) framework for 6G. By analyzing the high-resolution sensing information through the powerful CV techniques, SVWC can quickly and accurately understand the wireless environments and then perform the wireless tasks. To demonstrate the efficacy of SVWC, we design the whole process of SVWC including the sensing dataset collection, DL model training, and execution of realistic wireless tasks. From the numerical evaluations on 6G communication scenarios, we show that SVWC achieves considerable performance gains over the conventional 5G systems in terms of positioning accuracy, data rate, and access latency.
Expand-and-Quantize: Unsupervised Semantic Segmentation Using High-Dimensional Space and Product Quantization
Dec 12, 2023Unsupervised semantic segmentation (USS) aims to discover and recognize meaningful categories without any labels. For a successful USS, two key abilities are required: 1) information compression and 2) clustering capability. Previous methods have relied on feature dimension reduction for information compression, however, this approach may hinder the process of clustering. In this paper, we propose a novel USS framework called Expand-and-Quantize Unsupervised Semantic Segmentation (EQUSS), which combines the benefits of high-dimensional spaces for better clustering and product quantization for effective information compression. Our extensive experiments demonstrate that EQUSS achieves state-of-the-art results on three standard benchmarks. In addition, we analyze the entropy of USS features, which is the first step towards understanding USS from the perspective of information theory.
Improving Small Footprint Few-shot Keyword Spotting with Supervision on Auxiliary Data
Aug 31, 2023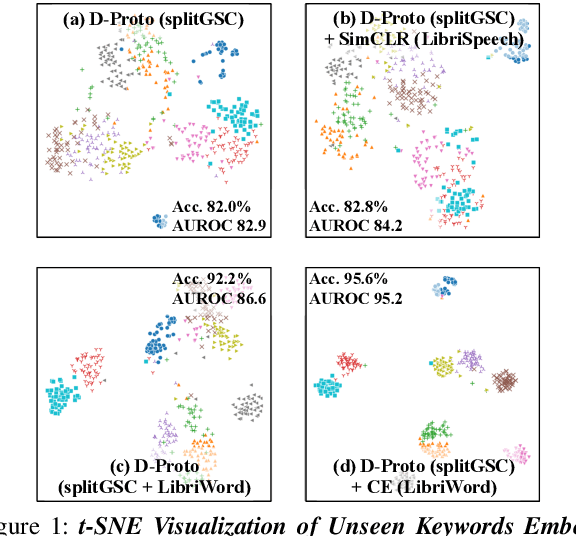

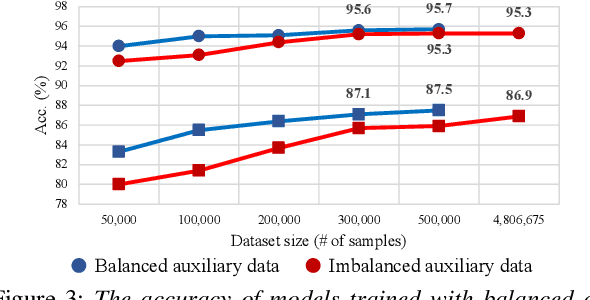
Few-shot keyword spotting (FS-KWS) models usually require large-scale annotated datasets to generalize to unseen target keywords. However, existing KWS datasets are limited in scale and gathering keyword-like labeled data is costly undertaking. To mitigate this issue, we propose a framework that uses easily collectible, unlabeled reading speech data as an auxiliary source. Self-supervised learning has been widely adopted for learning representations from unlabeled data; however, it is known to be suitable for large models with enough capacity and is not practical for training a small footprint FS-KWS model. Instead, we automatically annotate and filter the data to construct a keyword-like dataset, LibriWord, enabling supervision on auxiliary data. We then adopt multi-task learning that helps the model to enhance the representation power from out-of-domain auxiliary data. Our method notably improves the performance over competitive methods in the FS-KWS benchmark.
Knowledge Distillation from Non-streaming to Streaming ASR Encoder using Auxiliary Non-streaming Layer
Aug 31, 2023



Streaming automatic speech recognition (ASR) models are restricted from accessing future context, which results in worse performance compared to the non-streaming models. To improve the performance of streaming ASR, knowledge distillation (KD) from the non-streaming to streaming model has been studied, mainly focusing on aligning the output token probabilities. In this paper, we propose a layer-to-layer KD from the teacher encoder to the student encoder. To ensure that features are extracted using the same context, we insert auxiliary non-streaming branches to the student and perform KD from the non-streaming teacher layer to the non-streaming auxiliary layer. We design a special KD loss that leverages the autoregressive predictive coding (APC) mechanism to encourage the streaming model to predict unseen future contexts. Experimental results show that the proposed method can significantly reduce the word error rate compared to previous token probability distillation methods.
Depth-Relative Self Attention for Monocular Depth Estimation
Apr 25, 2023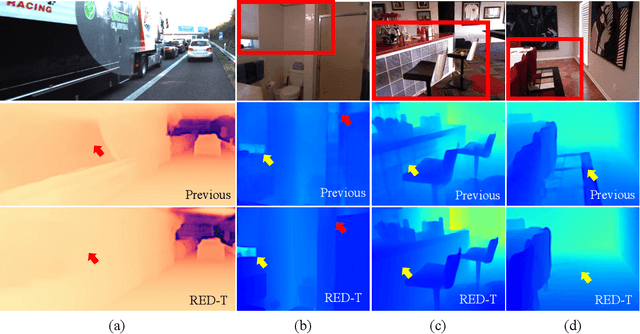
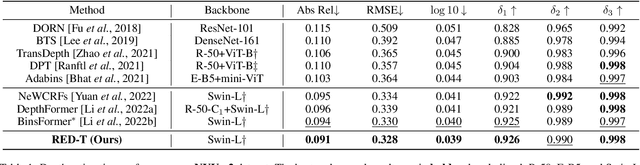

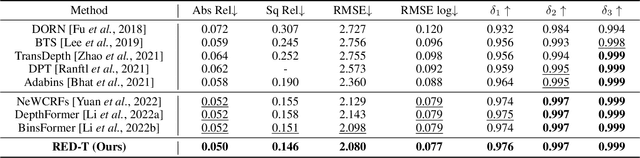
Monocular depth estimation is very challenging because clues to the exact depth are incomplete in a single RGB image. To overcome the limitation, deep neural networks rely on various visual hints such as size, shade, and texture extracted from RGB information. However, we observe that if such hints are overly exploited, the network can be biased on RGB information without considering the comprehensive view. We propose a novel depth estimation model named RElative Depth Transformer (RED-T) that uses relative depth as guidance in self-attention. Specifically, the model assigns high attention weights to pixels of close depth and low attention weights to pixels of distant depth. As a result, the features of similar depth can become more likely to each other and thus less prone to misused visual hints. We show that the proposed model achieves competitive results in monocular depth estimation benchmarks and is less biased to RGB information. In addition, we propose a novel monocular depth estimation benchmark that limits the observable depth range during training in order to evaluate the robustness of the model for unseen depths.
Semantic-Preserving Augmentation for Robust Image-Text Retrieval
Mar 10, 2023

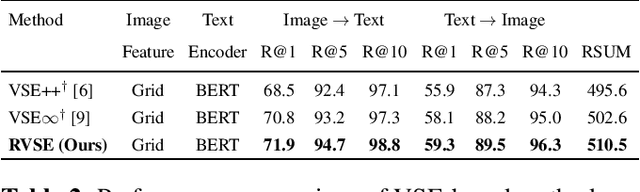
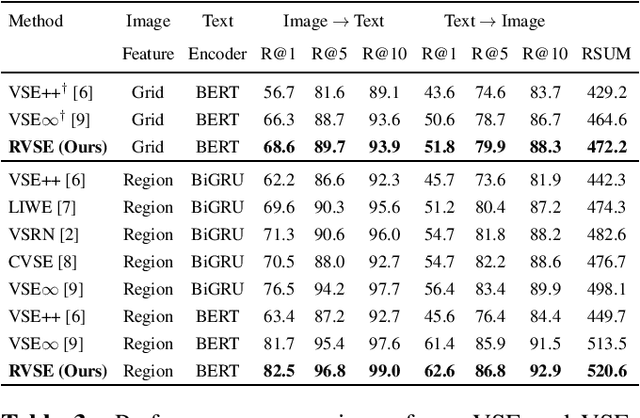
Image text retrieval is a task to search for the proper textual descriptions of the visual world and vice versa. One challenge of this task is the vulnerability to input image and text corruptions. Such corruptions are often unobserved during the training, and degrade the retrieval model decision quality substantially. In this paper, we propose a novel image text retrieval technique, referred to as robust visual semantic embedding (RVSE), which consists of novel image-based and text-based augmentation techniques called semantic preserving augmentation for image (SPAugI) and text (SPAugT). Since SPAugI and SPAugT change the original data in a way that its semantic information is preserved, we enforce the feature extractors to generate semantic aware embedding vectors regardless of the corruption, improving the model robustness significantly. From extensive experiments using benchmark datasets, we show that RVSE outperforms conventional retrieval schemes in terms of image-text retrieval performance.
Teacher Intervention: Improving Convergence of Quantization Aware Training for Ultra-Low Precision Transformers
Feb 23, 2023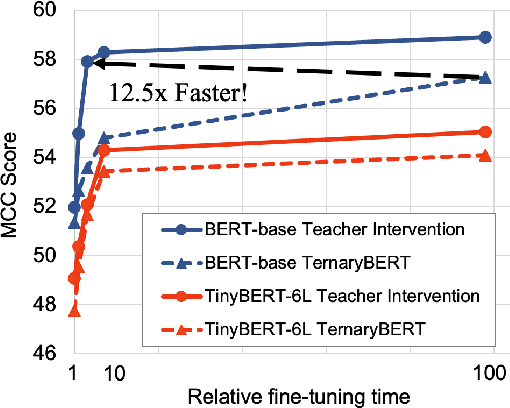
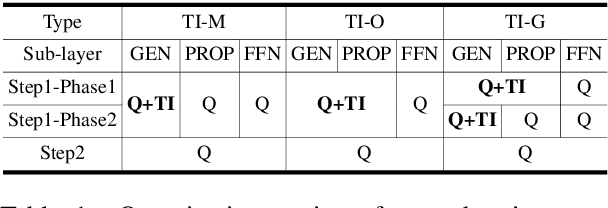
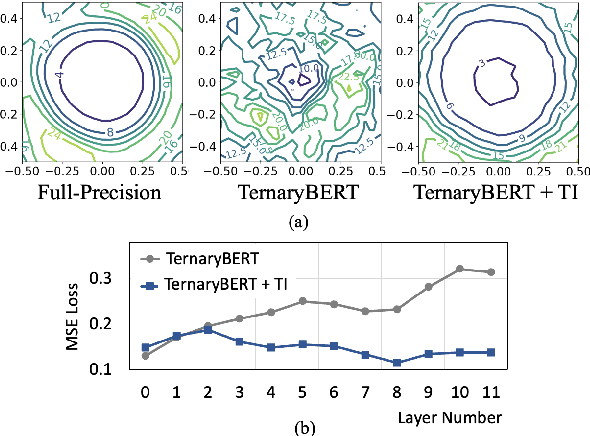
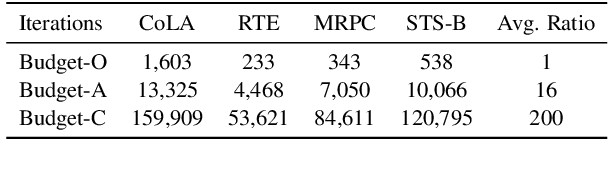
Pre-trained Transformer models such as BERT have shown great success in a wide range of applications, but at the cost of substantial increases in model complexity. Quantization-aware training (QAT) is a promising method to lower the implementation cost and energy consumption. However, aggressive quantization below 2-bit causes considerable accuracy degradation due to unstable convergence, especially when the downstream dataset is not abundant. This work proposes a proactive knowledge distillation method called Teacher Intervention (TI) for fast converging QAT of ultra-low precision pre-trained Transformers. TI intervenes layer-wise signal propagation with the intact signal from the teacher to remove the interference of propagated quantization errors, smoothing loss surface of QAT and expediting the convergence. Furthermore, we propose a gradual intervention mechanism to stabilize the recovery of subsections of Transformer layers from quantization. The proposed schemes enable fast convergence of QAT and improve the model accuracy regardless of the diverse characteristics of downstream fine-tuning tasks. We demonstrate that TI consistently achieves superior accuracy with significantly lower fine-tuning iterations on well-known Transformers of natural language processing as well as computer vision compared to the state-of-the-art QAT methods.
Vision Transformer-based Feature Extraction for Generalized Zero-Shot Learning
Feb 02, 2023
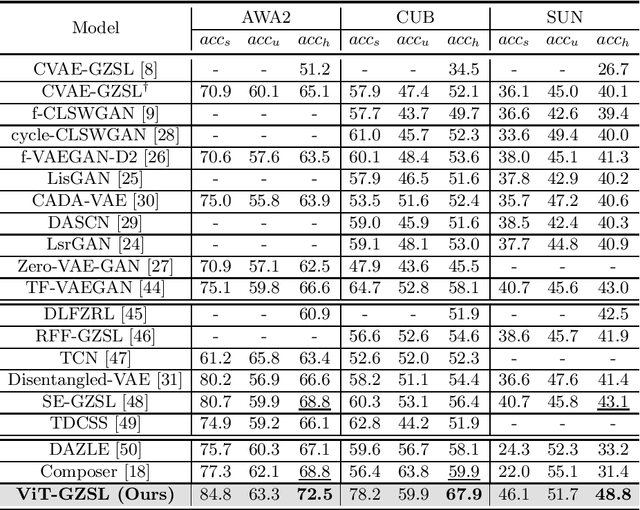
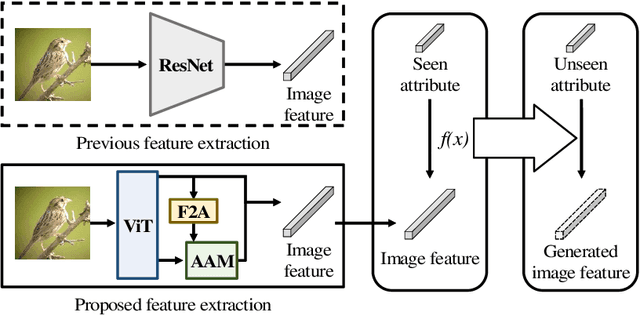

Generalized zero-shot learning (GZSL) is a technique to train a deep learning model to identify unseen classes using the image attribute. In this paper, we put forth a new GZSL approach exploiting Vision Transformer (ViT) to maximize the attribute-related information contained in the image feature. In ViT, the entire image region is processed without the degradation of the image resolution and the local image information is preserved in patch features. To fully enjoy these benefits of ViT, we exploit patch features as well as the CLS feature in extracting the attribute-related image feature. In particular, we propose a novel attention-based module, called attribute attention module (AAM), to aggregate the attribute-related information in patch features. In AAM, the correlation between each patch feature and the synthetic image attribute is used as the importance weight for each patch. From extensive experiments on benchmark datasets, we demonstrate that the proposed technique outperforms the state-of-the-art GZSL approaches by a large margin.
Exploring Attention Map Reuse for Efficient Transformer Neural Networks
Jan 29, 2023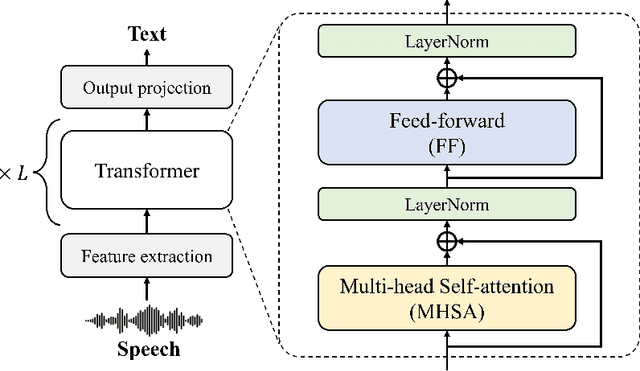
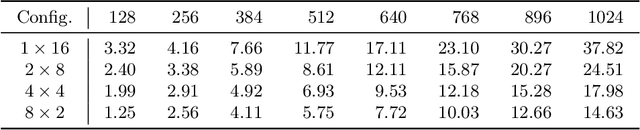
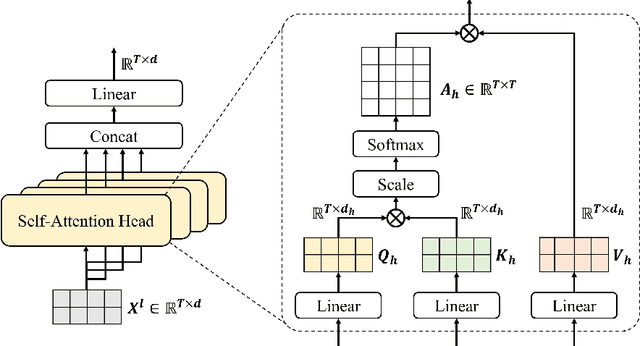
Transformer-based deep neural networks have achieved great success in various sequence applications due to their powerful ability to model long-range dependency. The key module of Transformer is self-attention (SA) which extracts features from the entire sequence regardless of the distance between positions. Although SA helps Transformer performs particularly well on long-range tasks, SA requires quadratic computation and memory complexity with the input sequence length. Recently, attention map reuse, which groups multiple SA layers to share one attention map, has been proposed and achieved significant speedup for speech recognition models. In this paper, we provide a comprehensive study on attention map reuse focusing on its ability to accelerate inference. We compare the method with other SA compression techniques and conduct a breakdown analysis of its advantages for a long sequence. We demonstrate the effectiveness of attention map reuse by measuring the latency on both CPU and GPU platforms.
A Comparison of Transformer, Convolutional, and Recurrent Neural Networks on Phoneme Recognition
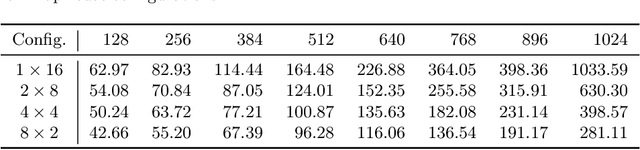
Oct 01, 2022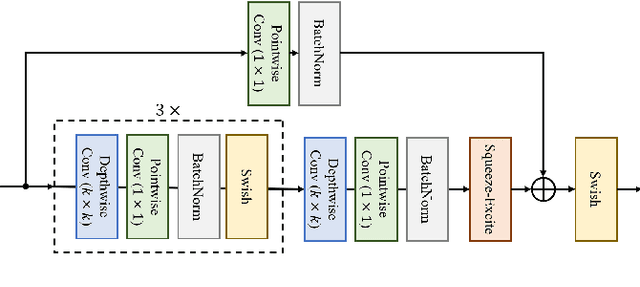
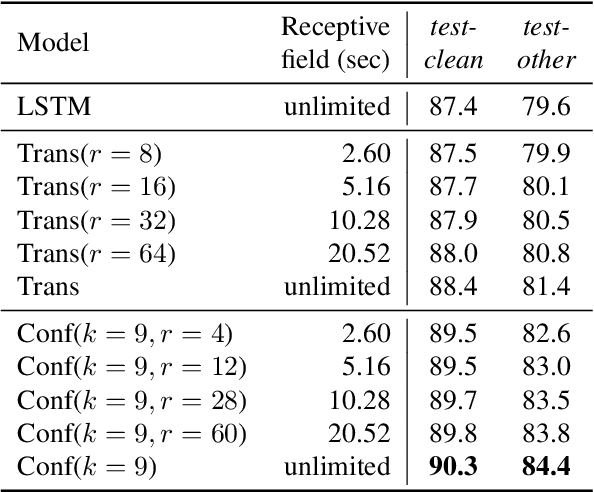
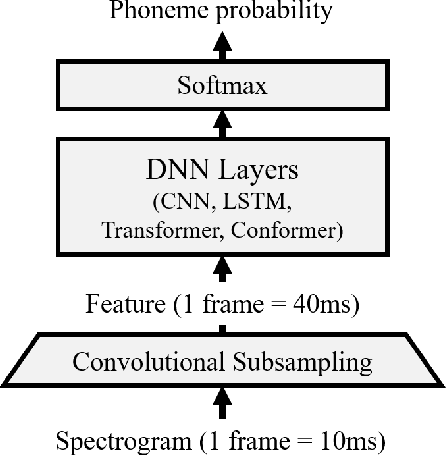
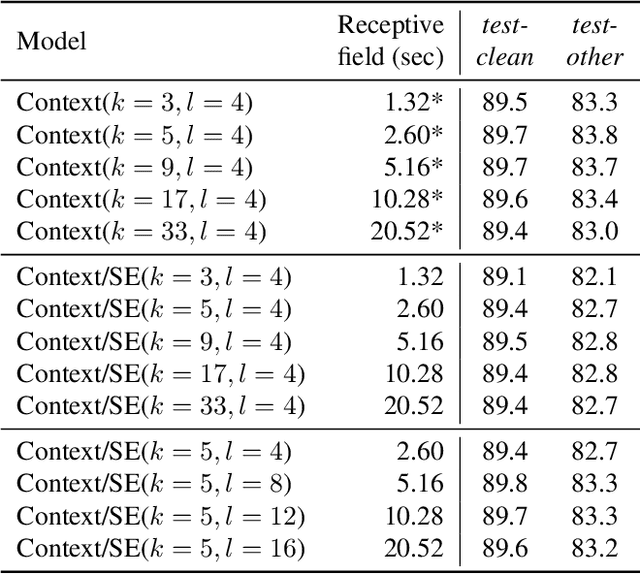
Phoneme recognition is a very important part of speech recognition that requires the ability to extract phonetic features from multiple frames. In this paper, we compare and analyze CNN, RNN, Transformer, and Conformer models using phoneme recognition. For CNN, the ContextNet model is used for the experiments. First, we compare the accuracy of various architectures under different constraints, such as the receptive field length, parameter size, and layer depth. Second, we interpret the performance difference of these models, especially when the observable sequence length varies. Our analyses show that Transformer and Conformer models benefit from the long-range accessibility of self-attention through input frames.