 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL. Iocchi
Image Classification with Small Datasets: Overview and Benchmark
Dec 23, 2022
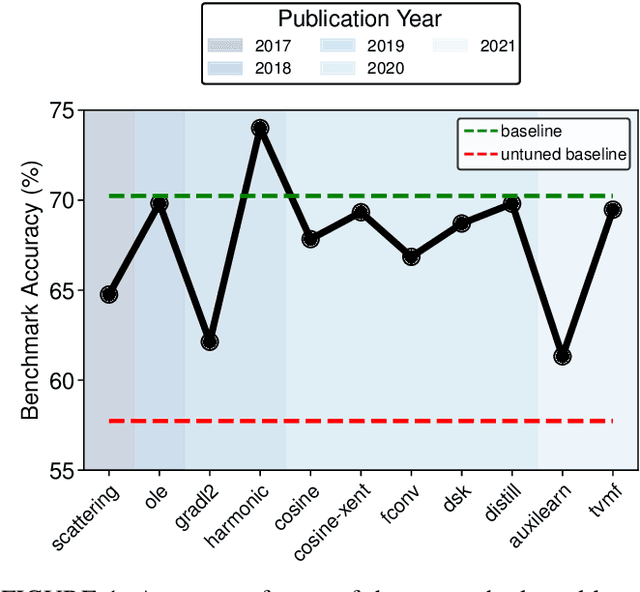


Image classification with small datasets has been an active research area in the recent past. However, as research in this scope is still in its infancy, two key ingredients are missing for ensuring reliable and truthful progress: a systematic and extensive overview of the state of the art, and a common benchmark to allow for objective comparisons between published methods. This article addresses both issues. First, we systematically organize and connect past studies to consolidate a community that is currently fragmented and scattered. Second, we propose a common benchmark that allows for an objective comparison of approaches. It consists of five datasets spanning various domains (e.g., natural images, medical imagery, satellite data) and data types (RGB, grayscale, multispectral). We use this benchmark to re-evaluate the standard cross-entropy baseline and ten existing methods published between 2017 and 2021 at renowned venues. Surprisingly, we find that thorough hyper-parameter tuning on held-out validation data results in a highly competitive baseline and highlights a stunted growth of performance over the years. Indeed, only a single specialized method dating back to 2019 clearly wins our benchmark and outperforms the baseline classifier.
A Close Look at Deep Learning with Small Data
Mar 31, 2020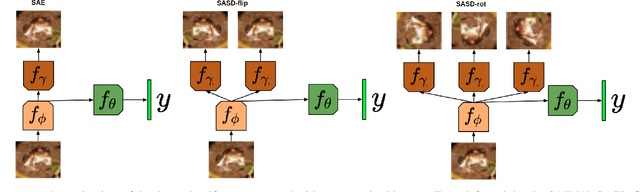
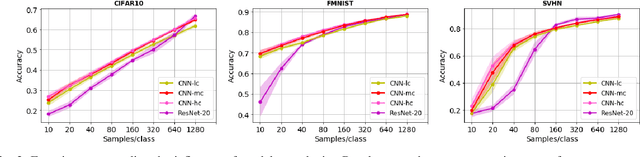
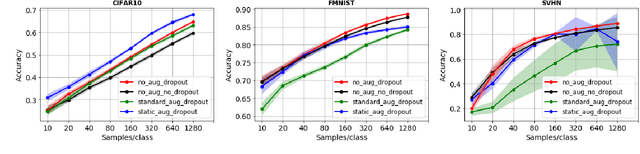
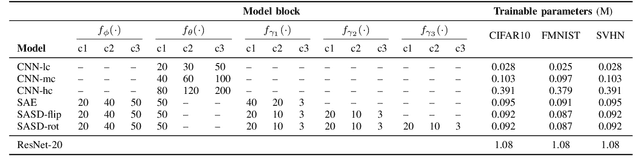
In this work, we perform a wide variety of experiments with different Deep Learning architectures in small data conditions. We show that model complexity is a critical factor when only a few samples per class are available. Differently from the literature, we improve the state of the art using low complexity models. We show that standard convolutional neural networks with relatively few parameters are effective in this scenario. In many of our experiments, low complexity models outperform state-of-the-art architectures. Moreover, we propose a novel network that uses an unsupervised loss to regularize its training. Such architecture either improves the results either performs comparably well to low capacity networks. Surprisingly, experiments show that the dynamic data augmentation pipeline is not beneficial in this particular domain. Statically augmenting the dataset might be a promising research direction while dropout maintains its role as a good regularizer.