 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLan Zhang
BadFusion: 2D-Oriented Backdoor Attacks against 3D Object Detection
May 06, 2024
3D object detection plays an important role in autonomous driving; however, its vulnerability to backdoor attacks has become evident. By injecting ''triggers'' to poison the training dataset, backdoor attacks manipulate the detector's prediction for inputs containing these triggers. Existing backdoor attacks against 3D object detection primarily poison 3D LiDAR signals, where large-sized 3D triggers are injected to ensure their visibility within the sparse 3D space, rendering them easy to detect and impractical in real-world scenarios. In this paper, we delve into the robustness of 3D object detection, exploring a new backdoor attack surface through 2D cameras. Given the prevalent adoption of camera and LiDAR signal fusion for high-fidelity 3D perception, we investigate the latent potential of camera signals to disrupt the process. Although the dense nature of camera signals enables the use of nearly imperceptible small-sized triggers to mislead 2D object detection, realizing 2D-oriented backdoor attacks against 3D object detection is non-trivial. The primary challenge emerges from the fusion process that transforms camera signals into a 3D space, compromising the association with the 2D trigger to the target output. To tackle this issue, we propose an innovative 2D-oriented backdoor attack against LiDAR-camera fusion methods for 3D object detection, named BadFusion, for preserving trigger effectiveness throughout the entire fusion process. The evaluation demonstrates the effectiveness of BadFusion, achieving a significantly higher attack success rate compared to existing 2D-oriented attacks.
Improving Channel Resilience for Task-Oriented Semantic Communications: A Unified Information Bottleneck Approach
Apr 30, 2024Task-oriented semantic communications (TSC) enhance radio resource efficiency by transmitting task-relevant semantic information. However, current research often overlooks the inherent semantic distinctions among encoded features. Due to unavoidable channel variations from time and frequency-selective fading, semantically sensitive feature units could be more susceptible to erroneous inference if corrupted by dynamic channels. Therefore, this letter introduces a unified channel-resilient TSC framework via information bottleneck. This framework complements existing TSC approaches by controlling information flow to capture fine-grained feature-level semantic robustness. Experiments on a case study for real-time subchannel allocation validate the framework's effectiveness.
Micro-Macro Spatial-Temporal Graph-based Encoder-Decoder for Map-Constrained Trajectory Recovery
Apr 29, 2024Recovering intermediate missing GPS points in a sparse trajectory, while adhering to the constraints of the road network, could offer deep insights into users' moving behaviors in intelligent transportation systems. Although recent studies have demonstrated the advantages of achieving map-constrained trajectory recovery via an end-to-end manner, they still face two significant challenges. Firstly, existing methods are mostly sequence-based models. It is extremely hard for them to comprehensively capture the micro-semantics of individual trajectory, including the information of each GPS point and the movement between two GPS points. Secondly, existing approaches ignore the impact of the macro-semantics, i.e., the road conditions and the people's shared travel preferences reflected by a group of trajectories. To address the above challenges, we propose a Micro-Macro Spatial-Temporal Graph-based Encoder-Decoder (MM-STGED). Specifically, we model each trajectory as a graph to efficiently describe the micro-semantics of trajectory and design a novel message-passing mechanism to learn trajectory representations. Additionally, we extract the macro-semantics of trajectories and further incorporate them into a well-designed graph-based decoder to guide trajectory recovery. Extensive experiments conducted on sparse trajectories with three different sampling intervals that are respectively constructed from two real-world trajectory datasets demonstrate the superiority of our proposed model.
Double-I Watermark: Protecting Model Copyright for LLM Fine-tuning
Feb 22, 2024To support various applications, business owners often seek the customized models that are obtained by fine-tuning a pre-trained LLM through the API provided by LLM owners or cloud servers. However, this process carries a substantial risk of model misuse, potentially resulting in severe economic consequences for business owners. Thus, safeguarding the copyright of these customized models during LLM fine-tuning has become an urgent practical requirement, but there are limited existing solutions to provide such protection. To tackle this pressing issue, we propose a novel watermarking approach named "Double-I watermark". Specifically, based on the instruct-tuning data, two types of backdoor data paradigms are introduced with trigger in the instruction and the input, respectively. By leveraging LLM's learning capability to incorporate customized backdoor samples into the dataset, the proposed approach effectively injects specific watermarking information into the customized model during fine-tuning, which makes it easy to inject and verify watermarks in commercial scenarios. We evaluate the proposed "Double-I watermark" under various fine-tuning methods, demonstrating its harmlessness, robustness, uniqueness, imperceptibility, and validity through both theoretical analysis and experimental verification.
Multi-Operational Mathematical Derivations in Latent Space
Nov 02, 2023This paper investigates the possibility of approximating multiple mathematical operations in latent space for expression derivation. To this end, we introduce different multi-operational representation paradigms, modelling mathematical operations as explicit geometric transformations. By leveraging a symbolic engine, we construct a large-scale dataset comprising 1.7M derivation steps stemming from 61K premises and 6 operators, analysing the properties of each paradigm when instantiated with state-of-the-art neural encoders. Specifically, we investigate how different encoding mechanisms can approximate equational reasoning in latent space, exploring the trade-off between learning different operators and specialising within single operations, as well as the ability to support multi-step derivations and out-of-distribution generalisation. Our empirical analysis reveals that the multi-operational paradigm is crucial for disentangling different operators, while discriminating the conclusions for a single operation is achievable in the original expression encoder. Moreover, we show that architectural choices can heavily affect the training dynamics, structural organisation, and generalisation of the latent space, resulting in significant variations across paradigms and classes of encoders.
A Wireless AI-Generated Content (AIGC) Provisioning Framework Empowered by Semantic Communication
Oct 26, 2023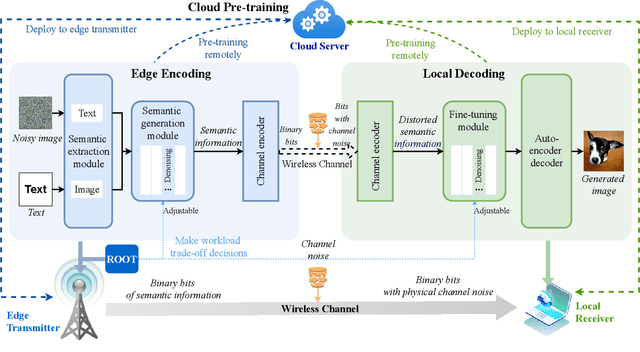
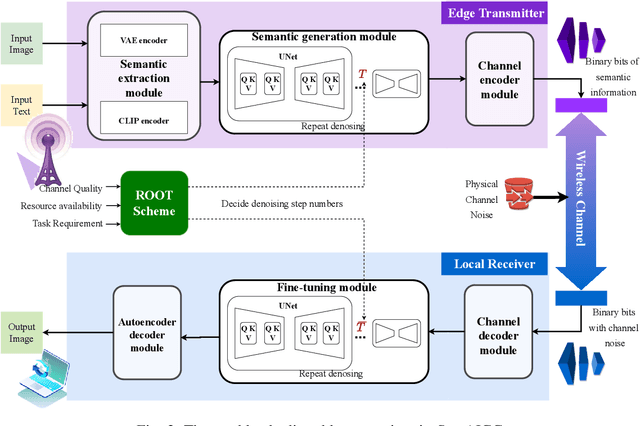
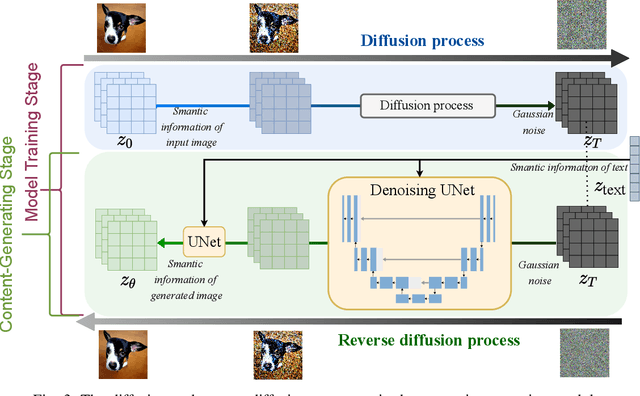
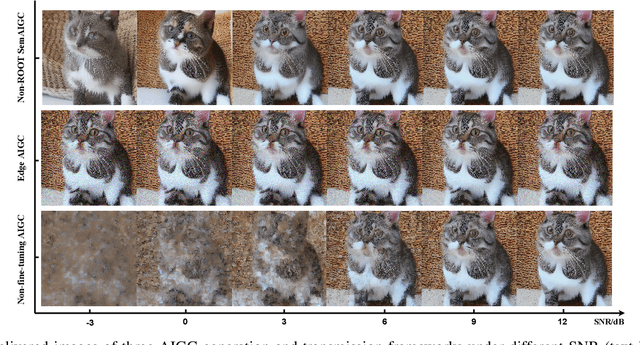
Generative AI applications are recently catering to a vast user base by creating diverse and high-quality AI-generated content (AIGC). With the proliferation of mobile devices and rapid growth of mobile traffic, providing ubiquitous access to high-quality AIGC services via wireless communication networks is becoming the future direction for AIGC products. However, it is challenging to provide optimal AIGC services in wireless networks with unstable channels, limited bandwidth resources, and unevenly distributed computational resources. To tackle these challenges, we propose a semantic communication (SemCom)-empowered AIGC (SemAIGC) generation and transmission framework, where only semantic information of the content rather than all the binary bits should be extracted and transmitted by using SemCom. Specifically, SemAIGC integrates diffusion-based models within the semantic encoder and decoder for efficient content generation and flexible adjustment of the computing workload of both transmitter and receiver. Meanwhile, we devise a resource-aware workload trade-off (ROOT) scheme into the SemAIGC framework to intelligently decide transmitter/receiver workload, thus adjusting the utilization of computational resource according to service requirements. Simulations verify the superiority of our proposed SemAIGC framework in terms of latency and content quality compared to conventional approaches.
ChatGPT for Software Security: Exploring the Strengths and Limitations of ChatGPT in the Security Applications
Aug 10, 2023ChatGPT, as a versatile large language model, has demonstrated remarkable potential in addressing inquiries across various domains. Its ability to analyze, comprehend, and synthesize information from both online sources and user inputs has garnered significant attention. Previous research has explored ChatGPT's competence in code generation and code reviews. In this paper, we delve into ChatGPT's capabilities in security-oriented program analysis, focusing on perspectives from both attackers and security analysts. We present a case study involving several security-oriented program analysis tasks while deliberately introducing challenges to assess ChatGPT's responses. Through an examination of the quality of answers provided by ChatGPT, we gain a clearer understanding of its strengths and limitations in the realm of security-oriented program analysis.
PATROL: Privacy-Oriented Pruning for Collaborative Inference Against Model Inversion Attacks
Jul 20, 2023

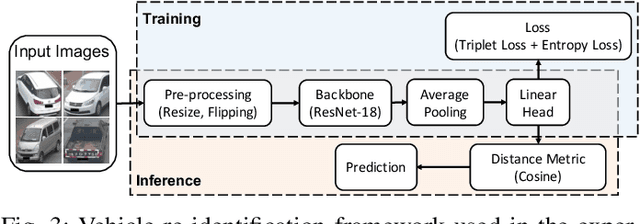

Collaborative inference has been a promising solution to enable resource-constrained edge devices to perform inference using state-of-the-art deep neural networks (DNNs). In collaborative inference, the edge device first feeds the input to a partial DNN locally and then uploads the intermediate result to the cloud to complete the inference. However, recent research indicates model inversion attacks (MIAs) can reconstruct input data from intermediate results, posing serious privacy concerns for collaborative inference. Existing perturbation and cryptography techniques are inefficient and unreliable in defending against MIAs while performing accurate inference. This paper provides a viable solution, named PATROL, which develops privacy-oriented pruning to balance privacy, efficiency, and utility of collaborative inference. PATROL takes advantage of the fact that later layers in a DNN can extract more task-specific features. Given limited local resources for collaborative inference, PATROL intends to deploy more layers at the edge based on pruning techniques to enforce task-specific features for inference and reduce task-irrelevant but sensitive features for privacy preservation. To achieve privacy-oriented pruning, PATROL introduces two key components: Lipschitz regularization and adversarial reconstruction training, which increase the reconstruction errors by reducing the stability of MIAs and enhance the target inference model by adversarial training, respectively.
Fed-CPrompt: Contrastive Prompt for Rehearsal-Free Federated Continual Learning
Jul 10, 2023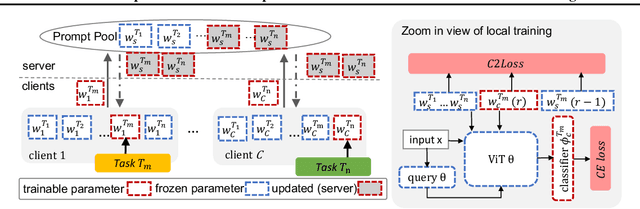



Federated continual learning (FCL) learns incremental tasks over time from confidential datasets distributed across clients. This paper focuses on rehearsal-free FCL, which has severe forgetting issues when learning new tasks due to the lack of access to historical task data. To address this issue, we propose Fed-CPrompt based on prompt learning techniques to obtain task-specific prompts in a communication-efficient way. Fed-CPrompt introduces two key components, asynchronous prompt learning, and contrastive continual loss, to handle asynchronous task arrival and heterogeneous data distributions in FCL, respectively. Extensive experiments demonstrate the effectiveness of Fed-CPrompt in achieving SOTA rehearsal-free FCL performance.
Tight Memory-Regret Lower Bounds for Streaming Bandits
Jun 13, 2023
In this paper, we investigate the streaming bandits problem, wherein the learner aims to minimize regret by dealing with online arriving arms and sublinear arm memory. We establish the tight worst-case regret lower bound of $\Omega \left( (TB)^{\alpha} K^{1-\alpha}\right), \alpha = 2^{B} / (2^{B+1}-1)$ for any algorithm with a time horizon $T$, number of arms $K$, and number of passes $B$. The result reveals a separation between the stochastic bandits problem in the classical centralized setting and the streaming setting with bounded arm memory. Notably, in comparison to the well-known $\Omega(\sqrt{KT})$ lower bound, an additional double logarithmic factor is unavoidable for any streaming bandits algorithm with sublinear memory permitted. Furthermore, we establish the first instance-dependent lower bound of $\Omega \left(T^{1/(B+1)} \sum_{\Delta_x>0} \frac{\mu^*}{\Delta_x}\right)$ for streaming bandits. These lower bounds are derived through a unique reduction from the regret-minimization setting to the sample complexity analysis for a sequence of $\epsilon$-optimal arms identification tasks, which maybe of independent interest. To complement the lower bound, we also provide a multi-pass algorithm that achieves a regret upper bound of $\tilde{O} \left( (TB)^{\alpha} K^{1 - \alpha}\right)$ using constant arm memory.