 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLars Hammarstrand
Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Mar 24, 2024
Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Dec 11, 2023Data leakage is a critical issue when training and evaluating any method based on supervised learning. The state-of-the-art methods for online mapping are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. These datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are located less than $5$ m from a training sample. This allows methods to localize within a memorized implicit map during testing and leads to inflated performance numbers being reported. To reveal the true performance in unseen environments, we introduce geographical splits of the data. Experimental results show significantly lower performance numbers, for some methods dropping with more than $45$ mAP, when retraining and reevaluating existing online mapping models with the proposed split. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of the lifting method and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Geographical splits can be found https://github.com/LiljaAdam/geographical-splits
Improving Open-Set Semi-Supervised Learning with Self-Supervision
Jan 24, 2023



Open-set semi-supervised learning (OSSL) is a realistic setting of semi-supervised learning where the unlabeled training set contains classes that are not present in the labeled set. Many existing OSSL methods assume that these out-of-distribution data are harmful and put effort into excluding data from unknown classes from the training objective. In contrast, we propose an OSSL framework that facilitates learning from all unlabeled data through self-supervision. Additionally, we utilize an energy-based score to accurately recognize data belonging to the known classes, making our method well-suited for handling uncurated data in deployment. We show through extensive experimental evaluations on several datasets that our method shows overall unmatched robustness and performance in terms of closed-set accuracy and open-set recognition compared with state-of-the-art for OSSL. Our code will be released upon publication.
DoubleMatch: Improving Semi-Supervised Learning with Self-Supervision
May 11, 2022



Following the success of supervised learning, semi-supervised learning (SSL) is now becoming increasingly popular. SSL is a family of methods, which in addition to a labeled training set, also use a sizable collection of unlabeled data for fitting a model. Most of the recent successful SSL methods are based on pseudo-labeling approaches: letting confident model predictions act as training labels. While these methods have shown impressive results on many benchmark datasets, a drawback of this approach is that not all unlabeled data are used during training. We propose a new SSL algorithm, DoubleMatch, which combines the pseudo-labeling technique with a self-supervised loss, enabling the model to utilize all unlabeled data in the training process. We show that this method achieves state-of-the-art accuracies on multiple benchmark datasets while also reducing training times compared to existing SSL methods. Code is available at https://github.com/walline/doublematch.
Extended Object Tracking Using Sets Of Trajectories with a PHD Filter
Sep 02, 2021



PHD filtering is a common and effective multiple object tracking (MOT) algorithm used in scenarios where the number of objects and their states are unknown. In scenarios where each object can generate multiple measurements per scan, some PHD filters can estimate the extent of the objects as well as their kinematic properties. Most of these approaches are, however, not able to inherently estimate trajectories and rely on ad-hoc methods, such as different labeling schemes, to build trajectories from the state estimates. This paper presents a Gamma Gaussian inverse Wishart mixture PHD filter that can directly estimate sets of trajectories of extended targets by expanding previous research on tracking sets of trajectories for point source objects to handle extended objects. The new filter is compared to an existing extended PHD filter that uses a labeling scheme to build trajectories, and it is shown that the new filter can estimate object trajectories more reliably.
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
Apr 07, 2021
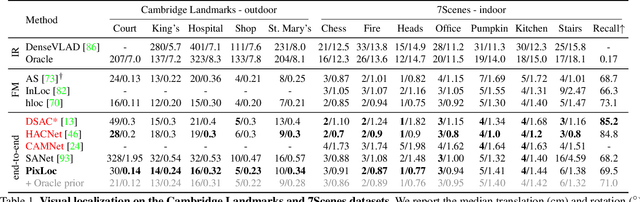
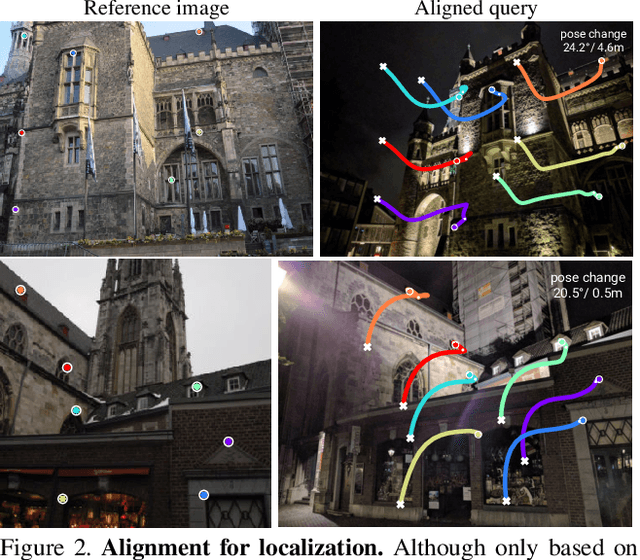

Camera pose estimation in known scenes is a 3D geometry task recently tackled by multiple learning algorithms. Many regress precise geometric quantities, like poses or 3D points, from an input image. This either fails to generalize to new viewpoints or ties the model parameters to a specific scene. In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms. We introduce PixLoc, a scene-agnostic neural network that estimates an accurate 6-DoF pose from an image and a 3D model. Our approach is based on the direct alignment of multiscale deep features, casting camera localization as metric learning. PixLoc learns strong data priors by end-to-end training from pixels to pose and exhibits exceptional generalization to new scenes by separating model parameters and scene geometry. The system can localize in large environments given coarse pose priors but also improve the accuracy of sparse feature matching by jointly refining keypoints and poses with little overhead. The code will be publicly available at https://github.com/cvg/pixloc.
Fine-Grained Segmentation Networks: Self-Supervised Segmentation for Improved Long-Term Visual Localization
Aug 18, 2019



Long-term visual localization is the problem of estimating the camera pose of a given query image in a scene whose appearance changes over time. It is an important problem in practice, for example, encountered in autonomous driving. In order to gain robustness to such changes, long-term localization approaches often use segmantic segmentations as an invariant scene representation, as the semantic meaning of each scene part should not be affected by seasonal and other changes. However, these representations are typically not very discriminative due to the limited number of available classes. In this paper, we propose a new neural network, the Fine-Grained Segmentation Network (FGSN), that can be used to provide image segmentations with a larger number of labels and can be trained in a self-supervised fashion. In addition, we show how FGSNs can be trained to output consistent labels across seasonal changes. We demonstrate through extensive experiments that integrating the fine-grained segmentations produced by our FGSNs into existing localization algorithms leads to substantial improvements in localization performance.
A Cross-Season Correspondence Dataset for Robust Semantic Segmentation
Mar 16, 2019



In this paper, we present a method to utilize 2D-2D point matches between images taken during different image conditions to train a convolutional neural network for semantic segmentation. Enforcing label consistency across the matches makes the final segmentation algorithm robust to seasonal changes. We describe how these 2D-2D matches can be generated with little human interaction by geometrically matching points from 3D models built from images. Two cross-season correspondence datasets are created providing 2D-2D matches across seasonal changes as well as from day to night. The datasets are made publicly available to facilitate further research. We show that adding the correspondences as extra supervision during training improves the segmentation performance of the convolutional neural network, making it more robust to seasonal changes and weather conditions.
Poisson Multi-Bernoulli Mapping Using Gibbs Sampling
Nov 07, 2018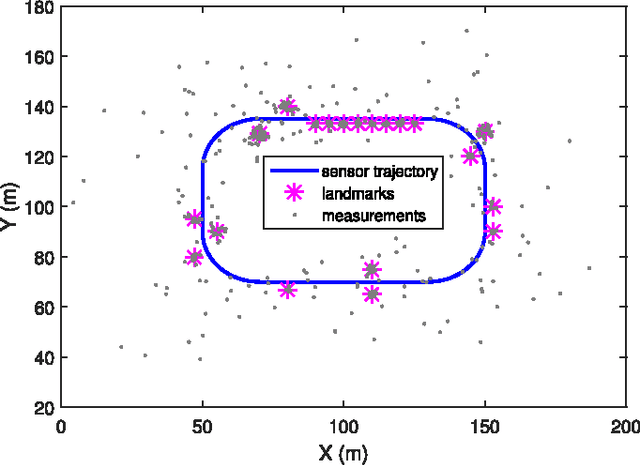
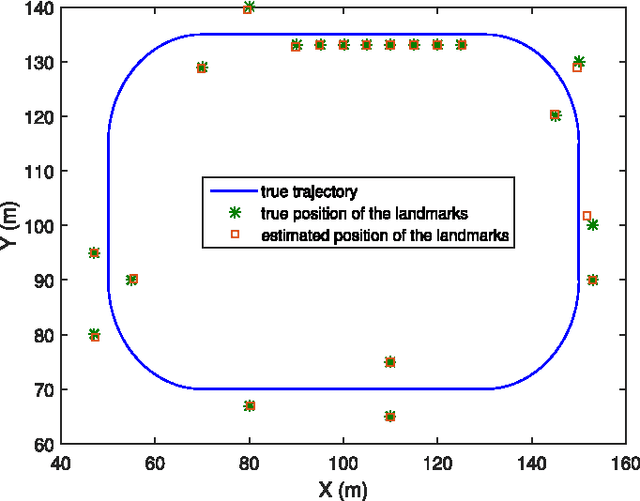
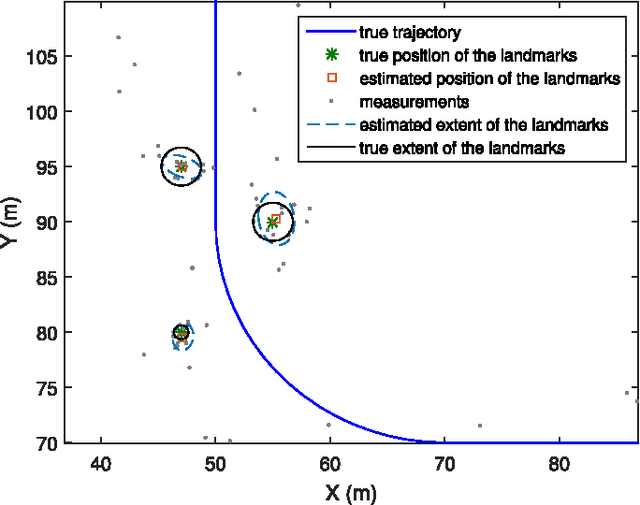
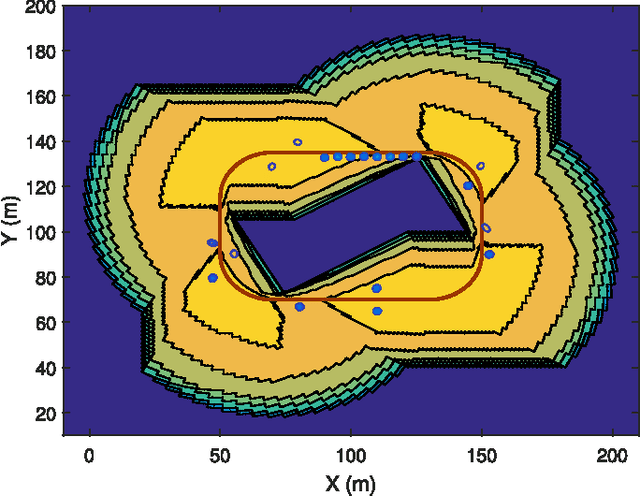
This paper addresses the mapping problem. Using a conjugate prior form, we derive the exact theoretical batch multi-object posterior density of the map given a set of measurements. The landmarks in the map are modeled as extended objects, and the measurements are described as a Poisson process, conditioned on the map. We use a Poisson process prior on the map and prove that the posterior distribution is a hybrid Poisson, multi-Bernoulli mixture distribution. We devise a Gibbs sampling algorithm to sample from the batch multi-object posterior. The proposed method can handle uncertainties in the data associations and the cardinality of the set of landmarks, and is parallelizable, making it suitable for large-scale problems. The performance of the proposed method is evaluated on synthetic data and is shown to outperform a state-of-the-art method.
* 14 pages, 6 figures
Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions
Apr 04, 2018



Visual localization enables autonomous vehicles to navigate in their surroundings and augmented reality applications to link virtual to real worlds. Practical visual localization approaches need to be robust to a wide variety of viewing condition, including day-night changes, as well as weather and seasonal variations, while providing highly accurate 6 degree-of-freedom (6DOF) camera pose estimates. In this paper, we introduce the first benchmark datasets specifically designed for analyzing the impact of such factors on visual localization. Using carefully created ground truth poses for query images taken under a wide variety of conditions, we evaluate the impact of various factors on 6DOF camera pose estimation accuracy through extensive experiments with state-of-the-art localization approaches. Based on our results, we draw conclusions about the difficulty of different conditions, showing that long-term localization is far from solved, and propose promising avenues for future work, including sequence-based localization approaches and the need for better local features. Our benchmark is available at visuallocalization.net.