 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaura Lewis
Learning quantum states and unitaries of bounded gate complexity
Oct 30, 2023
While quantum state tomography is notoriously hard, most states hold little interest to practically-minded tomographers. Given that states and unitaries appearing in Nature are of bounded gate complexity, it is natural to ask if efficient learning becomes possible. In this work, we prove that to learn a state generated by a quantum circuit with $G$ two-qubit gates to a small trace distance, a sample complexity scaling linearly in $G$ is necessary and sufficient. We also prove that the optimal query complexity to learn a unitary generated by $G$ gates to a small average-case error scales linearly in $G$. While sample-efficient learning can be achieved, we show that under reasonable cryptographic conjectures, the computational complexity for learning states and unitaries of gate complexity $G$ must scale exponentially in $G$. We illustrate how these results establish fundamental limitations on the expressivity of quantum machine learning models and provide new perspectives on no-free-lunch theorems in unitary learning. Together, our results answer how the complexity of learning quantum states and unitaries relate to the complexity of creating these states and unitaries.
Improved machine learning algorithm for predicting ground state properties
Jan 30, 2023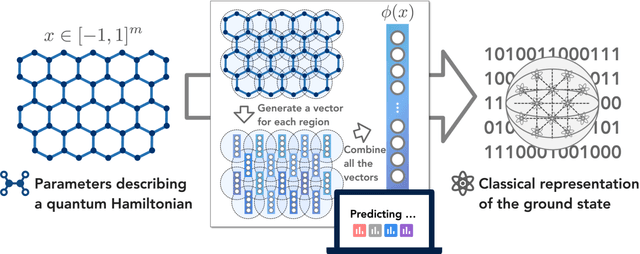

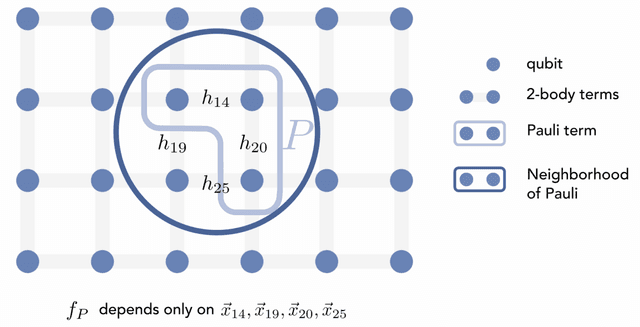
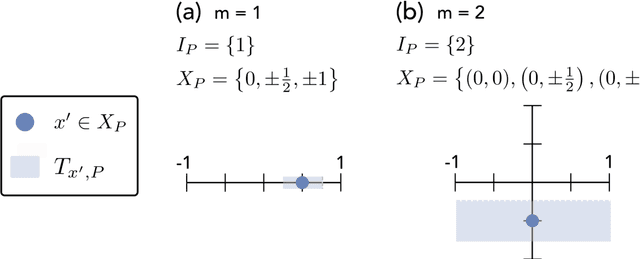
Finding the ground state of a quantum many-body system is a fundamental problem in quantum physics. In this work, we give a classical machine learning (ML) algorithm for predicting ground state properties with an inductive bias encoding geometric locality. The proposed ML model can efficiently predict ground state properties of an $n$-qubit gapped local Hamiltonian after learning from only $\mathcal{O}(\log(n))$ data about other Hamiltonians in the same quantum phase of matter. This improves substantially upon previous results that require $\mathcal{O}(n^c)$ data for a large constant $c$. Furthermore, the training and prediction time of the proposed ML model scale as $\mathcal{O}(n \log n)$ in the number of qubits $n$. Numerical experiments on physical systems with up to 45 qubits confirm the favorable scaling in predicting ground state properties using a small training dataset.