 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Fang
Artwork Protection Against Neural Style Transfer Using Locally Adaptive Adversarial Color Attack
Jan 18, 2024
Neural style transfer (NST) is widely adopted in computer vision to generate new images with arbitrary styles. This process leverages neural networks to merge aesthetic elements of a style image with the structural aspects of a content image into a harmoniously integrated visual result. However, unauthorized NST can exploit artwork. Such misuse raises socio-technical concerns regarding artists' rights and motivates the development of technical approaches for the proactive protection of original creations. Adversarial attack is a concept primarily explored in machine learning security. Our work introduces this technique to protect artists' intellectual property. In this paper Locally Adaptive Adversarial Color Attack (LAACA), a method for altering images in a manner imperceptible to the human eyes but disruptive to NST. Specifically, we design perturbations targeting image areas rich in high-frequency content, generated by disrupting intermediate features. Our experiments and user study confirm that by attacking NST using the proposed method results in visually worse neural style transfer, thus making it an effective solution for visual artwork protection.
Retro-BLEU: Quantifying Chemical Plausibility of Retrosynthesis Routes through Reaction Template Sequence Analysis
Nov 08, 2023Computer-assisted methods have emerged as valuable tools for retrosynthesis analysis. However, quantifying the plausibility of generated retrosynthesis routes remains a challenging task. We introduce Retro-BLEU, a statistical metric adapted from the well-established BLEU score in machine translation, to evaluate the plausibility of retrosynthesis routes based on reaction template sequences analysis. We demonstrate the effectiveness of Retro-BLEU by applying it to a diverse set of retrosynthesis routes generated by state-of-the-art algorithms and compare the performance with other evaluation metrics. The results show that Retro-BLEU is capable of differentiating between plausible and implausible routes. Furthermore, we provide insights into the strengths and weaknesses of Retro-BLEU, paving the way for future developments and improvements in this field.
A White-Box False Positive Adversarial Attack Method on Contrastive Loss-Based Offline Handwritten Signature Verification Models
Aug 17, 2023



In this paper, we tackle the challenge of white-box false positive adversarial attacks on contrastive loss-based offline handwritten signature verification models. We propose a novel attack method that treats the attack as a style transfer between closely related but distinct writing styles. To guide the generation of deceptive images, we introduce two new loss functions that enhance the attack success rate by perturbing the Euclidean distance between the embedding vectors of the original and synthesized samples, while ensuring minimal perturbations by reducing the difference between the generated image and the original image. Our method demonstrates state-of-the-art performance in white-box attacks on contrastive loss-based offline handwritten signature verification models, as evidenced by our experiments. The key contributions of this paper include a novel false positive attack method, two new loss functions, effective style transfer in handwriting styles, and superior performance in white-box false positive attacks compared to other white-box attack methods.
Part & Whole Extraction: Towards A Deep Understanding of Quantitative Facts for Percentages in Text
Oct 26, 2021



We study the problem of quantitative facts extraction for text with percentages. For example, given the sentence "30 percent of Americans like watching football, while 20% prefer to watch NBA.", our goal is to obtain a deep understanding of the percentage numbers ("30 percent" and "20%") by extracting their quantitative facts: part ("like watching football" and "prefer to watch NBA") and whole ("Americans). These quantitative facts can empower new applications like automated infographic generation. We formulate part and whole extraction as a sequence tagging problem. Due to the large gap between part/whole and its corresponding percentage, we introduce skip mechanism in sequence modeling, and achieved improved performance on both our task and the CoNLL-2003 named entity recognition task. Experimental results demonstrate that learning to skip in sequence tagging is promising.
A Split-and-Recombine Approach for Follow-up Query Analysis
Sep 19, 2019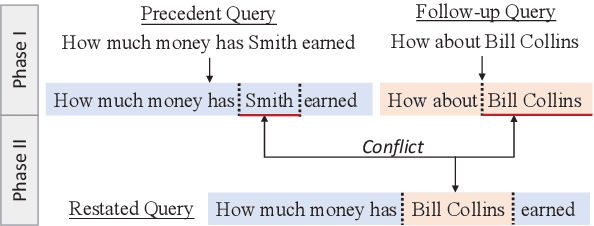

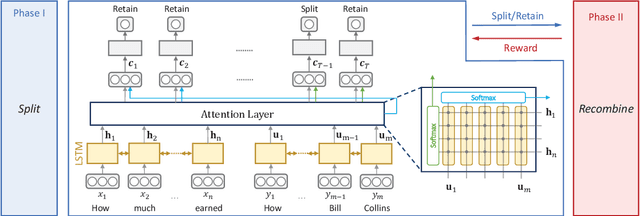
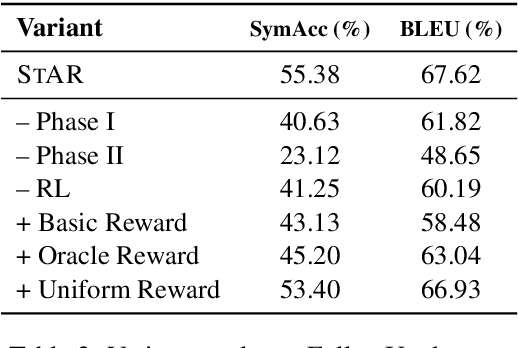
Context-dependent semantic parsing has proven to be an important yet challenging task. To leverage the advances in context-independent semantic parsing, we propose to perform follow-up query analysis, aiming to restate context-dependent natural language queries with contextual information. To accomplish the task, we propose STAR, a novel approach with a well-designed two-phase process. It is parser-independent and able to handle multifarious follow-up scenarios in different domains. Experiments on the FollowUp dataset show that STAR outperforms the state-of-the-art baseline by a large margin of nearly 8%. The superiority on parsing results verifies the feasibility of follow-up query analysis. We also explore the extensibility of STAR on the SQA dataset, which is very promising.