 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi-Heng Lin
Distilling and Retrieving Generalizable Knowledge for Robot Manipulation via Language Corrections
Nov 17, 2023
Today's robot policies exhibit subpar performance when faced with the challenge of generalizing to novel environments. Human corrective feedback is a crucial form of guidance to enable such generalization. However, adapting to and learning from online human corrections is a non-trivial endeavor: not only do robots need to remember human feedback over time to retrieve the right information in new settings and reduce the intervention rate, but also they would need to be able to respond to feedback that can be arbitrary corrections about high-level human preferences to low-level adjustments to skill parameters. In this work, we present Distillation and Retrieval of Online Corrections (DROC), a large language model (LLM)-based system that can respond to arbitrary forms of language feedback, distill generalizable knowledge from corrections, and retrieve relevant past experiences based on textual and visual similarity for improving performance in novel settings. DROC is able to respond to a sequence of online language corrections that address failures in both high-level task plans and low-level skill primitives. We demonstrate that DROC effectively distills the relevant information from the sequence of online corrections in a knowledge base and retrieves that knowledge in settings with new task or object instances. DROC outperforms other techniques that directly generate robot code via LLMs by using only half of the total number of corrections needed in the first round and requires little to no corrections after two iterations. We show further results, videos, prompts and code on https://sites.google.com/stanford.edu/droc .
Gesture-Informed Robot Assistance via Foundation Models
Sep 07, 2023

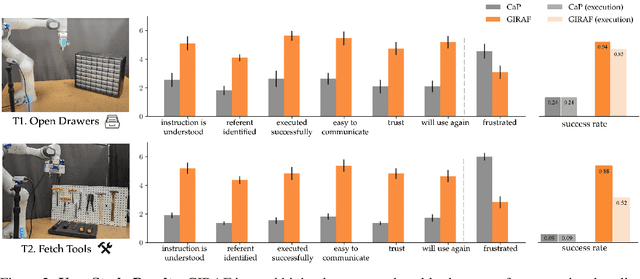
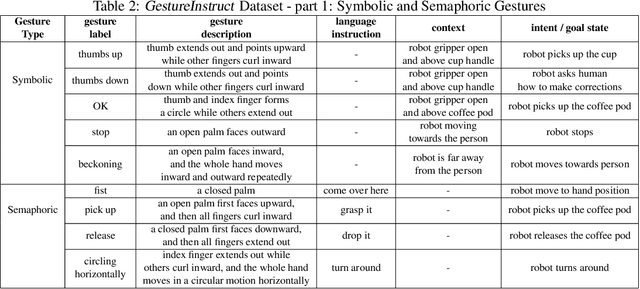
Gestures serve as a fundamental and significant mode of non-verbal communication among humans. Deictic gestures (such as pointing towards an object), in particular, offer valuable means of efficiently expressing intent in situations where language is inaccessible, restricted, or highly specialized. As a result, it is essential for robots to comprehend gestures in order to infer human intentions and establish more effective coordination with them. Prior work often rely on a rigid hand-coded library of gestures along with their meanings. However, interpretation of gestures is often context-dependent, requiring more flexibility and common-sense reasoning. In this work, we propose a framework, GIRAF, for more flexibly interpreting gesture and language instructions by leveraging the power of large language models. Our framework is able to accurately infer human intent and contextualize the meaning of their gestures for more effective human-robot collaboration. We instantiate the framework for interpreting deictic gestures in table-top manipulation tasks and demonstrate that it is both effective and preferred by users, achieving 70% higher success rates than the baseline. We further demonstrate GIRAF's ability on reasoning about diverse types of gestures by curating a GestureInstruct dataset consisting of 36 different task scenarios. GIRAF achieved 81% success rate on finding the correct plan for tasks in GestureInstruct. Website: https://tinyurl.com/giraf23