 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLida Chen
From Persona to Personalization: A Survey on Role-Playing Language Agents
Apr 28, 2024
Recent advancements in large language models (LLMs) have significantly boosted the rise of Role-Playing Language Agents (RPLAs), i.e., specialized AI systems designed to simulate assigned personas. By harnessing multiple advanced abilities of LLMs, including in-context learning, instruction following, and social intelligence, RPLAs achieve a remarkable sense of human likeness and vivid role-playing performance. RPLAs can mimic a wide range of personas, ranging from historical figures and fictional characters to real-life individuals. Consequently, they have catalyzed numerous AI applications, such as emotional companions, interactive video games, personalized assistants and copilots, and digital clones. In this paper, we conduct a comprehensive survey of this field, illustrating the evolution and recent progress in RPLAs integrating with cutting-edge LLM technologies. We categorize personas into three types: 1) Demographic Persona, which leverages statistical stereotypes; 2) Character Persona, focused on well-established figures; and 3) Individualized Persona, customized through ongoing user interactions for personalized services. We begin by presenting a comprehensive overview of current methodologies for RPLAs, followed by the details for each persona type, covering corresponding data sourcing, agent construction, and evaluation. Afterward, we discuss the fundamental risks, existing limitations, and future prospects of RPLAs. Additionally, we provide a brief review of RPLAs in AI applications, which reflects practical user demands that shape and drive RPLA research. Through this work, we aim to establish a clear taxonomy of RPLA research and applications, and facilitate future research in this critical and ever-evolving field, and pave the way for a future where humans and RPLAs coexist in harmony.
SurveyAgent: A Conversational System for Personalized and Efficient Research Survey
Apr 09, 2024In the rapidly advancing research fields such as AI, managing and staying abreast of the latest scientific literature has become a significant challenge for researchers. Although previous efforts have leveraged AI to assist with literature searches, paper recommendations, and question-answering, a comprehensive support system that addresses the holistic needs of researchers has been lacking. This paper introduces SurveyAgent, a novel conversational system designed to provide personalized and efficient research survey assistance to researchers. SurveyAgent integrates three key modules: Knowledge Management for organizing papers, Recommendation for discovering relevant literature, and Query Answering for engaging with content on a deeper level. This system stands out by offering a unified platform that supports researchers through various stages of their literature review process, facilitated by a conversational interface that prioritizes user interaction and personalization. Our evaluation demonstrates SurveyAgent's effectiveness in streamlining research activities, showcasing its capability to facilitate how researchers interact with scientific literature.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023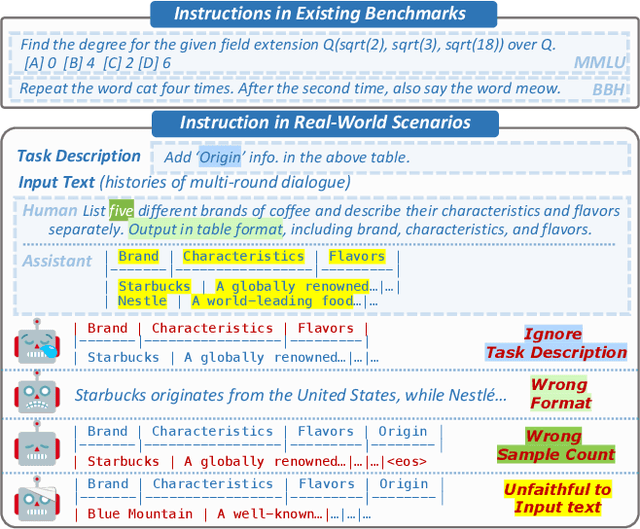
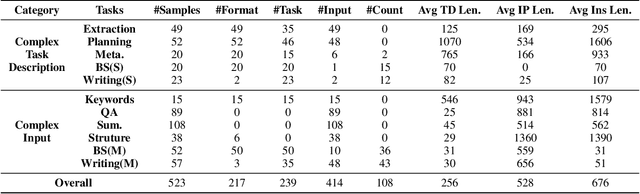

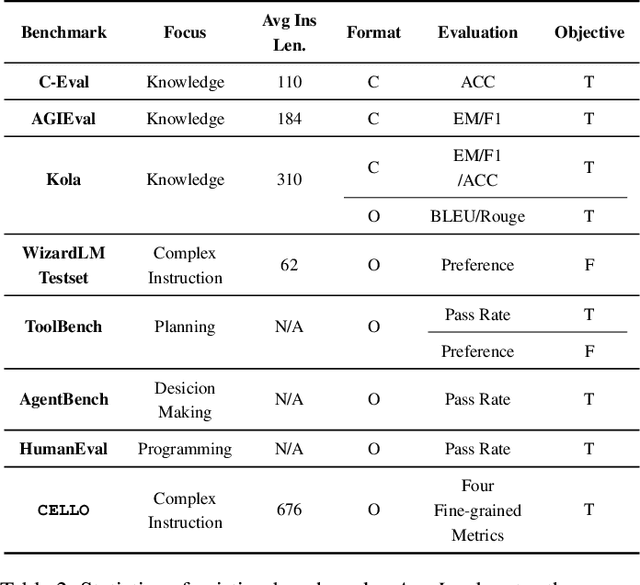
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.