 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidan Shou
FL-GUARD: A Holistic Framework for Run-Time Detection and Recovery of Negative Federated Learning
Mar 07, 2024
Federated learning (FL) is a promising approach for learning a model from data distributed on massive clients without exposing data privacy. It works effectively in the ideal federation where clients share homogeneous data distribution and learning behavior. However, FL may fail to function appropriately when the federation is not ideal, amid an unhealthy state called Negative Federated Learning (NFL), in which most clients gain no benefit from participating in FL. Many studies have tried to address NFL. However, their solutions either (1) predetermine to prevent NFL in the entire learning life-cycle or (2) tackle NFL in the aftermath of numerous learning rounds. Thus, they either (1) indiscriminately incur extra costs even if FL can perform well without such costs or (2) waste numerous learning rounds. Additionally, none of the previous work takes into account the clients who may be unwilling/unable to follow the proposed NFL solutions when using those solutions to upgrade an FL system in use. This paper introduces FL-GUARD, a holistic framework that can be employed on any FL system for tackling NFL in a run-time paradigm. That is, to dynamically detect NFL at the early stage (tens of rounds) of learning and then to activate recovery measures when necessary. Specifically, we devise a cost-effective NFL detection mechanism, which relies on an estimation of performance gain on clients. Only when NFL is detected, we activate the NFL recovery process, in which each client learns in parallel an adapted model when training the global model. Extensive experiment results confirm the effectiveness of FL-GUARD in detecting NFL and recovering from NFL to a healthy learning state. We also show that FL-GUARD is compatible with previous NFL solutions and robust against clients unwilling/unable to take any recovery measures.
CARAT: Contrastive Feature Reconstruction and Aggregation for Multi-modal Multi-label Emotion Recognition
Dec 29, 2023Multi-modal multi-label emotion recognition (MMER) aims to identify relevant emotions from multiple modalities. The challenge of MMER is how to effectively capture discriminative features for multiple labels from heterogeneous data. Recent studies are mainly devoted to exploring various fusion strategies to integrate multi-modal information into a unified representation for all labels. However, such a learning scheme not only overlooks the specificity of each modality but also fails to capture individual discriminative features for different labels. Moreover, dependencies of labels and modalities cannot be effectively modeled. To address these issues, this paper presents ContrAstive feature Reconstruction and AggregaTion (CARAT) for the MMER task. Specifically, we devise a reconstruction-based fusion mechanism to better model fine-grained modality-to-label dependencies by contrastively learning modal-separated and label-specific features. To further exploit the modality complementarity, we introduce a shuffle-based aggregation strategy to enrich co-occurrence collaboration among labels. Experiments on two benchmark datasets CMU-MOSEI and M3ED demonstrate the effectiveness of CARAT over state-of-the-art methods. Code is available at https://github.com/chengzju/CARAT.
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Sep 15, 2023
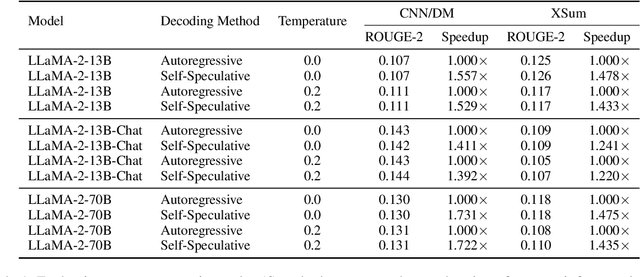
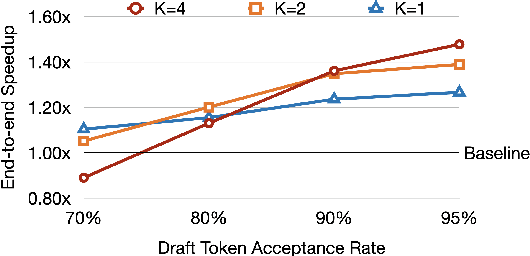

We present a novel inference scheme, self-speculative decoding, for accelerating Large Language Models (LLMs) without the need for an auxiliary model. This approach is characterized by a two-stage process: drafting and verification. The drafting stage generates draft tokens at a slightly lower quality but more quickly, which is achieved by selectively skipping certain intermediate layers during drafting Subsequently, the verification stage employs the original LLM to validate those draft output tokens in one forward pass. This process ensures the final output remains identical to that produced by the unaltered LLM, thereby maintaining output quality. The proposed method requires no additional neural network training and no extra memory footprint, making it a plug-and-play and cost-effective solution for inference acceleration. Benchmarks with LLaMA-2 and its fine-tuned models demonstrated a speedup up to 1.73$\times$.
LINDT: Tackling Negative Federated Learning with Local Adaptation
Nov 23, 2020



Federated Learning (FL) is a promising distributed learning paradigm, which allows a number of data owners (also called clients) to collaboratively learn a shared model without disclosing each client's data. However, FL may fail to proceed properly, amid a state that we call negative federated learning (NFL). This paper addresses the problem of negative federated learning. We formulate a rigorous definition of NFL and analyze its essential cause. We propose a novel framework called LINDT for tackling NFL in run-time. The framework can potentially work with any neural-network-based FL systems for NFL detection and recovery. Specifically, we introduce a metric for detecting NFL from the server. On occasion of NFL recovery, the framework makes adaptation to the federated model on each client's local data by learning a Layer-wise Intertwined Dual-model. Experiment results show that the proposed approach can significantly improve the performance of FL on local data in various scenarios of NFL.
Semi-Supervised Few-Shot Learning for Dual Question-Answer Extraction
Apr 08, 2019



This paper addresses the problem of key phrase extraction from sentences. Existing state-of-the-art supervised methods require large amounts of annotated data to achieve good performance and generalization. Collecting labeled data is, however, often expensive. In this paper, we redefine the problem as question-answer extraction, and present SAMIE: Self-Asking Model for Information Ixtraction, a semi-supervised model which dually learns to ask and to answer questions by itself. Briefly, given a sentence $s$ and an answer $a$, the model needs to choose the most appropriate question $\hat q$; meanwhile, for the given sentence $s$ and same question $\hat q$ selected in the previous step, the model will predict an answer $\hat a$. The model can support few-shot learning with very limited supervision. It can also be used to perform clustering analysis when no supervision is provided. Experimental results show that the proposed method outperforms typical supervised methods especially when given little labeled data.