 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLihao Wang
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Mar 21, 2024

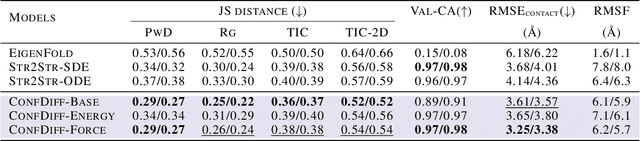
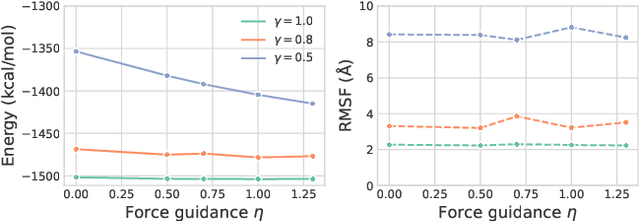
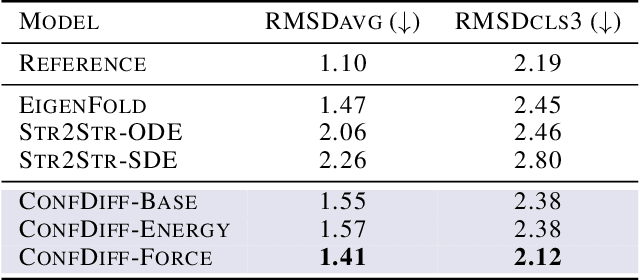
The conformational landscape of proteins is crucial to understanding their functionality in complex biological processes. Traditional physics-based computational methods, such as molecular dynamics (MD) simulations, suffer from rare event sampling and long equilibration time problems, hindering their applications in general protein systems. Recently, deep generative modeling techniques, especially diffusion models, have been employed to generate novel protein conformations. However, existing score-based diffusion methods cannot properly incorporate important physical prior knowledge to guide the generation process, causing large deviations in the sampled protein conformations from the equilibrium distribution. In this paper, to overcome these limitations, we propose a force-guided SE(3) diffusion model, ConfDiff, for protein conformation generation. By incorporating a force-guided network with a mixture of data-based score models, ConfDiff can can generate protein conformations with rich diversity while preserving high fidelity. Experiments on a variety of protein conformation prediction tasks, including 12 fast-folding proteins and the Bovine Pancreatic Trypsin Inhibitor (BPTI), demonstrate that our method surpasses the state-of-the-art method.
Holistic Parking Slot Detection with Polygon-Shaped Representations
Oct 17, 2023Current parking slot detection in advanced driver-assistance systems (ADAS) primarily relies on ultrasonic sensors. This method has several limitations such as the need to scan the entire parking slot before detecting it, the incapacity of detecting multiple slots in a row, and the difficulty of classifying them. Due to the complex visual environment, vehicles are equipped with surround view camera systems to detect vacant parking slots. Previous research works in this field mostly use image-domain models to solve the problem. These two-stage approaches separate the 2D detection and 3D pose estimation steps using camera calibration. In this paper, we propose one-step Holistic Parking Slot Network (HPS-Net), a tailor-made adaptation of the You Only Look Once (YOLO)v4 algorithm. This camera-based approach directly outputs the four vertex coordinates of the parking slot in topview domain, instead of a bounding box in raw camera images. Several visible points and shapes can be proposed from different angles. A novel regression loss function named polygon-corner Generalized Intersection over Union (GIoU) for polygon vertex position optimization is also proposed to manage the slot orientation and to distinguish the entrance line. Experiments show that HPS-Net can detect various vacant parking slots with a F1-score of 0.92 on our internal Valeo Parking Slots Dataset (VPSD) and 0.99 on the public dataset PS2.0. It provides a satisfying generalization and robustness in various parking scenarios, such as indoor (F1: 0.86) or paved ground (F1: 0.91). Moreover, it achieves a real-time detection speed of 17 FPS on Nvidia Drive AGX Xavier. A demo video can be found at https://streamable.com/75j7sj.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023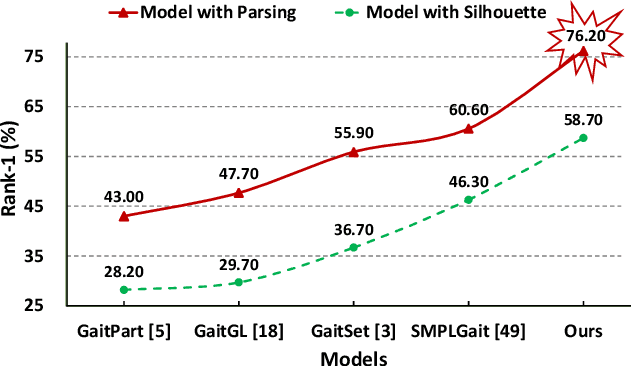
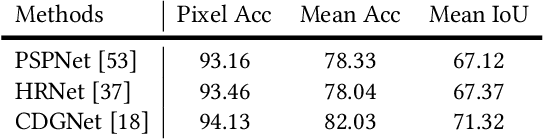
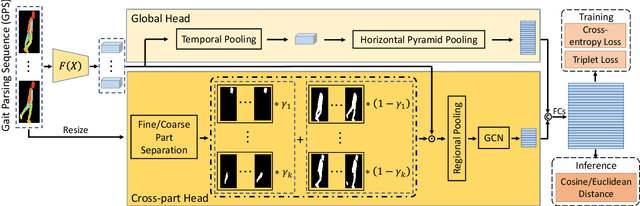
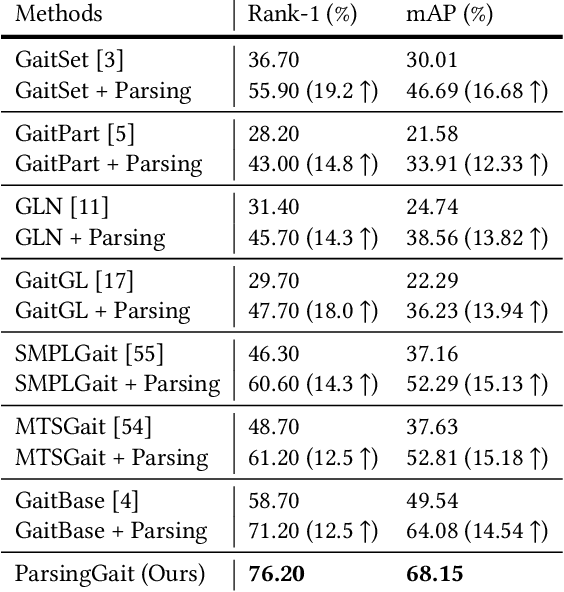
Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
Learning Harmonic Molecular Representations on Riemannian Manifold
Mar 27, 2023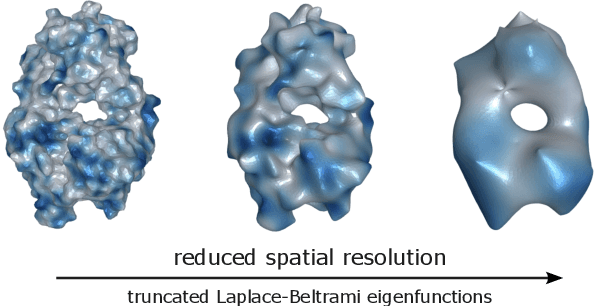
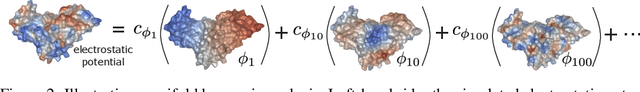
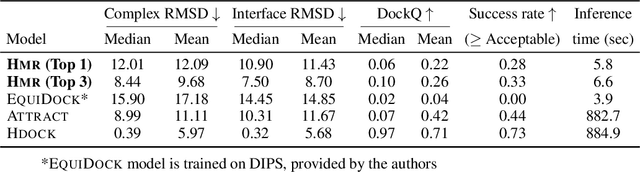
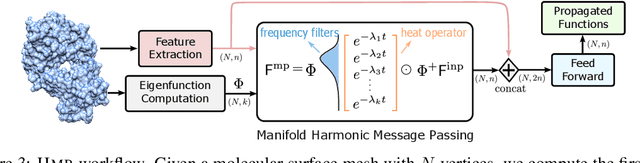
Molecular representation learning plays a crucial role in AI-assisted drug discovery research. Encoding 3D molecular structures through Euclidean neural networks has become the prevailing method in the geometric deep learning community. However, the equivariance constraints and message passing in Euclidean space may limit the network expressive power. In this work, we propose a Harmonic Molecular Representation learning (HMR) framework, which represents a molecule using the Laplace-Beltrami eigenfunctions of its molecular surface. HMR offers a multi-resolution representation of molecular geometric and chemical features on 2D Riemannian manifold. We also introduce a harmonic message passing method to realize efficient spectral message passing over the surface manifold for better molecular encoding. Our proposed method shows comparable predictive power to current models in small molecule property prediction, and outperforms the state-of-the-art deep learning models for ligand-binding protein pocket classification and the rigid protein docking challenge, demonstrating its versatility in molecular representation learning.
Unsupervised Word Segmentation with Bi-directional Neural Language Model
Mar 02, 2021



We present an unsupervised word segmentation model, in which the learning objective is to maximize the generation probability of a sentence given its all possible segmentation. Such generation probability can be factorized into the likelihood of each possible segment given the context in a recursive way. In order to better capture the long- and short-term dependencies, we propose to use bi-directional neural language models to better capture the features of segment's context. Two decoding algorithms are also described to combine the context features from both directions to generate the final segmentation, which helps to reconcile word boundary ambiguities. Experimental results showed that our context-sensitive unsupervised segmentation model achieved state-of-the-art at different evaluation settings on various data sets for Chinese, and the comparable result for Thai.