 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLijun Zhang
To Cool or not to Cool? Temperature Network Meets Large Foundation Models via DRO
Apr 06, 2024
The temperature parameter plays a profound role during training and/or inference with large foundation models (LFMs) such as large language models (LLMs) and CLIP models. Particularly, it adjusts the logits in the softmax function in LLMs, which is crucial for next token generation, and it scales the similarities in the contrastive loss for training CLIP models. A significant question remains: Is it viable to learn a neural network to predict a personalized temperature of any input data for enhancing LFMs"? In this paper, we present a principled framework for learning a small yet generalizable temperature prediction network (TempNet) to improve LFMs. Our solution is composed of a novel learning framework with a robust loss underpinned by constrained distributionally robust optimization (DRO), and a properly designed TempNet with theoretical inspiration. TempNet can be trained together with a large foundation model from scratch or learned separately given a pretrained foundation model. It is not only useful for predicting personalized temperature to promote the training of LFMs but also generalizable and transferable to new tasks. Our experiments on LLMs and CLIP models demonstrate that TempNet greatly improves the performance of existing solutions or models, e.g. Table 1. The code to reproduce the experimental results in this paper can be found at https://github.com/zhqiu/TempNet.
ADVREPAIR:Provable Repair of Adversarial Attack
Apr 02, 2024Deep neural networks (DNNs) are increasingly deployed in safety-critical domains, but their vulnerability to adversarial attacks poses serious safety risks. Existing neuron-level methods using limited data lack efficacy in fixing adversaries due to the inherent complexity of adversarial attack mechanisms, while adversarial training, leveraging a large number of adversarial samples to enhance robustness, lacks provability. In this paper, we propose ADVREPAIR, a novel approach for provable repair of adversarial attacks using limited data. By utilizing formal verification, ADVREPAIR constructs patch modules that, when integrated with the original network, deliver provable and specialized repairs within the robustness neighborhood. Additionally, our approach incorporates a heuristic mechanism for assigning patch modules, allowing this defense against adversarial attacks to generalize to other inputs. ADVREPAIR demonstrates superior efficiency, scalability and repair success rate. Different from existing DNN repair methods, our repair can generalize to general inputs, thereby improving the robustness of the neural network globally, which indicates a significant breakthrough in the generalization capability of ADVREPAIR.
DeepCDCL: An CDCL-based Neural Network Verification Framework
Mar 12, 2024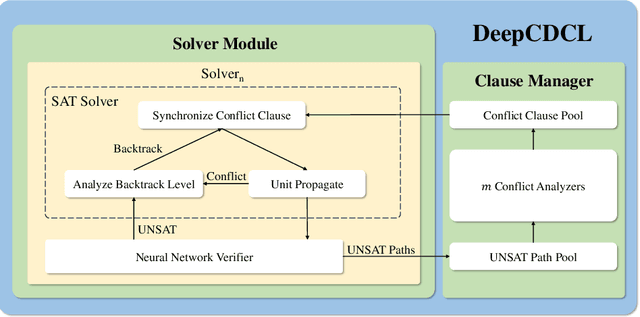
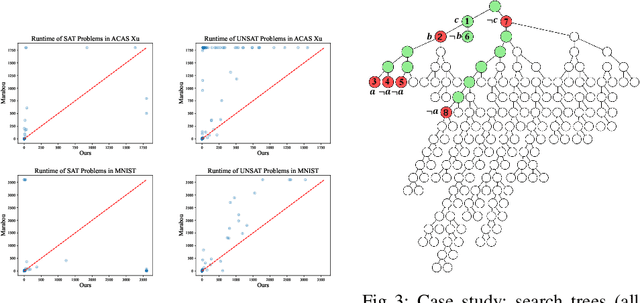
Neural networks in safety-critical applications face increasing safety and security concerns due to their susceptibility to little disturbance. In this paper, we propose DeepCDCL, a novel neural network verification framework based on the Conflict-Driven Clause Learning (CDCL) algorithm. We introduce an asynchronous clause learning and management structure, reducing redundant time consumption compared to the direct application of the CDCL framework. Furthermore, we also provide a detailed evaluation of the performance of our approach on the ACAS Xu and MNIST datasets, showing that a significant speed-up is achieved in most cases.
Efficient Algorithms for Empirical Group Distributional Robust Optimization and Beyond
Mar 06, 2024
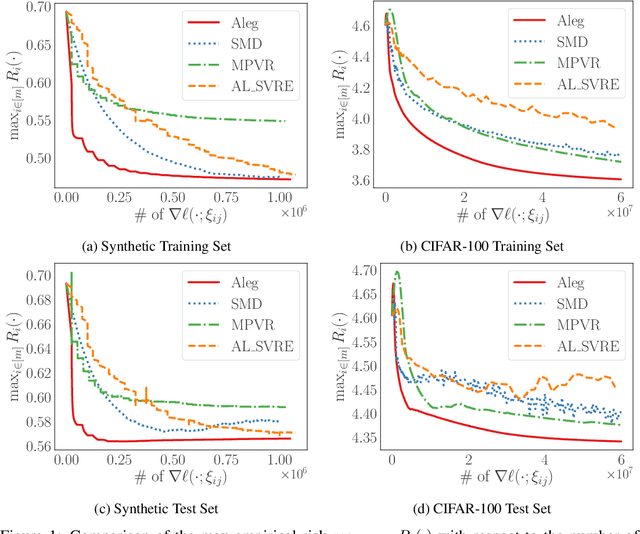
We investigate the empirical counterpart of group distributionally robust optimization (GDRO), which aims to minimize the maximal empirical risk across $m$ distinct groups. We formulate empirical GDRO as a $\textit{two-level}$ finite-sum convex-concave minimax optimization problem and develop a stochastic variance reduced mirror prox algorithm. Unlike existing methods, we construct the stochastic gradient by per-group sampling technique and perform variance reduction for all groups, which fully exploits the $\textit{two-level}$ finite-sum structure of empirical GDRO. Furthermore, we compute the snapshot and mirror snapshot point by a one-index-shifted weighted average, which distinguishes us from the naive ergodic average. Our algorithm also supports non-constant learning rates, which is different from existing literature. We establish convergence guarantees both in expectation and with high probability, demonstrating a complexity of $\mathcal{O}\left(\frac{m\sqrt{\bar{n}\ln{m}}}{\varepsilon}\right)$, where $\bar n$ is the average number of samples among $m$ groups. Remarkably, our approach outperforms the state-of-the-art method by a factor of $\sqrt{m}$. Furthermore, we extend our methodology to deal with the empirical minimax excess risk optimization (MERO) problem and manage to give the expectation bound and the high probability bound, accordingly. The complexity of our empirical MERO algorithm matches that of empirical GDRO at $\mathcal{O}\left(\frac{m\sqrt{\bar{n}\ln{m}}}{\varepsilon}\right)$, significantly surpassing the bounds of existing methods.
CricaVPR: Cross-image Correlation-aware Representation Learning for Visual Place Recognition
Feb 29, 2024Over the past decade, most methods in visual place recognition (VPR) have used neural networks to produce feature representations. These networks typically produce a global representation of a place image using only this image itself and neglect the cross-image variations (e.g. viewpoint and illumination), which limits their robustness in challenging scenes. In this paper, we propose a robust global representation method with cross-image correlation awareness for VPR, named CricaVPR. Our method uses the self-attention mechanism to correlate multiple images within a batch. These images can be taken in the same place with different conditions or viewpoints, or even captured from different places. Therefore, our method can utilize the cross-image variations as a cue to guide the representation learning, which ensures more robust features are produced. To further facilitate the robustness, we propose a multi-scale convolution-enhanced adaptation method to adapt pre-trained visual foundation models to the VPR task, which introduces the multi-scale local information to further enhance the cross-image correlation-aware representation. Experimental results show that our method outperforms state-of-the-art methods by a large margin with significantly less training time. Our method achieves 94.5% R@1 on Pitts30k using 512-dim global features. The code is released at https://github.com/Lu-Feng/CricaVPR.
Deep Homography Estimation for Visual Place Recognition
Feb 25, 2024Visual place recognition (VPR) is a fundamental task for many applications such as robot localization and augmented reality. Recently, the hierarchical VPR methods have received considerable attention due to the trade-off between accuracy and efficiency. They usually first use global features to retrieve the candidate images, then verify the spatial consistency of matched local features for re-ranking. However, the latter typically relies on the RANSAC algorithm for fitting homography, which is time-consuming and non-differentiable. This makes existing methods compromise to train the network only in global feature extraction. Here, we propose a transformer-based deep homography estimation (DHE) network that takes the dense feature map extracted by a backbone network as input and fits homography for fast and learnable geometric verification. Moreover, we design a re-projection error of inliers loss to train the DHE network without additional homography labels, which can also be jointly trained with the backbone network to help it extract the features that are more suitable for local matching. Extensive experiments on benchmark datasets show that our method can outperform several state-of-the-art methods. And it is more than one order of magnitude faster than the mainstream hierarchical VPR methods using RANSAC. The code is released at https://github.com/Lu-Feng/DHE-VPR.
Towards Seamless Adaptation of Pre-trained Models for Visual Place Recognition
Feb 22, 2024Recent studies show that vision models pre-trained in generic visual learning tasks with large-scale data can provide useful feature representations for a wide range of visual perception problems. However, few attempts have been made to exploit pre-trained foundation models in visual place recognition (VPR). Due to the inherent difference in training objectives and data between the tasks of model pre-training and VPR, how to bridge the gap and fully unleash the capability of pre-trained models for VPR is still a key issue to address. To this end, we propose a novel method to realize seamless adaptation of pre-trained models for VPR. Specifically, to obtain both global and local features that focus on salient landmarks for discriminating places, we design a hybrid adaptation method to achieve both global and local adaptation efficiently, in which only lightweight adapters are tuned without adjusting the pre-trained model. Besides, to guide effective adaptation, we propose a mutual nearest neighbor local feature loss, which ensures proper dense local features are produced for local matching and avoids time-consuming spatial verification in re-ranking. Experimental results show that our method outperforms the state-of-the-art methods with less training data and training time, and uses about only 3% retrieval runtime of the two-stage VPR methods with RANSAC-based spatial verification. It ranks 1st on the MSLS challenge leaderboard (at the time of submission). The code is released at https://github.com/Lu-Feng/SelaVPR.
Nearly Optimal Regret for Decentralized Online Convex Optimization
Feb 14, 2024We investigate decentralized online convex optimization (D-OCO), in which a set of local learners are required to minimize a sequence of global loss functions using only local computations and communications. Previous studies have established $O(n^{5/4}\rho^{-1/2}\sqrt{T})$ and ${O}(n^{3/2}\rho^{-1}\log T)$ regret bounds for convex and strongly convex functions respectively, where $n$ is the number of local learners, $\rho<1$ is the spectral gap of the communication matrix, and $T$ is the time horizon. However, there exist large gaps from the existing lower bounds, i.e., $\Omega(n\sqrt{T})$ for convex functions and $\Omega(n)$ for strongly convex functions. To fill these gaps, in this paper, we first develop novel D-OCO algorithms that can respectively reduce the regret bounds for convex and strongly convex functions to $\tilde{O}(n\rho^{-1/4}\sqrt{T})$ and $\tilde{O}(n\rho^{-1/2}\log T)$. The primary technique is to design an online accelerated gossip strategy that enjoys a faster average consensus among local learners. Furthermore, by carefully exploiting the spectral properties of a specific network topology, we enhance the lower bounds for convex and strongly convex functions to $\Omega(n\rho^{-1/4}\sqrt{T})$ and $\Omega(n\rho^{-1/2})$, respectively. These lower bounds suggest that our algorithms are nearly optimal in terms of $T$, $n$, and $\rho$.
Improved Regret for Bandit Convex Optimization with Delayed Feedback
Feb 14, 2024We investigate bandit convex optimization (BCO) with delayed feedback, where only the loss value of the action is revealed under an arbitrary delay. Previous studies have established a regret bound of $O(T^{3/4}+d^{1/3}T^{2/3})$ for this problem, where $d$ is the maximum delay, by simply feeding delayed loss values to the classical bandit gradient descent (BGD) algorithm. In this paper, we develop a novel algorithm to enhance the regret, which carefully exploits the delayed bandit feedback via a blocking update mechanism. Our analysis first reveals that the proposed algorithm can decouple the joint effect of the delays and bandit feedback on the regret, and improve the regret bound to $O(T^{3/4}+\sqrt{dT})$ for convex functions. Compared with the previous result, our regret matches the $O(T^{3/4})$ regret of BGD in the non-delayed setting for a larger amount of delay, i.e., $d=O(\sqrt{T})$, instead of $d=O(T^{1/4})$. Furthermore, we consider the case with strongly convex functions, and prove that the proposed algorithm can enjoy a better regret bound of $O(T^{2/3}\log^{1/3}T+d\log T)$. Finally, we show that in a special case with unconstrained action sets, it can be simply extended to achieve a regret bound of $O(\sqrt{T\log T}+d\log T)$ for strongly convex and smooth functions.
Robust Image Watermarking using Stable Diffusion
Jan 08, 2024Watermarking images is critical for tracking image provenance and claiming ownership. With the advent of generative models, such as stable diffusion, able to create fake but realistic images, watermarking has become particularly important, e.g., to make generated images reliably identifiable. Unfortunately, the very same stable diffusion technology can remove watermarks injected using existing methods. To address this problem, we present a ZoDiac, which uses a pre-trained stable diffusion model to inject a watermark into the trainable latent space, resulting in watermarks that can be reliably detected in the latent vector, even when attacked. We evaluate ZoDiac on three benchmarks, MS-COCO, DiffusionDB, and WikiArt, and find that ZoDiac is robust against state-of-the-art watermark attacks, with a watermark detection rate over 98% and a false positive rate below 6.4%, outperforming state-of-the-art watermarking methods. Our research demonstrates that stable diffusion is a promising approach to robust watermarking, able to withstand even stable-diffusion-based attacks.