 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLijun Zhao
Fast-Poly: A Fast Polyhedral Framework For 3D Multi-Object Tracking
Mar 20, 2024
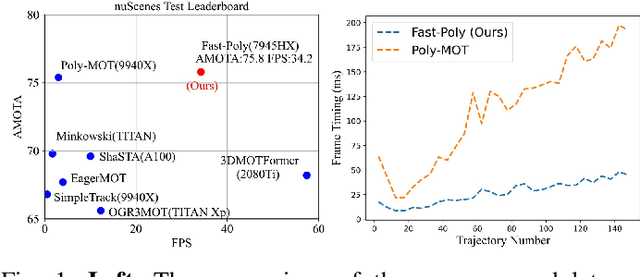
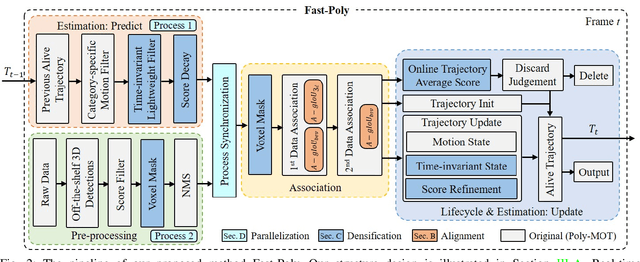
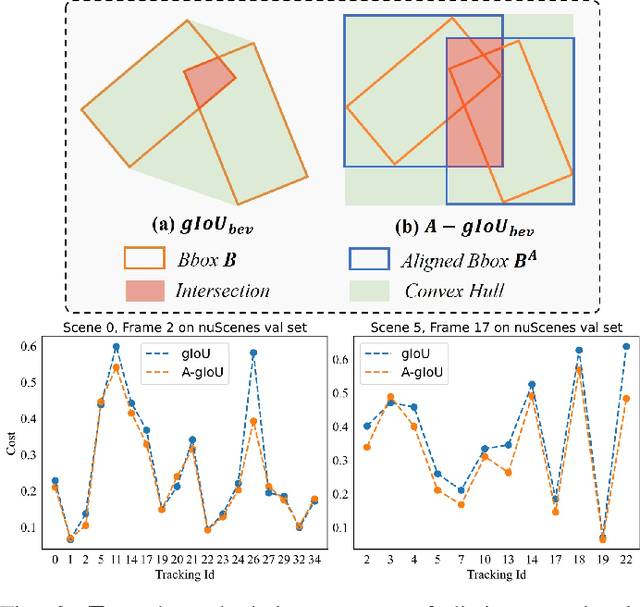
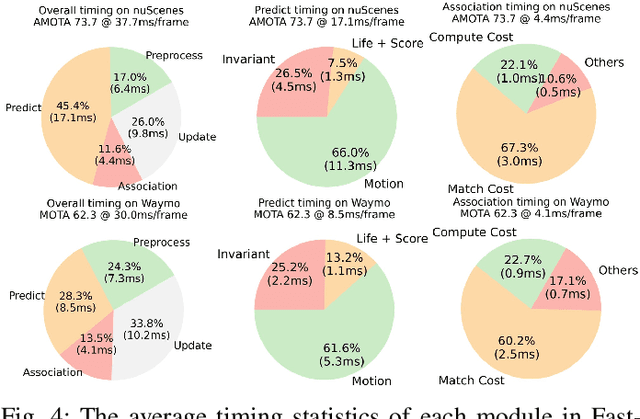
3D Multi-Object Tracking (MOT) captures stable and comprehensive motion states of surrounding obstacles, essential for robotic perception. However, current 3D trackers face issues with accuracy and latency consistency. In this paper, we propose Fast-Poly, a fast and effective filter-based method for 3D MOT. Building upon our previous work Poly-MOT, Fast-Poly addresses object rotational anisotropy in 3D space, enhances local computation densification, and leverages parallelization technique, improving inference speed and precision. Fast-Poly is extensively tested on two large-scale tracking benchmarks with Python implementation. On the nuScenes dataset, Fast-Poly achieves new state-of-the-art performance with 75.8% AMOTA among all methods and can run at 34.2 FPS on a personal CPU. On the Waymo dataset, Fast-Poly exhibits competitive accuracy with 63.6% MOTA and impressive inference speed (35.5 FPS). The source code is publicly available at https://github.com/lixiaoyu2000/FastPoly.
OFVL-MS: Once for Visual Localization across Multiple Indoor Scenes
Aug 23, 2023
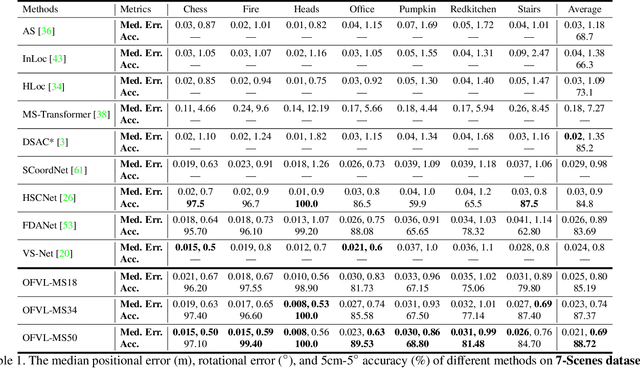

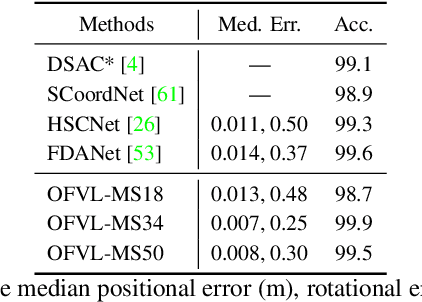
In this work, we seek to predict camera poses across scenes with a multi-task learning manner, where we view the localization of each scene as a new task. We propose OFVL-MS, a unified framework that dispenses with the traditional practice of training a model for each individual scene and relieves gradient conflict induced by optimizing multiple scenes collectively, enabling efficient storage yet precise visual localization for all scenes. Technically, in the forward pass of OFVL-MS, we design a layer-adaptive sharing policy with a learnable score for each layer to automatically determine whether the layer is shared or not. Such sharing policy empowers us to acquire task-shared parameters for a reduction of storage cost and task-specific parameters for learning scene-related features to alleviate gradient conflict. In the backward pass of OFVL-MS, we introduce a gradient normalization algorithm that homogenizes the gradient magnitude of the task-shared parameters so that all tasks converge at the same pace. Furthermore, a sparse penalty loss is applied on the learnable scores to facilitate parameter sharing for all tasks without performance degradation. We conduct comprehensive experiments on multiple benchmarks and our new released indoor dataset LIVL, showing that OFVL-MS families significantly outperform the state-of-the-arts with fewer parameters. We also verify that OFVL-MS can generalize to a new scene with much few parameters while gaining superior localization performance.
Poly-MOT: A Polyhedral Framework For 3D Multi-Object Tracking
Jul 31, 2023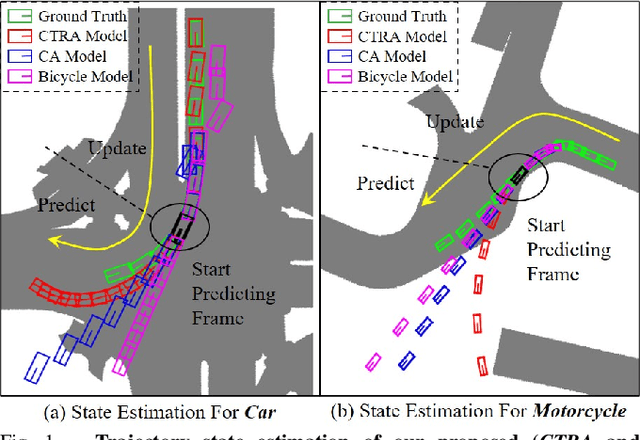
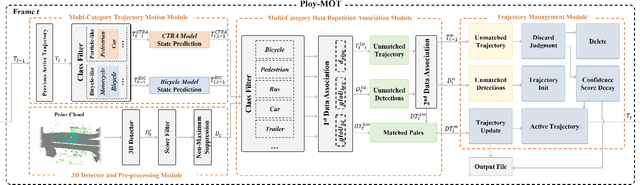
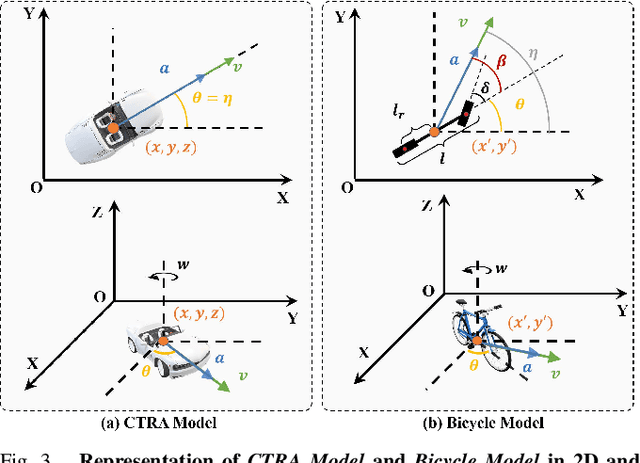

3D Multi-object tracking (MOT) empowers mobile robots to accomplish well-informed motion planning and navigation tasks by providing motion trajectories of surrounding objects. However, existing 3D MOT methods typically employ a single similarity metric and physical model to perform data association and state estimation for all objects. With large-scale modern datasets and real scenes, there are a variety of object categories that commonly exhibit distinctive geometric properties and motion patterns. In this way, such distinctions would enable various object categories to behave differently under the same standard, resulting in erroneous matches between trajectories and detections, and jeopardizing the reliability of downstream tasks (navigation, etc.). Towards this end, we propose Poly-MOT, an efficient 3D MOT method based on the Tracking-By-Detection framework that enables the tracker to choose the most appropriate tracking criteria for each object category. Specifically, Poly-MOT leverages different motion models for various object categories to characterize distinct types of motion accurately. We also introduce the constraint of the rigid structure of objects into a specific motion model to accurately describe the highly nonlinear motion of the object. Additionally, we introduce a two-stage data association strategy to ensure that objects can find the optimal similarity metric from three custom metrics for their categories and reduce missing matches. On the NuScenes dataset, our proposed method achieves state-of-the-art performance with 75.4\% AMOTA. The code is available at https://github.com/lixiaoyu2000/Poly-MOT
OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching
Feb 12, 2023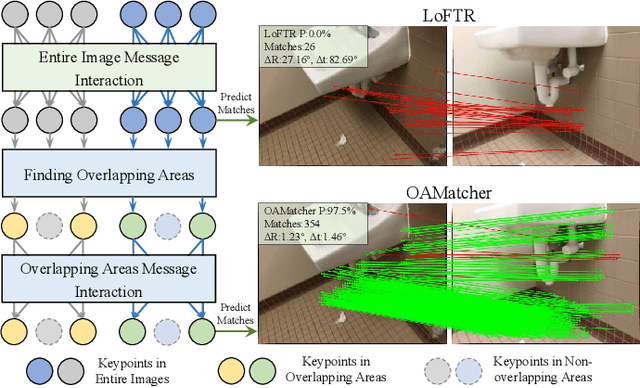
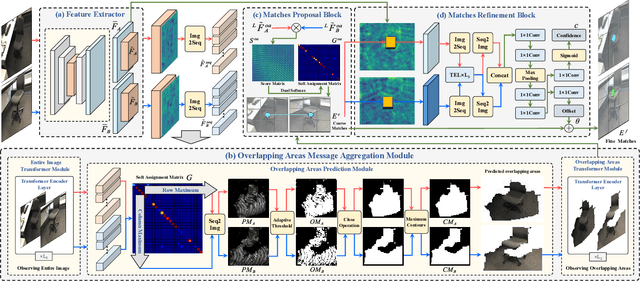
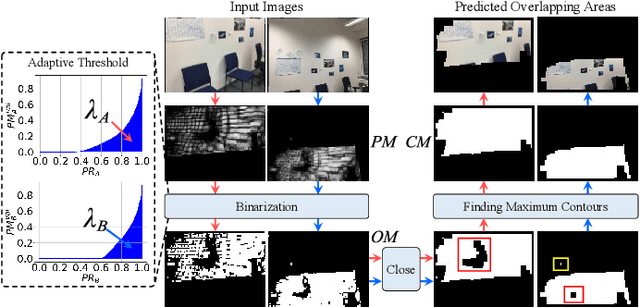

Local feature matching is an essential component in many visual applications. In this work, we propose OAMatcher, a Tranformer-based detector-free method that imitates humans behavior to generate dense and accurate matches. Firstly, OAMatcher predicts overlapping areas to promote effective and clean global context aggregation, with the key insight that humans focus on the overlapping areas instead of the entire images after multiple observations when matching keypoints in image pairs. Technically, we first perform global information integration across all keypoints to imitate the humans behavior of observing the entire images at the beginning of feature matching. Then, we propose Overlapping Areas Prediction Module (OAPM) to capture the keypoints in co-visible regions and conduct feature enhancement among them to simulate that humans transit the focus regions from the entire images to overlapping regions, hence realizeing effective information exchange without the interference coming from the keypoints in non overlapping areas. Besides, since humans tend to leverage probability to determine whether the match labels are correct or not, we propose a Match Labels Weight Strategy (MLWS) to generate the coefficients used to appraise the reliability of the ground-truth match labels, while alleviating the influence of measurement noise coming from the data. Moreover, we integrate depth-wise convolution into Tranformer encoder layers to ensure OAMatcher extracts local and global feature representation concurrently. Comprehensive experiments demonstrate that OAMatcher outperforms the state-of-the-art methods on several benchmarks, while exhibiting excellent robustness to extreme appearance variants. The source code is available at https://github.com/DK-HU/OAMatcher.
DeepMatcher: A Deep Transformer-based Network for Robust and Accurate Local Feature Matching
Jan 08, 2023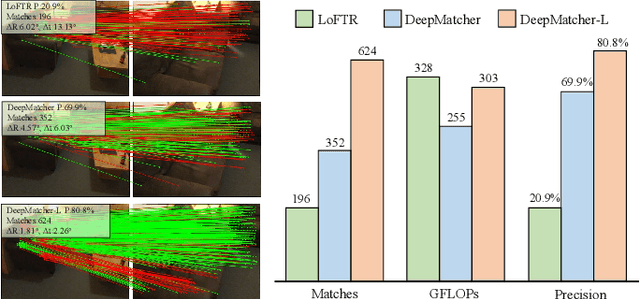
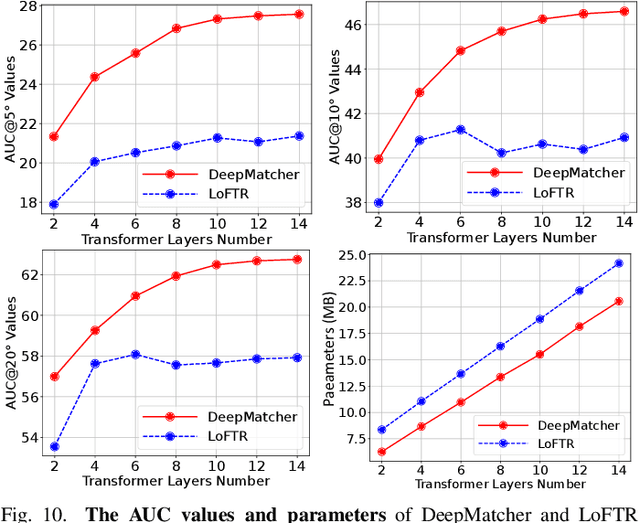
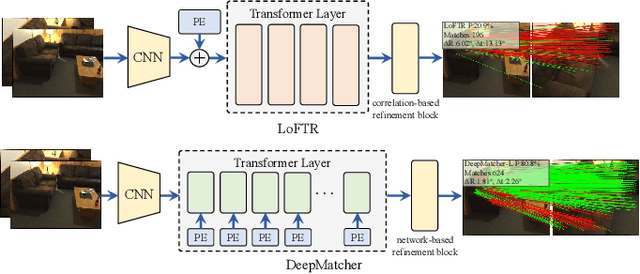
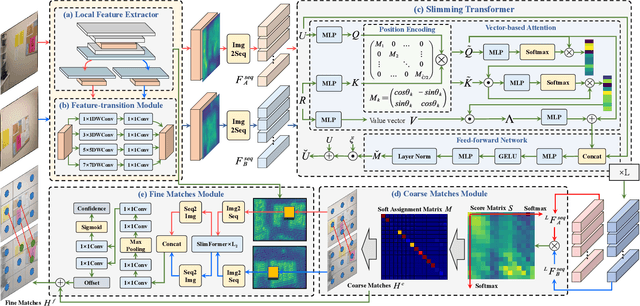
Local feature matching between images remains a challenging task, especially in the presence of significant appearance variations, e.g., extreme viewpoint changes. In this work, we propose DeepMatcher, a deep Transformer-based network built upon our investigation of local feature matching in detector-free methods. The key insight is that local feature matcher with deep layers can capture more human-intuitive and simpler-to-match features. Based on this, we propose a Slimming Transformer (SlimFormer) dedicated for DeepMatcher, which leverages vector-based attention to model relevance among all keypoints and achieves long-range context aggregation in an efficient and effective manner. A relative position encoding is applied to each SlimFormer so as to explicitly disclose relative distance information, further improving the representation of keypoints. A layer-scale strategy is also employed in each SlimFormer to enable the network to assimilate message exchange from the residual block adaptively, thus allowing it to simulate the human behaviour that humans can acquire different matching cues each time they scan an image pair. To facilitate a better adaption of the SlimFormer, we introduce a Feature Transition Module (FTM) to ensure a smooth transition in feature scopes with different receptive fields. By interleaving the self- and cross-SlimFormer multiple times, DeepMatcher can easily establish pixel-wise dense matches at coarse level. Finally, we perceive the match refinement as a combination of classification and regression problems and design Fine Matches Module to predict confidence and offset concurrently, thereby generating robust and accurate matches. Experimentally, we show that DeepMatcher significantly outperforms the state-of-the-art methods on several benchmarks, demonstrating the superior matching capability of DeepMatcher.
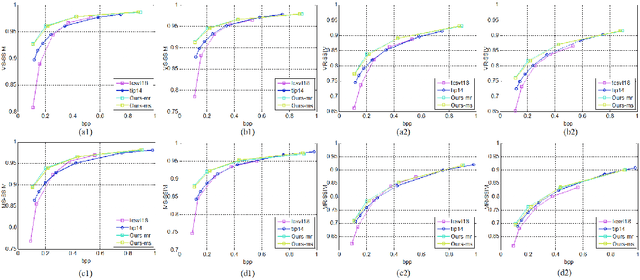
Deep Optimized Multiple Description Image Coding via Scalar Quantization Learning
Jan 12, 2020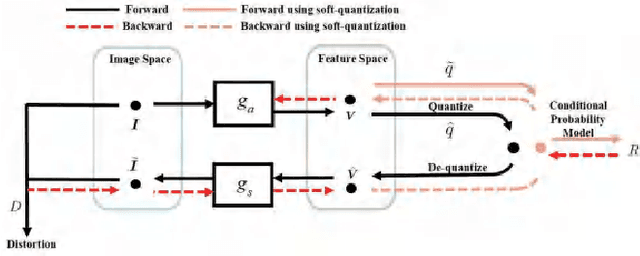

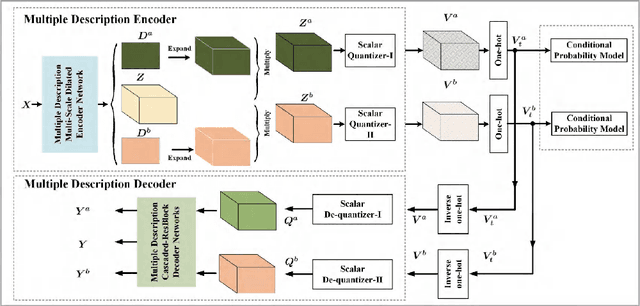

In this paper, we introduce a deep multiple description coding (MDC) framework optimized by minimizing multiple description (MD) compressive loss. First, MD multi-scale-dilated encoder network generates multiple description tensors, which are discretized by scalar quantizers, while these quantized tensors are decompressed by MD cascaded-ResBlock decoder networks. To greatly reduce the total amount of artificial neural network parameters, an auto-encoder network composed of these two types of network is designed as a symmetrical parameter sharing structure. Second, this autoencoder network and a pair of scalar quantizers are simultaneously learned in an end-to-end self-supervised way. Third, considering the variation in the image spatial distribution, each scalar quantizer is accompanied by an importance-indicator map to generate MD tensors, rather than using direct quantization. Fourth, we introduce the multiple description structural similarity distance loss, which implicitly regularizes the diversified multiple description generations, to explicitly supervise multiple description diversified decoding in addition to MD reconstruction loss. Finally, we demonstrate that our MDC framework performs better than several state-of-the-art MDC approaches regarding image coding efficiency when tested on several commonly available datasets.
Concurrently Extrapolating and Interpolating Networks for Continuous Model Generation
Jan 12, 2020



Most deep image smoothing operators are always trained repetitively when different explicit structure-texture pairs are employed as label images for each algorithm configured with different parameters. This kind of training strategy often takes a long time and spends equipment resources in a costly manner. To address this challenging issue, we generalize continuous network interpolation as a more powerful model generation tool, and then propose a simple yet effective model generation strategy to form a sequence of models that only requires a set of specific-effect label images. To precisely learn image smoothing operators, we present a double-state aggregation (DSA) module, which can be easily inserted into most of current network architecture. Based on this module, we design a double-state aggregation neural network structure with a local feature aggregation block and a nonlocal feature aggregation block to obtain operators with large expression capacity. Through the evaluation of many objective and visual experimental results, we show that the proposed method is capable of producing a series of continuous models and achieves better performance than that of several state-of-the-art methods for image smoothing.
Joint Learning of Discriminative Low-dimensional Image Representations Based on Dictionary Learning and Two-layer Orthogonal Projections
Mar 27, 2019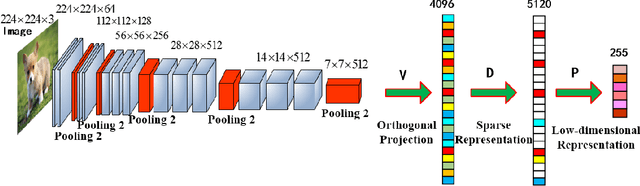
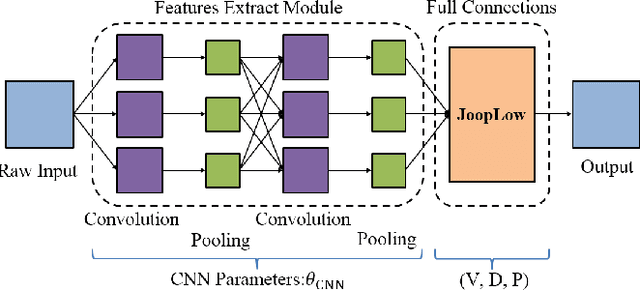
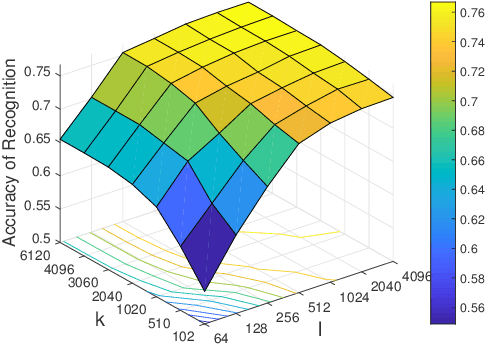
There are some inadequacies in the language description of this paper that require further improvement. This paper is based on a revision of a conference paper. It is now necessary to further explain the difference between the contributions of the two papers.
Deep Multiple Description Coding by Learning Scalar Quantization
Nov 05, 2018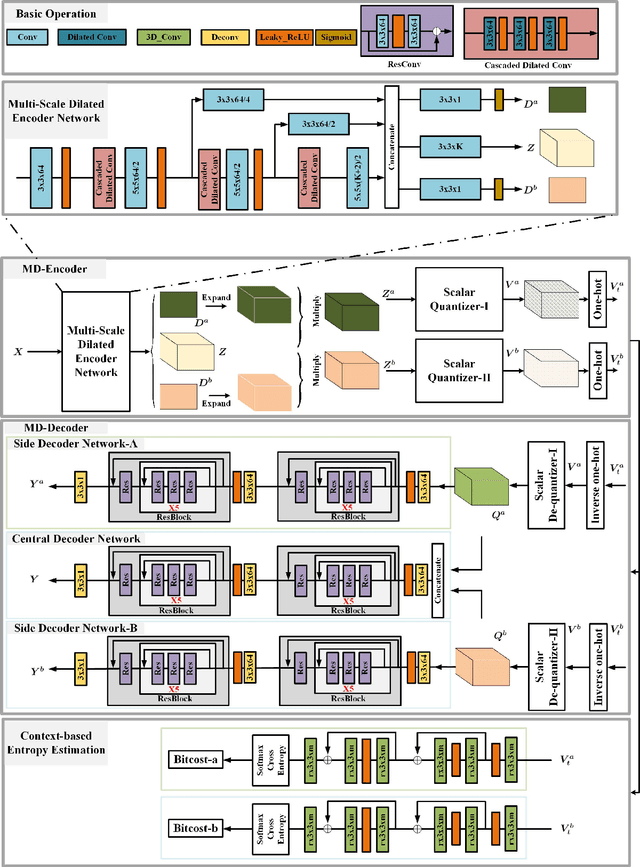


In this paper, we propose a deep multiple description coding framework, whose quantizers are adaptively learned via the minimization of multiple description compressive loss. Firstly, our framework is built upon auto-encoder networks, which have multiple description multi-scale dilated encoder network and multiple description decoder networks. Secondly, two entropy estimation networks are learned to estimate the informative amounts of the quantized tensors, which can further supervise the learning of multiple description encoder network to represent the input image delicately. Thirdly, a pair of scalar quantizers accompanied by two importance-indicator maps is automatically learned in an end-to-end self-supervised way. Finally, multiple description structural dis-similarity distance loss is imposed on multiple description decoded images in pixel domain for diversified multiple description generations rather than on feature tensors in feature domain, in addition to multiple description reconstruction loss. Through testing on two commonly used datasets, it is verified that our method is beyond several state-of-the-art multiple description coding approaches in terms of coding efficiency.
SiftingGAN: Generating and Sifting Labeled Samples to Improve the Remote Sensing Image Scene Classification Baseline in vitro
Sep 20, 2018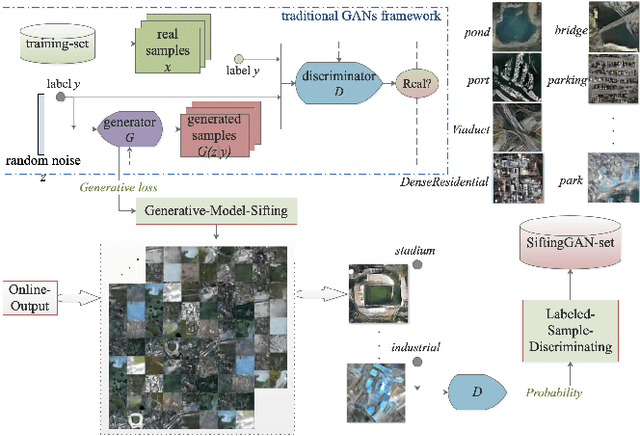
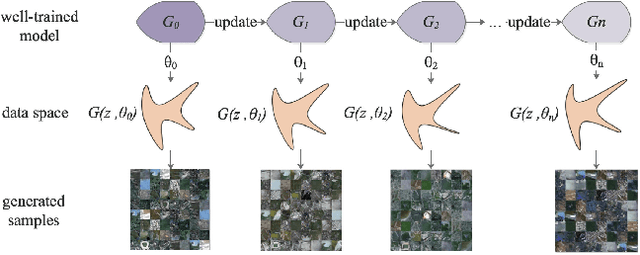
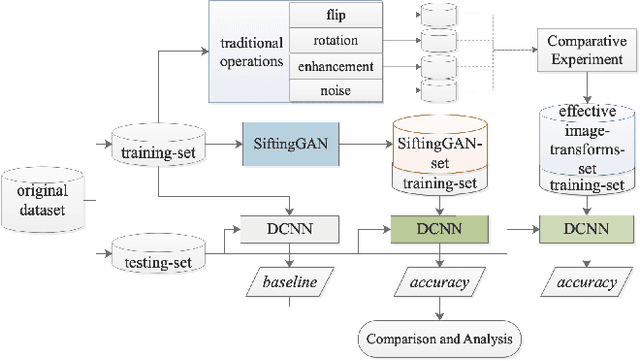
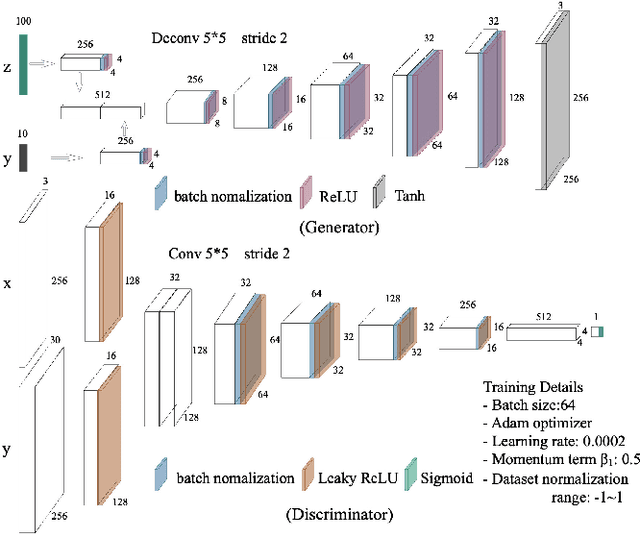
Lack of annotated samples greatly restrains the direct application of deep learning in remote sensing image scene classification. Although researches have been done to tackle this issue by data augmentation with various image transformation operations, they are still limited in quantity and diversity. Recently, the advent of the unsupervised learning based generative adversarial networks (GANs) bring us a new way to generate augmented samples. However, such GAN-generated samples are currently only served for training GANs model itself and for improving the performance of the discriminator in GANs internally (in vivo). It becomes a question of serious doubt whether the GAN-generated samples can help better improve the scene classification performance of other deep learning networks (in vitro), compared with the widely used transformed samples. To answer this question, this paper proposes a SiftingGAN approach to generate more numerous, more diverse and more authentic labeled samples for data augmentation. SiftingGAN extends traditional GAN framework with an Online-Output method for sample generation, a Generative-Model-Sifting method for model sifting, and a Labeled-Sample-Discriminating method for sample sifting. Experiments on the well-known AID dataset demonstrate that the proposed SiftingGAN method can not only effectively improve the performance of the scene classification baseline that is achieved without data augmentation, but also significantly excels the comparison methods based on traditional geometric/radiometric transformation operations.