 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing Huang
A review of uncertainty quantification in medical image analysis: probabilistic and non-probabilistic methods
Oct 09, 2023
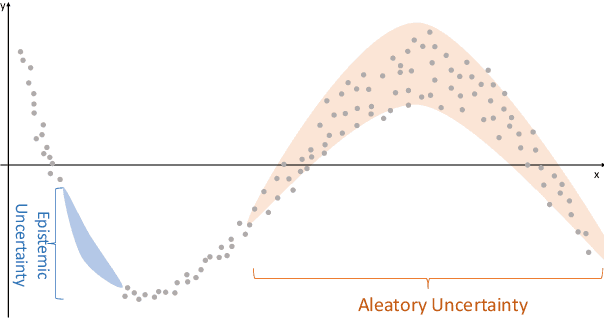
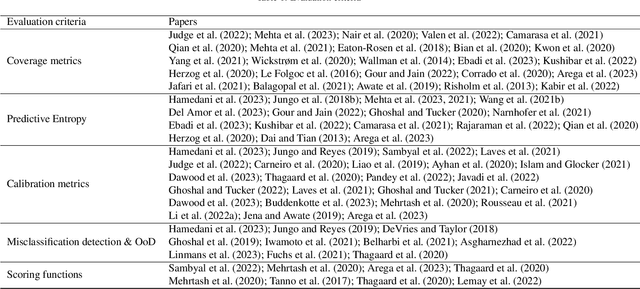
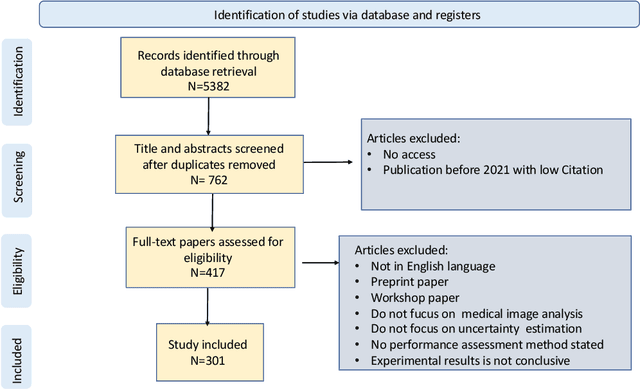
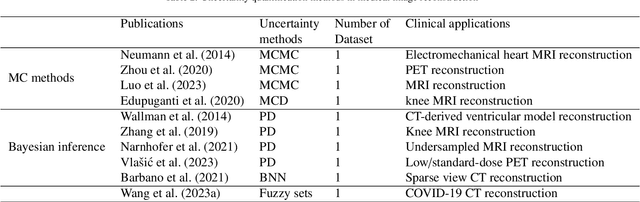
The comprehensive integration of machine learning healthcare models within clinical practice remains suboptimal, notwithstanding the proliferation of high-performing solutions reported in the literature. A predominant factor hindering widespread adoption pertains to an insufficiency of evidence affirming the reliability of the aforementioned models. Recently, uncertainty quantification methods have been proposed as a potential solution to quantify the reliability of machine learning models and thus increase the interpretability and acceptability of the result. In this review, we offer a comprehensive overview of prevailing methods proposed to quantify uncertainty inherent in machine learning models developed for various medical image tasks. Contrary to earlier reviews that exclusively focused on probabilistic methods, this review also explores non-probabilistic approaches, thereby furnishing a more holistic survey of research pertaining to uncertainty quantification for machine learning models. Analysis of medical images with the summary and discussion on medical applications and the corresponding uncertainty evaluation protocols are presented, which focus on the specific challenges of uncertainty in medical image analysis. We also highlight some potential future research work at the end. Generally, this review aims to allow researchers from both clinical and technical backgrounds to gain a quick and yet in-depth understanding of the research in uncertainty quantification for medical image analysis machine learning models.
Medical Image Segmentation with Belief Function Theory and Deep Learning
Sep 12, 2023
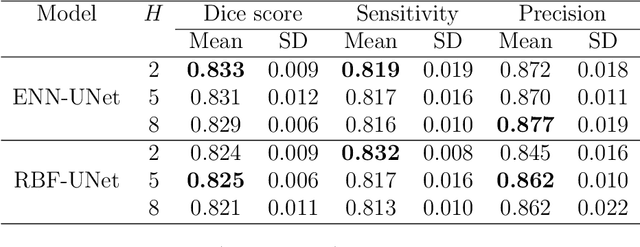
Deep learning has shown promising contributions in medical image segmentation with powerful learning and feature representation abilities. However, it has limitations for reasoning with and combining imperfect (imprecise, uncertain, and partial) information. In this thesis, we study medical image segmentation approaches with belief function theory and deep learning, specifically focusing on information modeling and fusion based on uncertain evidence. First, we review existing belief function theory-based medical image segmentation methods and discuss their advantages and challenges. Second, we present a semi-supervised medical image segmentation framework to decrease the uncertainty caused by the lack of annotations with evidential segmentation and evidence fusion. Third, we compare two evidential classifiers, evidential neural network and radial basis function network, and show the effectiveness of belief function theory in uncertainty quantification; we use the two evidential classifiers with deep neural networks to construct deep evidential models for lymphoma segmentation. Fourth, we present a multimodal medical image fusion framework taking into account the reliability of each MR image source when performing different segmentation tasks using mass functions and contextual discounting.
Deep evidential fusion with uncertainty quantification and contextual discounting for multimodal medical image segmentation
Sep 12, 2023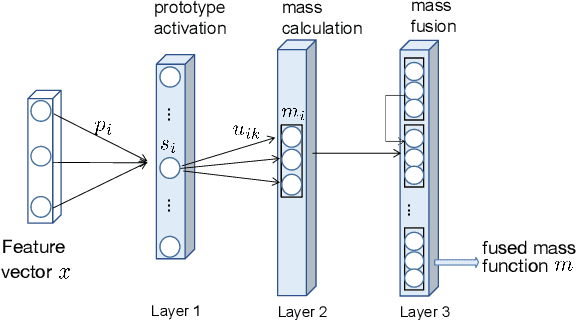
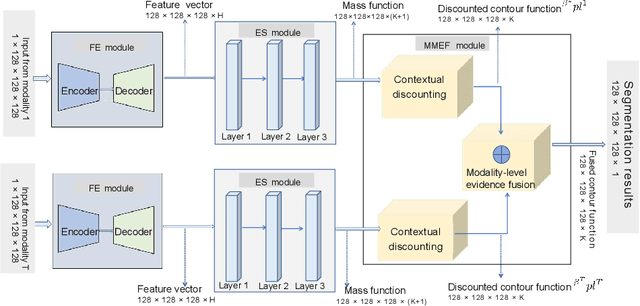
Single-modality medical images generally do not contain enough information to reach an accurate and reliable diagnosis. For this reason, physicians generally diagnose diseases based on multimodal medical images such as, e.g., PET/CT. The effective fusion of multimodal information is essential to reach a reliable decision and explain how the decision is made as well. In this paper, we propose a fusion framework for multimodal medical image segmentation based on deep learning and the Dempster-Shafer theory of evidence. In this framework, the reliability of each single modality image when segmenting different objects is taken into account by a contextual discounting operation. The discounted pieces of evidence from each modality are then combined by Dempster's rule to reach a final decision. Experimental results with a PET-CT dataset with lymphomas and a multi-MRI dataset with brain tumors show that our method outperforms the state-of-the-art methods in accuracy and reliability.
Evidence fusion with contextual discounting for multi-modality medical image segmentation
Jun 27, 2022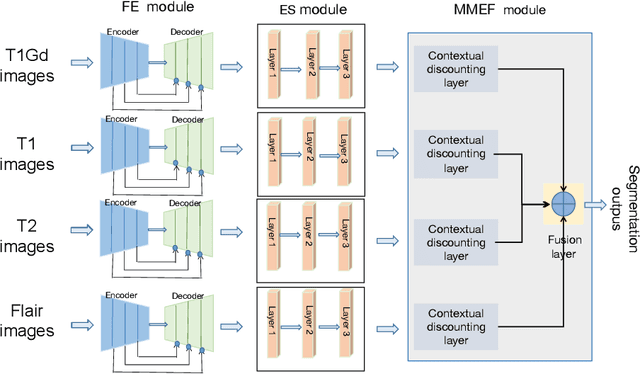
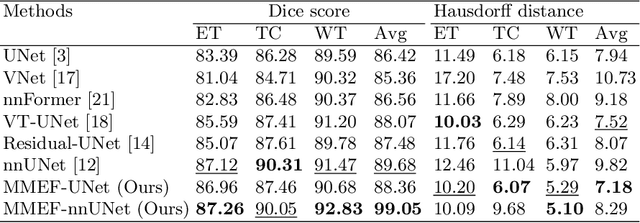
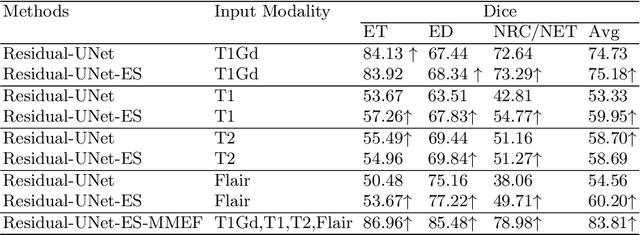
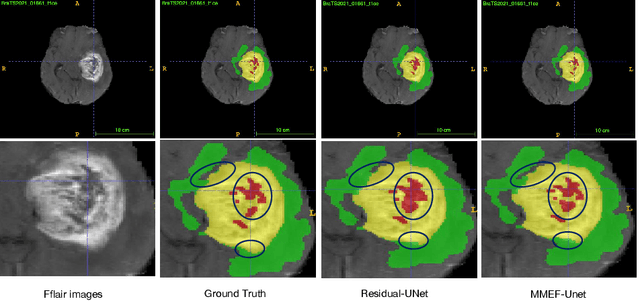
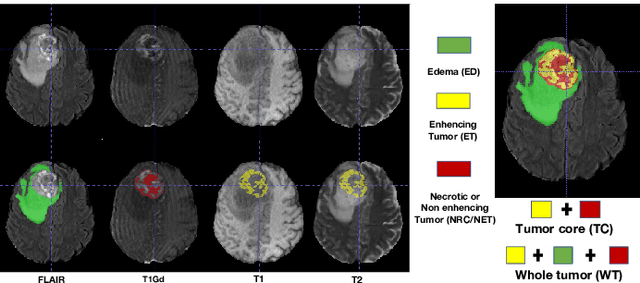
As information sources are usually imperfect, it is necessary to take into account their reliability in multi-source information fusion tasks. In this paper, we propose a new deep framework allowing us to merge multi-MR image segmentation results using the formalism of Dempster-Shafer theory while taking into account the reliability of different modalities relative to different classes. The framework is composed of an encoder-decoder feature extraction module, an evidential segmentation module that computes a belief function at each voxel for each modality, and a multi-modality evidence fusion module, which assigns a vector of discount rates to each modality evidence and combines the discounted evidence using Dempster's rule. The whole framework is trained by minimizing a new loss function based on a discounted Dice index to increase segmentation accuracy and reliability. The method was evaluated on the BraTs 2021 database of 1251 patients with brain tumors. Quantitative and qualitative results show that our method outperforms the state of the art, and implements an effective new idea for merging multi-information within deep neural networks.
Application of belief functions to medical image segmentation: A review
May 03, 2022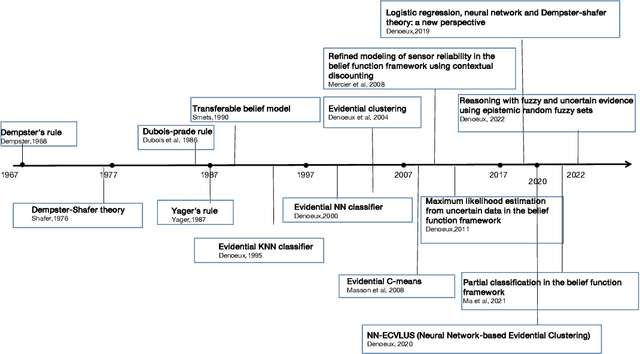

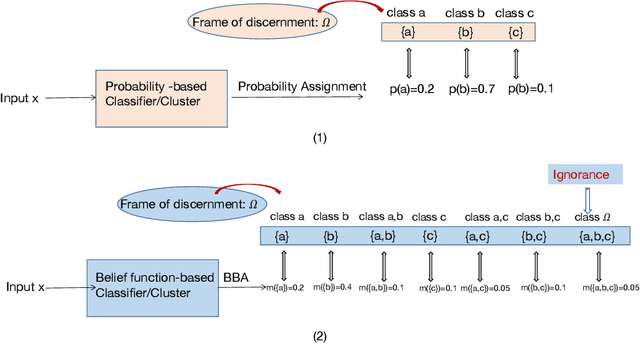
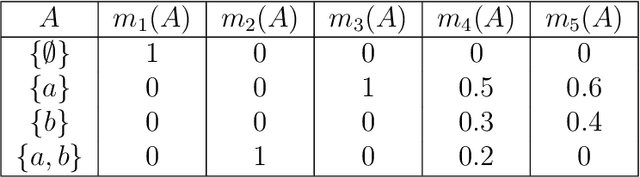
Belief function theory, a formal framework for uncertainty analysis and multiple evidence fusion, has made significant contributions in the medical domain, especially since the development of deep learning. Medical image segmentation with belief function theory has shown significant benefits in clinical diagnosis and medical image research. In this paper, we provide a review of medical image segmentation methods using belief function theory. We classify the methods according to the fusion step and explain how information with uncertainty or imprecision is modeled and fused with belief function theory. In addition, we discuss the challenges and limitations of present belief function-based medical image segmentation and propose orientations for future research. Future research could investigate both belief function theory and deep learning to achieve more promising and reliable segmentation results.
Broad Recommender System: An Efficient Nonlinear Collaborative Filtering Approach
Apr 20, 2022

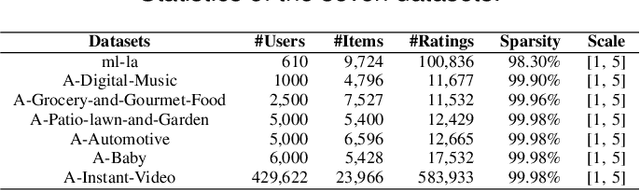
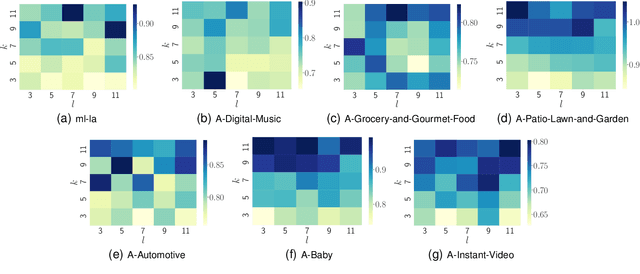
Recently, Deep Neural Networks (DNNs) have been widely introduced into Collaborative Filtering (CF) to produce more accurate recommendation results due to their capability of capturing the complex nonlinear relationships between items and users.However, the DNNs-based models usually suffer from high computational complexity, i.e., consuming very long training time and storing huge amount of trainable parameters. To address these problems, we propose a new broad recommender system called Broad Collaborative Filtering (BroadCF), which is an efficient nonlinear collaborative filtering approach. Instead of DNNs, Broad Learning System (BLS) is used as a mapping function to learn the complex nonlinear relationships between users and items, which can avoid the above issues while achieving very satisfactory recommendation performance. However, it is not feasible to directly feed the original rating data into BLS. To this end, we propose a user-item rating collaborative vector preprocessing procedure to generate low-dimensional user-item input data, which is able to harness quality judgments of the most similar users/items. Extensive experiments conducted on seven benchmark datasets have confirmed the effectiveness of the proposed BroadCF algorithm
G$^3$SR: Global Graph Guided Session-based Recommendation
Mar 12, 2022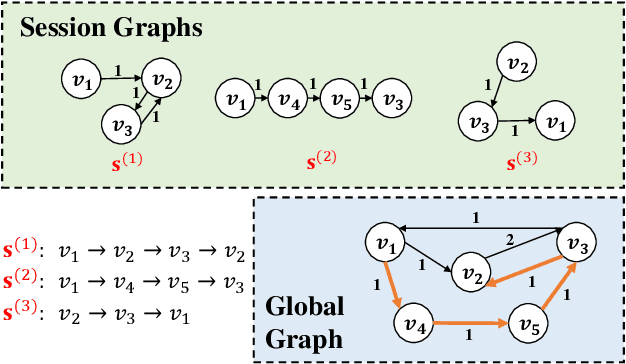
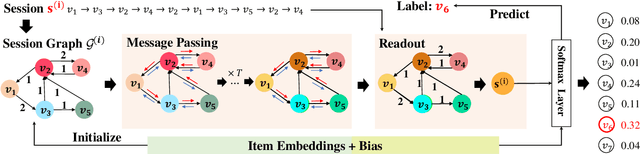
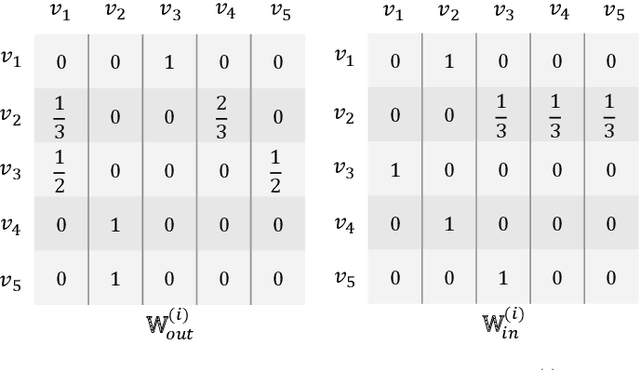
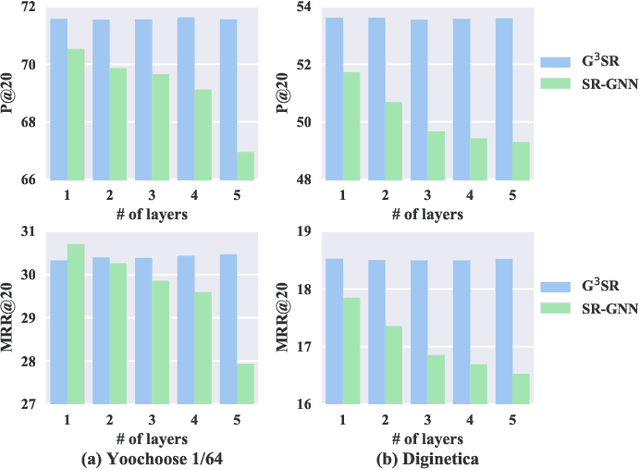
Session-based recommendation tries to make use of anonymous session data to deliver high-quality recommendation under the condition that user-profiles and the complete historical behavioral data of a target user are unavailable. Previous works consider each session individually and try to capture user interests within a session. Despite their encouraging results, these models can only perceive intra-session items and cannot draw upon the massive historical relational information. To solve this problem, we propose a novel method named G$^3$SR (Global Graph Guided Session-based Recommendation). G$^3$SR decomposes the session-based recommendation workflow into two steps. First, a global graph is built upon all session data, from which the global item representations are learned in an unsupervised manner. Then, these representations are refined on session graphs under the graph networks, and a readout function is used to generate session representations for each session. Extensive experiments on two real-world benchmark datasets show remarkable and consistent improvements of the G$^3$SR method over the state-of-the-art methods, especially for cold items.
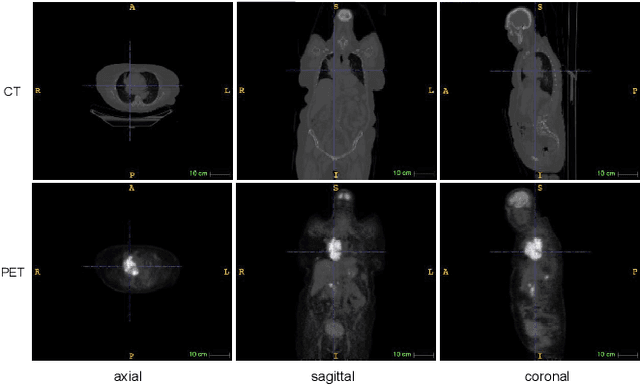
Lymphoma segmentation from 3D PET-CT images using a deep evidential network
Jan 31, 2022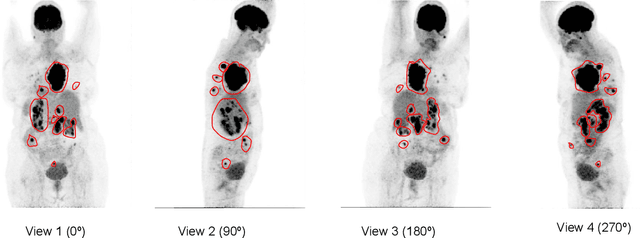
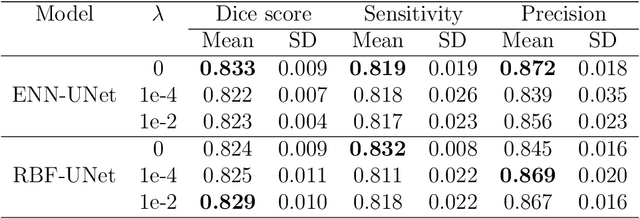
An automatic evidential segmentation method based on Dempster-Shafer theory and deep learning is proposed to segment lymphomas from three-dimensional Positron Emission Tomography (PET) and Computed Tomography (CT) images. The architecture is composed of a deep feature-extraction module and an evidential layer. The feature extraction module uses an encoder-decoder framework to extract semantic feature vectors from 3D inputs. The evidential layer then uses prototypes in the feature space to compute a belief function at each voxel quantifying the uncertainty about the presence or absence of a lymphoma at this location. Two evidential layers are compared, based on different ways of using distances to prototypes for computing mass functions. The whole model is trained end-to-end by minimizing the Dice loss function. The proposed combination of deep feature extraction and evidential segmentation is shown to outperform the baseline UNet model as well as three other state-of-the-art models on a dataset of 173 patients.
Deep PET/CT fusion with Dempster-Shafer theory for lymphoma segmentation
Aug 11, 2021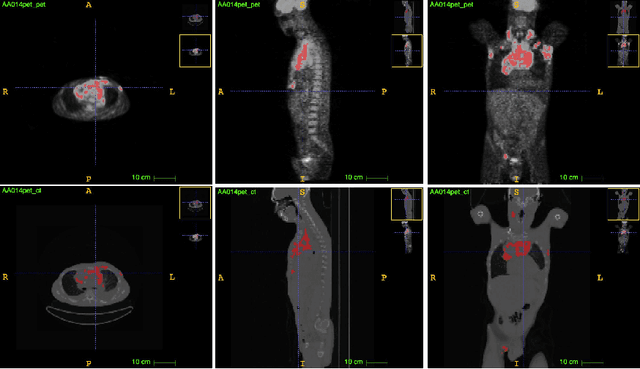
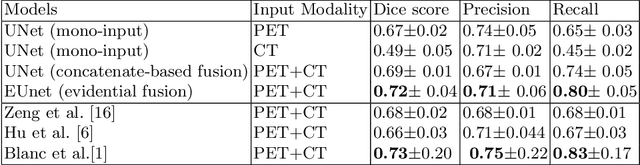
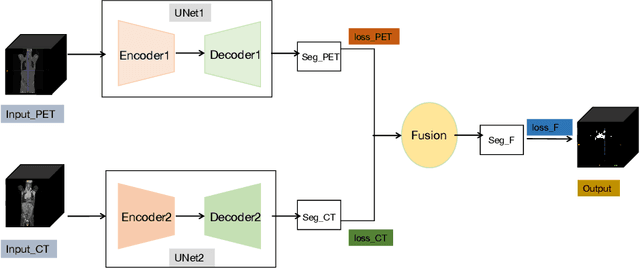

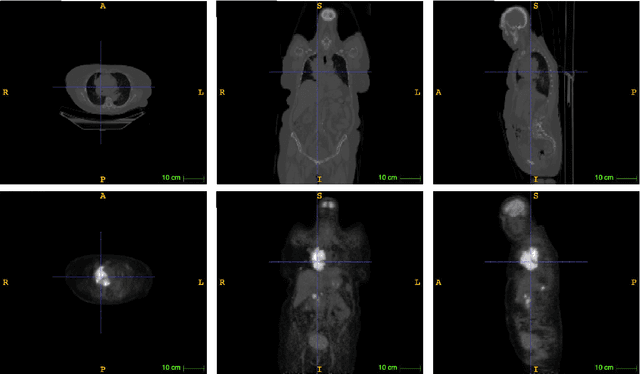
Lymphoma detection and segmentation from whole-body Positron Emission Tomography/Computed Tomography (PET/CT) volumes are crucial for surgical indication and radiotherapy. Designing automatic segmentation methods capable of effectively exploiting the information from PET and CT as well as resolving their uncertainty remain a challenge. In this paper, we propose an lymphoma segmentation model using an UNet with an evidential PET/CT fusion layer. Single-modality volumes are trained separately to get initial segmentation maps and an evidential fusion layer is proposed to fuse the two pieces of evidence using Dempster-Shafer theory (DST). Moreover, a multi-task loss function is proposed: in addition to the use of the Dice loss for PET and CT segmentation, a loss function based on the concordance between the two segmentation is added to constrain the final segmentation. We evaluate our proposal on a database of polycentric PET/CT volumes of patients treated for lymphoma, delineated by the experts. Our method get accurate segmentation results with Dice score of 0.726, without any user interaction. Quantitative results show that our method is superior to the state-of-the-art methods.
Evidential segmentation of 3D PET/CT images
Apr 27, 2021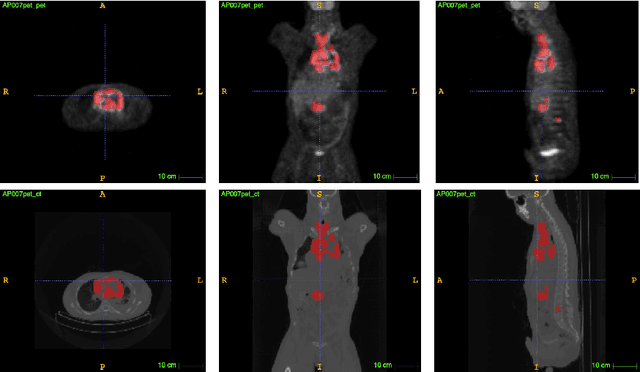
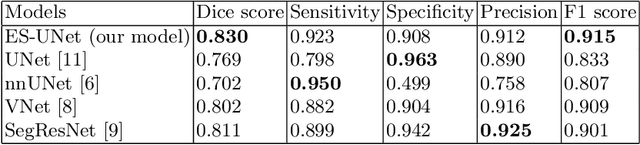
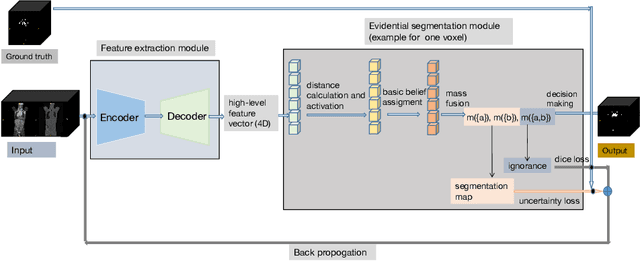
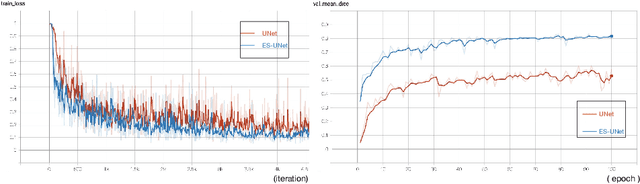
PET and CT are two modalities widely used in medical image analysis. Accurately detecting and segmenting lymphomas from these two imaging modalities are critical tasks for cancer staging and radiotherapy planning. However, this task is still challenging due to the complexity of PET/CT images, and the computation cost to process 3D data. In this paper, a segmentation method based on belief functions is proposed to segment lymphomas in 3D PET/CT images. The architecture is composed of a feature extraction module and an evidential segmentation (ES) module. The ES module outputs not only segmentation results (binary maps indicating the presence or absence of lymphoma in each voxel) but also uncertainty maps quantifying the classification uncertainty. The whole model is optimized by minimizing Dice and uncertainty loss functions to increase segmentation accuracy. The method was evaluated on a database of 173 patients with diffuse large b-cell lymphoma. Quantitative and qualitative results show that our method outperforms the state-of-the-art methods.