 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingjie Kong
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024




This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
Real-time SLAM Pipeline in Dynamics Environment
Mar 04, 2023



Inspired by the recent success of application of dense data approach by using ORB-SLAM and RGB-D SLAM, we propose a better pipeline of real-time SLAM in dynamics environment. Different from previous SLAM which can only handle static scenes, we are presenting a solution which use RGB-D SLAM as well as YOLO real-time object detection to segment and remove dynamic scene and then construct static scene 3D. We gathered a dataset which allows us to jointly consider semantics, geometry, and physics and thus enables us to reconstruct the static scene while filtering out all dynamic objects.
Double A3C: Deep Reinforcement Learning on OpenAI Gym Games
Mar 04, 2023
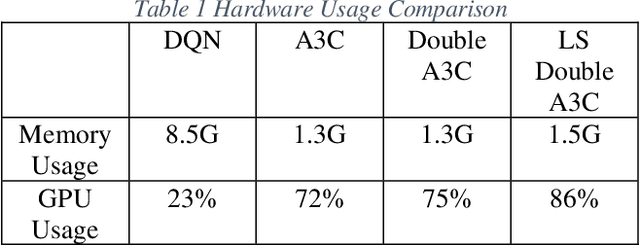


Reinforcement Learning (RL) is an area of machine learning figuring out how agents take actions in an unknown environment to maximize its rewards. Unlike classical Markov Decision Process (MDP) in which agent has full knowledge of its state, rewards, and transitional probability, reinforcement learning utilizes exploration and exploitation for the model uncertainty. Under the condition that the model usually has a large state space, a neural network (NN) can be used to correlate its input state to its output actions to maximize the agent's rewards. However, building and training an efficient neural network is challenging. Inspired by Double Q-learning and Asynchronous Advantage Actor-Critic (A3C) algorithm, we will propose and implement an improved version of Double A3C algorithm which utilizing the strength of both algorithms to play OpenAI Gym Atari 2600 games to beat its benchmarks for our project.
Generative Models for 3D Point Clouds
Feb 26, 2023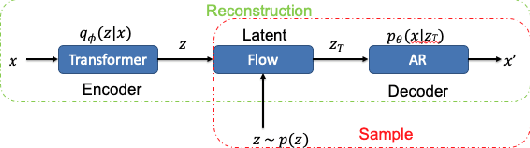


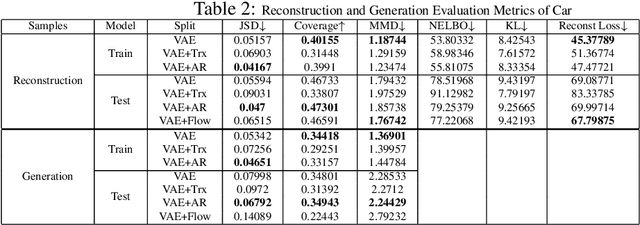
Point clouds are rich geometric data structures, where their three dimensional structure offers an excellent domain for understanding the representation learning and generative modeling in 3D space. In this work, we aim to improve the performance of point cloud latent-space generative models by experimenting with transformer encoders, latent-space flow models, and autoregressive decoders. We analyze and compare both generation and reconstruction performance of these models on various object types.
From Audio to Symbolic Encoding
Feb 26, 2023



Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.
Path Integral Based Convolution and Pooling for Heterogeneous Graph Neural Networks
Feb 26, 2023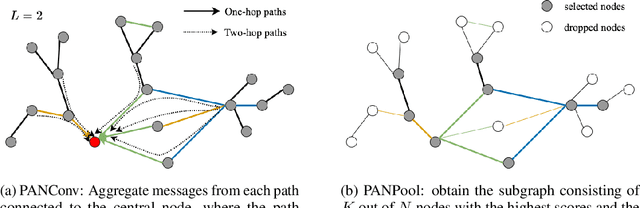
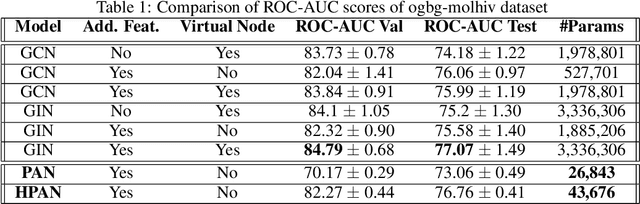
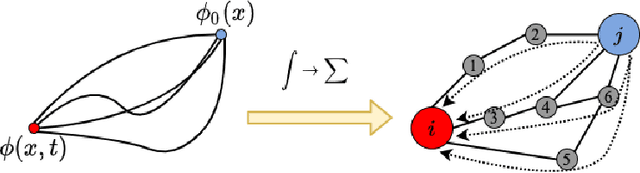
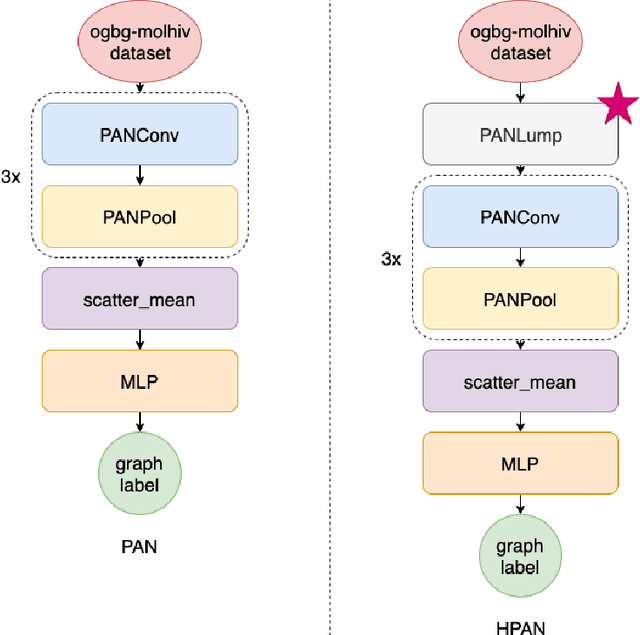
Graph neural networks (GNN) extends deep learning to graph-structure dataset. Similar to Convolutional Neural Networks (CNN) using on image prediction, convolutional and pooling layers are the foundation to success for GNN on graph prediction tasks. In the initial PAN paper, it uses a path integral based graph neural networks for graph prediction. Specifically, it uses a convolution operation that involves every path linking the message sender and receiver with learnable weights depending on the path length, which corresponds to the maximal entropy random walk. It further generalizes such convolution operation to a new transition matrix called maximal entropy transition (MET). Because the diagonal entries of the MET matrix is directly related to the subgraph centrality, it provide a trial mechanism for pooling based on centrality score. While the initial PAN paper only considers node features. We further extends its capability to handle complex heterogeneous graph including both node and edge features.
DeepSim: A Reinforcement Learning Environment Build Toolkit for ROS and Gazebo
May 17, 2022



We propose DeepSim, a reinforcement learning environment build toolkit for ROS and Gazebo. It allows machine learning or reinforcement learning researchers to access the robotics domain and create complex and challenging custom tasks in ROS and Gazebo simulation environments. This toolkit provides building blocks of advanced features such as collision detection, behaviour control, domain randomization, spawner, and many more. DeepSim is designed to reduce the boundary between robotics and machine learning communities by providing Python interface. In this paper, we discuss the components and design decisions of DeepSim Toolkit.
Unified Distributed Environment
May 14, 2022



We propose Unified Distributed Environment (UDE), an environment virtualization toolkit for reinforcement learning research. UDE is designed to integrate environments built on any simulation platform such as Gazebo, Unity, Unreal, and OpenAI Gym. Through environment virtualization, UDE enables offloading the environment for execution on a remote machine while still maintaining a unified interface. The UDE interface is designed to support multi-agent by default. With environment virtualization and its interface design, the agent policies can be trained in multiple machines for a multi-agent environment. Furthermore, UDE supports integration with existing major RL toolkits for researchers to leverage the benefits. This paper discusses the components of UDE and its design decisions.