 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingling Zhang
Learning from Semi-Factuals: A Debiased and Semantic-Aware Framework for Generalized Relation Discovery
Jan 12, 2024
We introduce a novel task, called Generalized Relation Discovery (GRD), for open-world relation extraction. GRD aims to identify unlabeled instances in existing pre-defined relations or discover novel relations by assigning instances to clusters as well as providing specific meanings for these clusters. The key challenges of GRD are how to mitigate the serious model biases caused by labeled pre-defined relations to learn effective relational representations and how to determine the specific semantics of novel relations during classifying or clustering unlabeled instances. We then propose a novel framework, SFGRD, for this task to solve the above issues by learning from semi-factuals in two stages. The first stage is semi-factual generation implemented by a tri-view debiased relation representation module, in which we take each original sentence as the main view and design two debiased views to generate semi-factual examples for this sentence. The second stage is semi-factual thinking executed by a dual-space tri-view collaborative relation learning module, where we design a cluster-semantic space and a class-index space to learn relational semantics and relation label indices, respectively. In addition, we devise alignment and selection strategies to integrate two spaces and establish a self-supervised learning loop for unlabeled data by doing semi-factual thinking across three views. Extensive experimental results show that SFGRD surpasses state-of-the-art models in terms of accuracy by 2.36\% $\sim$5.78\% and cosine similarity by 32.19\%$\sim$ 84.45\% for relation label index and relation semantic quality, respectively. To the best of our knowledge, we are the first to exploit the efficacy of semi-factuals in relation extraction.
Mind Reasoning Manners: Enhancing Type Perception for Generalized Zero-shot Logical Reasoning over Text
Jan 08, 2023



Logical reasoning task involves diverse types of complex reasoning over text, based on the form of multiple-choice question answering. Given the context, question and a set of options as the input, previous methods achieve superior performances on the full-data setting. However, the current benchmark dataset has the ideal assumption that the reasoning type distribution on the train split is close to the test split, which is inconsistent with many real application scenarios. To address it, there remain two problems to be studied: (1) How is the zero-shot capability of the models (train on seen types and test on unseen types)? (2) How to enhance the perception of reasoning types for the models? For problem 1, we propose a new benchmark for generalized zero-shot logical reasoning, named ZsLR. It includes six splits based on the three type sampling strategies. For problem 2, a type-aware model TaCo is proposed. It utilizes both the heuristic input reconstruction and the contrastive learning to improve the type perception in the global representation. Extensive experiments on both the zero-shot and full-data settings prove the superiority of TaCo over the state-of-the-art methods. Also, we experiment and verify the generalization capability of TaCo on other logical reasoning dataset.
GPTR: Gestalt-Perception Transformer for Diagram Object Detection
Dec 29, 2022
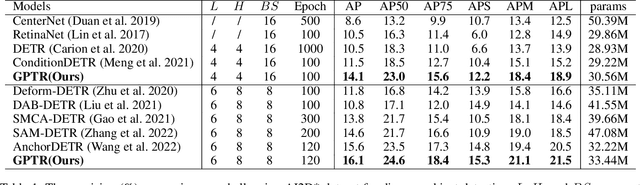
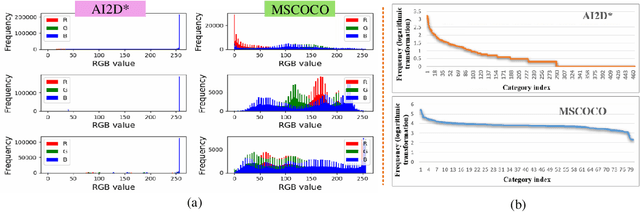

Diagram object detection is the key basis of practical applications such as textbook question answering. Because the diagram mainly consists of simple lines and color blocks, its visual features are sparser than those of natural images. In addition, diagrams usually express diverse knowledge, in which there are many low-frequency object categories in diagrams. These lead to the fact that traditional data-driven detection model is not suitable for diagrams. In this work, we propose a gestalt-perception transformer model for diagram object detection, which is based on an encoder-decoder architecture. Gestalt perception contains a series of laws to explain human perception, that the human visual system tends to perceive patches in an image that are similar, close or connected without abrupt directional changes as a perceptual whole object. Inspired by these thoughts, we build a gestalt-perception graph in transformer encoder, which is composed of diagram patches as nodes and the relationships between patches as edges. This graph aims to group these patches into objects via laws of similarity, proximity, and smoothness implied in these edges, so that the meaningful objects can be effectively detected. The experimental results demonstrate that the proposed GPTR achieves the best results in the diagram object detection task. Our model also obtains comparable results over the competitors in natural image object detection.
Computation Offloading and Resource Allocation in F-RANs: A Federated Deep Reinforcement Learning Approach
Jun 13, 2022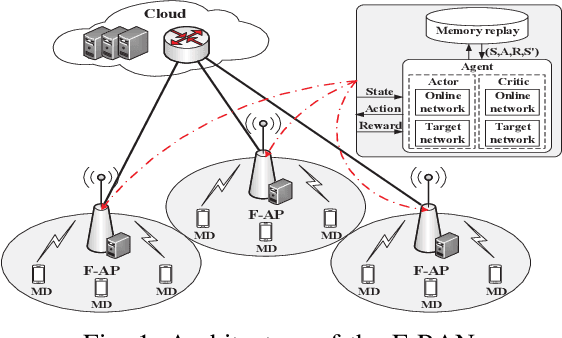
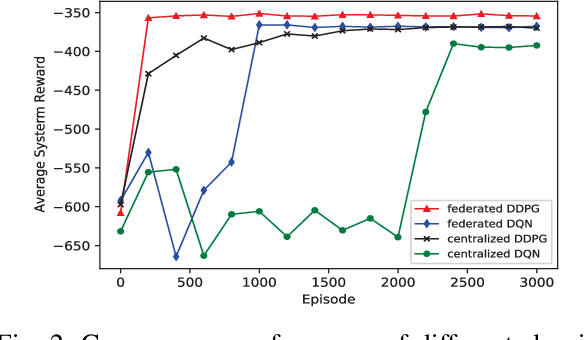
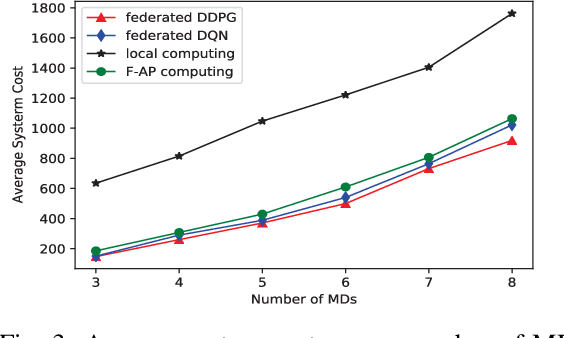
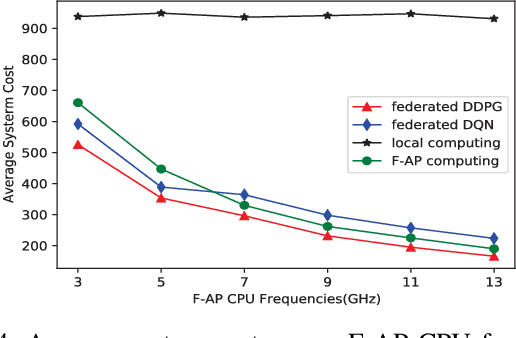
The fog radio access network (F-RAN) is a promising technology in which the user mobile devices (MDs) can offload computation tasks to the nearby fog access points (F-APs). Due to the limited resource of F-APs, it is important to design an efficient task offloading scheme. In this paper, by considering time-varying network environment, a dynamic computation offloading and resource allocation problem in F-RANs is formulated to minimize the task execution delay and energy consumption of MDs. To solve the problem, a federated deep reinforcement learning (DRL) based algorithm is proposed, where the deep deterministic policy gradient (DDPG) algorithm performs computation offloading and resource allocation in each F-AP. Federated learning is exploited to train the DDPG agents in order to decrease the computing complexity of training process and protect the user privacy. Simulation results show that the proposed federated DDPG algorithm can achieve lower task execution delay and energy consumption of MDs more quickly compared with the other existing strategies.
Logiformer: A Two-Branch Graph Transformer Network for Interpretable Logical Reasoning
May 02, 2022



Machine reading comprehension has aroused wide concerns, since it explores the potential of model for text understanding. To further equip the machine with the reasoning capability, the challenging task of logical reasoning is proposed. Previous works on logical reasoning have proposed some strategies to extract the logical units from different aspects. However, there still remains a challenge to model the long distance dependency among the logical units. Also, it is demanding to uncover the logical structures of the text and further fuse the discrete logic to the continuous text embedding. To tackle the above issues, we propose an end-to-end model Logiformer which utilizes a two-branch graph transformer network for logical reasoning of text. Firstly, we introduce different extraction strategies to split the text into two sets of logical units, and construct the logical graph and the syntax graph respectively. The logical graph models the causal relations for the logical branch while the syntax graph captures the co-occurrence relations for the syntax branch. Secondly, to model the long distance dependency, the node sequence from each graph is fed into the fully connected graph transformer structures. The two adjacent matrices are viewed as the attention biases for the graph transformer layers, which map the discrete logical structures to the continuous text embedding space. Thirdly, a dynamic gate mechanism and a question-aware self-attention module are introduced before the answer prediction to update the features. The reasoning process provides the interpretability by employing the logical units, which are consistent with human cognition. The experimental results show the superiority of our model, which outperforms the state-of-the-art single model on two logical reasoning benchmarks.
Consistent Style Transfer
Jan 06, 2022
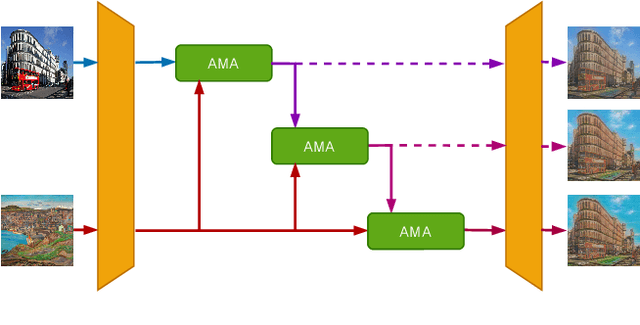

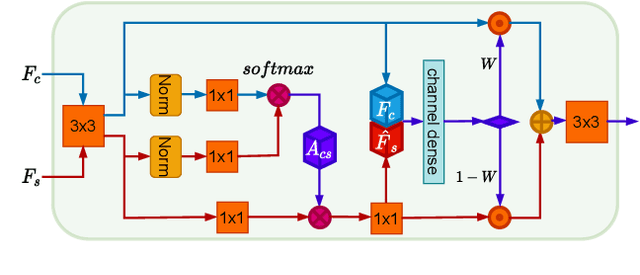
Recently, attentional arbitrary style transfer methods have been proposed to achieve fine-grained results, which manipulates the point-wise similarity between content and style features for stylization. However, the attention mechanism based on feature points ignores the feature multi-manifold distribution, where each feature manifold corresponds to a semantic region in the image. Consequently, a uniform content semantic region is rendered by highly different patterns from various style semantic regions, producing inconsistent stylization results with visual artifacts. We proposed the progressive attentional manifold alignment (PAMA) to alleviate this problem, which repeatedly applies attention operations and space-aware interpolations. The attention operation rearranges style features dynamically according to the spatial distribution of content features. This makes the content and style manifolds correspond on the feature map. Then the space-aware interpolation adaptively interpolates between the corresponding content and style manifolds to increase their similarity. By gradually aligning the content manifolds to style manifolds, the proposed PAMA achieves state-of-the-art performance while avoiding the inconsistency of semantic regions. Codes are available at https://github.com/computer-vision2022/PAMA.
MoCA: Incorporating Multi-stage Domain Pretraining and Cross-guided Multimodal Attention for Textbook Question Answering
Dec 06, 2021



Textbook Question Answering (TQA) is a complex multimodal task to infer answers given large context descriptions and abundant diagrams. Compared with Visual Question Answering (VQA), TQA contains a large number of uncommon terminologies and various diagram inputs. It brings new challenges to the representation capability of language model for domain-specific spans. And it also pushes the multimodal fusion to a more complex level. To tackle the above issues, we propose a novel model named MoCA, which incorporates multi-stage domain pretraining and multimodal cross attention for the TQA task. Firstly, we introduce a multi-stage domain pretraining module to conduct unsupervised post-pretraining with the span mask strategy and supervised pre-finetune. Especially for domain post-pretraining, we propose a heuristic generation algorithm to employ the terminology corpus. Secondly, to fully consider the rich inputs of context and diagrams, we propose cross-guided multimodal attention to update the features of text, question diagram and instructional diagram based on a progressive strategy. Further, a dual gating mechanism is adopted to improve the model ensemble. The experimental results show the superiority of our model, which outperforms the state-of-the-art methods by 2.21% and 2.43% for validation and test split respectively.
Learning First-Order Rules with Relational Path Contrast for Inductive Relation Reasoning
Oct 17, 2021



Relation reasoning in knowledge graphs (KGs) aims at predicting missing relations in incomplete triples, whereas the dominant paradigm is learning the embeddings of relations and entities, which is limited to a transductive setting and has restriction on processing unseen entities in an inductive situation. Previous inductive methods are scalable and consume less resource. They utilize the structure of entities and triples in subgraphs to own inductive ability. However, in order to obtain better reasoning results, the model should acquire entity-independent relational semantics in latent rules and solve the deficient supervision caused by scarcity of rules in subgraphs. To address these issues, we propose a novel graph convolutional network (GCN)-based approach for interpretable inductive reasoning with relational path contrast, named RPC-IR. RPC-IR firstly extracts relational paths between two entities and learns representations of them, and then innovatively introduces a contrastive strategy by constructing positive and negative relational paths. A joint training strategy considering both supervised and contrastive information is also proposed. Comprehensive experiments on three inductive datasets show that RPC-IR achieves outstanding performance comparing with the latest inductive reasoning methods and could explicitly represent logical rules for interpretability.
SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
Mar 31, 2020



Semantic parsing transforms a natural language question into a formal query over a knowledge base. Many existing methods rely on syntactic parsing like dependencies. However, the accuracy of producing such expressive formalisms is not satisfying on long complex questions. In this paper, we propose a novel skeleton grammar to represent the high-level structure of a complex question. This dedicated coarse-grained formalism with a BERT-based parsing algorithm helps to improve the accuracy of the downstream fine-grained semantic parsing. Besides, to align the structure of a question with the structure of a knowledge base, our multi-strategy method combines sentence-level and word-level semantics. Our approach shows promising performance on several datasets.
ZSTAD: Zero-Shot Temporal Activity Detection
Mar 12, 2020



An integral part of video analysis and surveillance is temporal activity detection, which means to simultaneously recognize and localize activities in long untrimmed videos. Currently, the most effective methods of temporal activity detection are based on deep learning, and they typically perform very well with large scale annotated videos for training. However, these methods are limited in real applications due to the unavailable videos about certain activity classes and the time-consuming data annotation. To solve this challenging problem, we propose a novel task setting called zero-shot temporal activity detection (ZSTAD), where activities that have never been seen in training can still be detected. We design an end-to-end deep network based on R-C3D as the architecture for this solution. The proposed network is optimized with an innovative loss function that considers the embeddings of activity labels and their super-classes while learning the common semantics of seen and unseen activities. Experiments on both the THUMOS14 and the Charades datasets show promising performance in terms of detecting unseen activities.