 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinjian Meng
Efficient Last-iterate Convergence Algorithms in Solving Games
Aug 22, 2023
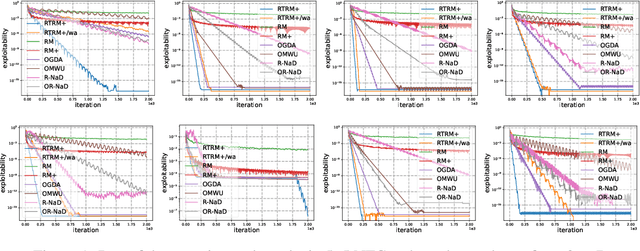
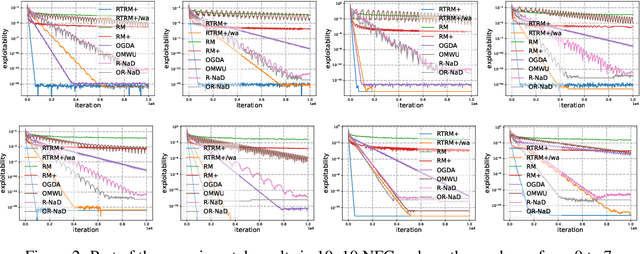
No-regret algorithms are popular for learning Nash equilibrium (NE) in two-player zero-sum normal-form games (NFGs) and extensive-form games (EFGs). Many recent works consider the last-iterate convergence no-regret algorithms. Among them, the two most famous algorithms are Optimistic Gradient Descent Ascent (OGDA) and Optimistic Multiplicative Weight Update (OMWU). However, OGDA has high per-iteration complexity. OMWU exhibits a lower per-iteration complexity but poorer empirical performance, and its convergence holds only when NE is unique. Recent works propose a Reward Transformation (RT) framework for MWU, which removes the uniqueness condition and achieves competitive performance with OMWU. Unfortunately, RT-based algorithms perform worse than OGDA under the same number of iterations, and their convergence guarantee is based on the continuous-time feedback assumption, which does not hold in most scenarios. To address these issues, we provide a closer analysis of the RT framework, which holds for both continuous and discrete-time feedback. We demonstrate that the essence of the RT framework is to transform the problem of learning NE in the original game into a series of strongly convex-concave optimization problems (SCCPs). We show that the bottleneck of RT-based algorithms is the speed of solving SCCPs. To improve the their empirical performance, we design a novel transformation method to enable the SCCPs can be solved by Regret Matching+ (RM+), a no-regret algorithm with better empirical performance, resulting in Reward Transformation RM+ (RTRM+). RTRM+ enjoys last-iterate convergence under the discrete-time feedback setting. Using the counterfactual regret decomposition framework, we propose Reward Transformation CFR+ (RTCFR+) to extend RTRM+ to EFGs. Experimental results show that our algorithms significantly outperform existing last-iterate convergence algorithms and RM+ (CFR+).
Generalized Bandit Regret Minimizer Framework in Imperfect Information Extensive-Form Game
Mar 28, 2022



Regret minimization methods are a powerful tool for learning approximate Nash equilibrium (NE) in two-player zero-sum imperfect information extensive-form games (IIEGs). We consider the problem in the interactive bandit-feedback setting where we don't know the dynamics of the IIEG. In general, only the interactive trajectory and the reached terminal node value $v(z^t)$ are revealed. To learn NE, the regret minimizer is required to estimate the full-feedback loss gradient $\ell^t$ by $v(z^t)$ and minimize the regret. In this paper, we propose a generalized framework for this learning setting. It presents a theoretical framework for the design and the modular analysis of the bandit regret minimization methods. We demonstrate that the most recent bandit regret minimization methods can be analyzed as a particular case of our framework. Following this framework, we describe a novel method SIX-OMD to learn approximate NE. It is model-free and extremely improves the best existing convergence rate from the order of $O(\sqrt{X B/T}+\sqrt{Y C/T})$ to $O(\sqrt{ M_{\mathcal{X}}/T} +\sqrt{ M_{\mathcal{Y}}/T})$. Moreover, SIX-OMD is computationally efficient as it needs to perform the current strategy and average strategy updates only along the sampled trajectory.