 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLior Rokach
BagStacking: An Integrated Ensemble Learning Approach for Freezing of Gait Detection in Parkinson's Disease
Feb 24, 2024
This paper introduces BagStacking, a novel ensemble learning method designed to enhance the detection of Freezing of Gait (FOG) in Parkinson's Disease (PD) by using a lower-back sensor to track acceleration. Building on the principles of bagging and stacking, BagStacking aims to achieve the variance reduction benefit of bagging's bootstrap sampling while also learning sophisticated blending through stacking. The method involves training a set of base models on bootstrap samples from the training data, followed by a meta-learner trained on the base model outputs and true labels to find an optimal aggregation scheme. The experimental evaluation demonstrates significant improvements over other state-of-the-art machine learning methods on the validation set. Specifically, BagStacking achieved a MAP score of 0.306, outperforming LightGBM (0.234) and classic Stacking (0.286). Additionally, the run-time of BagStacking was measured at 3828 seconds, illustrating an efficient approach compared to Regular Stacking's 8350 seconds. BagStacking presents a promising direction for handling the inherent variability in FOG detection data, offering a robust and scalable solution to improve patient care in PD.
AMFPMC -- An improved method of detecting multiple types of drug-drug interactions using only known drug-drug interactions
Feb 07, 2023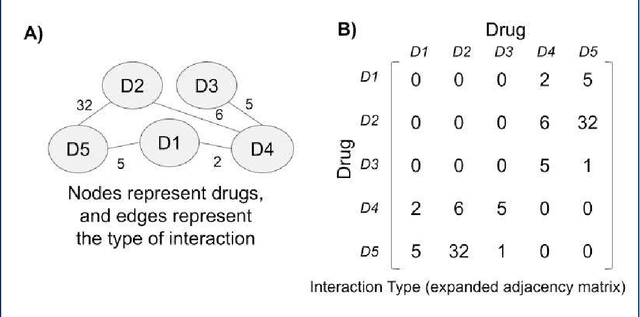

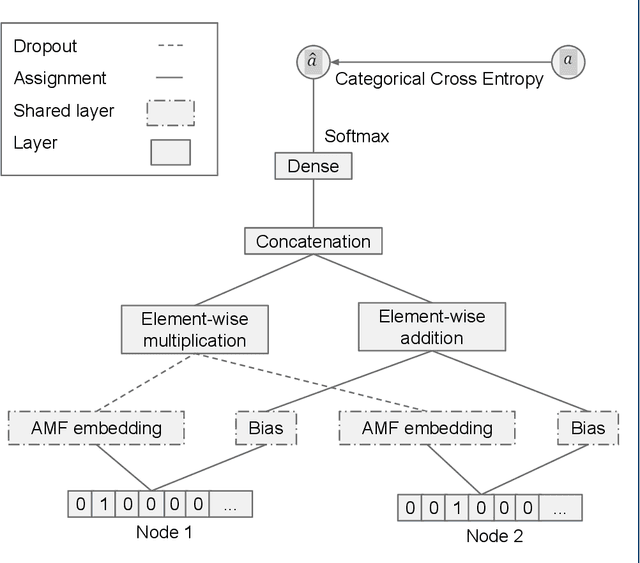
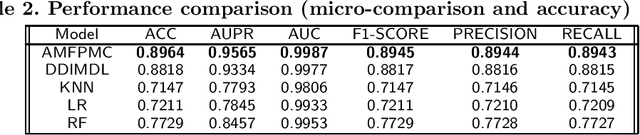
Adverse drug interactions are largely preventable causes of medical accidents, which frequently result in physician and emergency room encounters. The detection of drug interactions in a lab, prior to a drug's use in medical practice, is essential, however it is costly and time-consuming. Machine learning techniques can provide an efficient and accurate means of predicting possible drug-drug interactions and combat the growing problem of adverse drug interactions. Most existing models for predicting interactions rely on the chemical properties of drugs. While such models can be accurate, the required properties are not always available.
Silent Killer: Optimizing Backdoor Trigger Yields a Stealthy and Powerful Data Poisoning Attack
Jan 05, 2023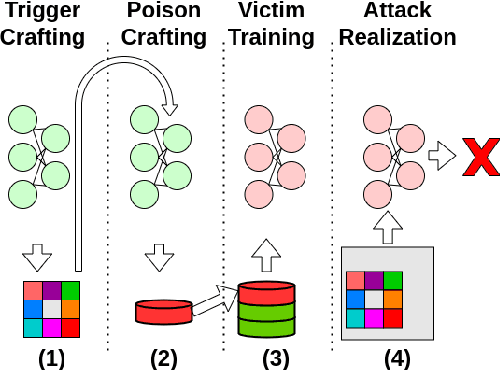
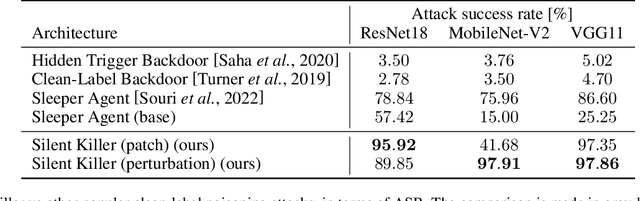


We propose a stealthy and powerful backdoor attack on neural networks based on data poisoning (DP). In contrast to previous attacks, both the poison and the trigger in our method are stealthy. We are able to change the model's classification of samples from a source class to a target class chosen by the attacker. We do so by using a small number of poisoned training samples with nearly imperceptible perturbations, without changing their labels. At inference time, we use a stealthy perturbation added to the attacked samples as a trigger. This perturbation is crafted as a universal adversarial perturbation (UAP), and the poison is crafted using gradient alignment coupled to this trigger. Our method is highly efficient in crafting time compared to previous methods and requires only a trained surrogate model without additional retraining. Our attack achieves state-of-the-art results in terms of attack success rate while maintaining high accuracy on clean samples.
Cross Version Defect Prediction with Class Dependency Embeddings
Dec 29, 2022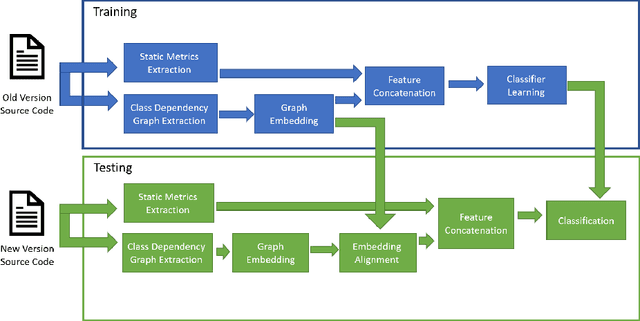
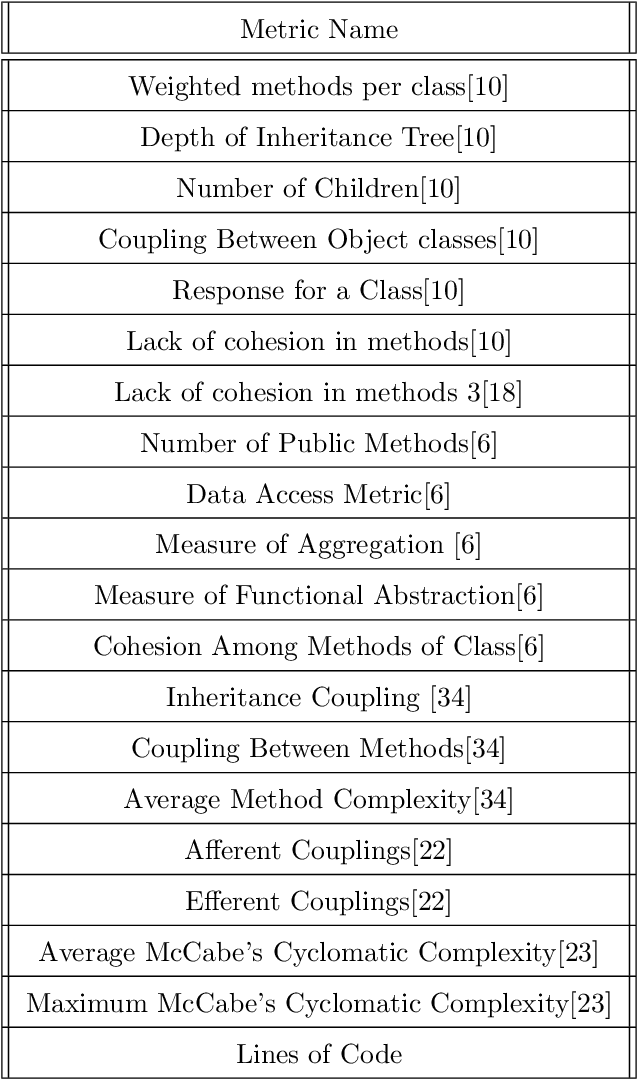
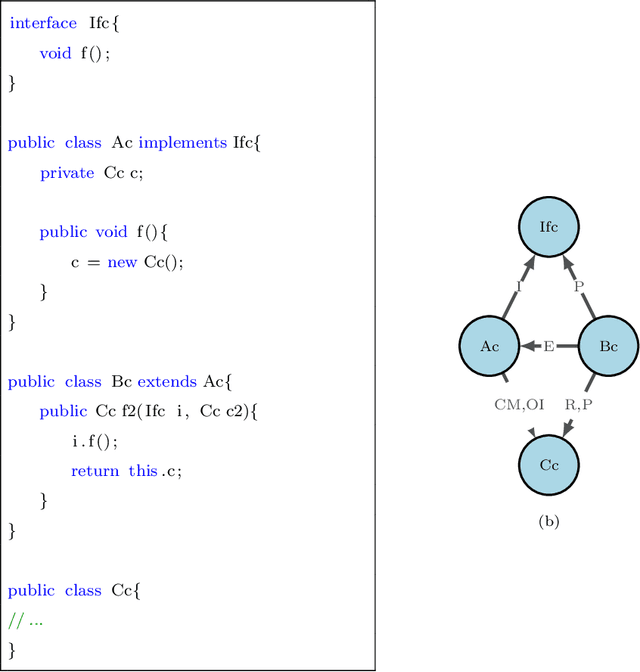
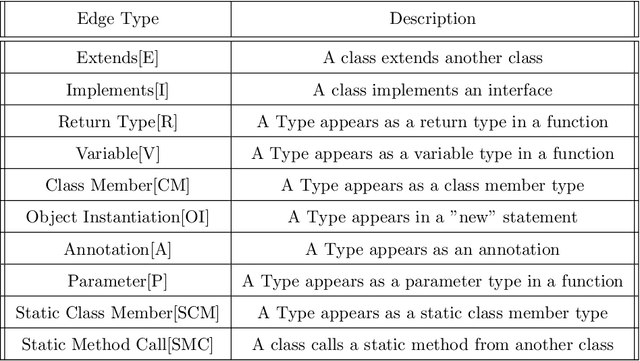
Software Defect Prediction aims at predicting which software modules are the most probable to contain defects. The idea behind this approach is to save time during the development process by helping find bugs early. Defect Prediction models are based on historical data. Specifically, one can use data collected from past software distributions, or Versions, of the same target application under analysis. Defect Prediction based on past versions is called Cross Version Defect Prediction (CVDP). Traditionally, Static Code Metrics are used to predict defects. In this work, we use the Class Dependency Network (CDN) as another predictor for defects, combined with static code metrics. CDN data contains structural information about the target application being analyzed. Usually, CDN data is analyzed using different handcrafted network measures, like Social Network metrics. Our approach uses network embedding techniques to leverage CDN information without having to build the metrics manually. In order to use the embeddings between versions, we incorporate different embedding alignment techniques. To evaluate our approach, we performed experiments on 24 software release pairs and compared it against several benchmark methods. In these experiments, we analyzed the performance of two different graph embedding techniques, three anchor selection approaches, and two alignment techniques. We also built a meta-model based on two different embeddings and achieved a statistically significant improvement in AUC of 4.7% (p < 0.002) over the baseline method.
Transfer learning for time series classification using synthetic data generation
Jul 16, 2022In this paper, we propose an innovative Transfer learning for Time series classification method. Instead of using an existing dataset from the UCR archive as the source dataset, we generated a 15,000,000 synthetic univariate time series dataset that was created using our unique synthetic time series generator algorithm which can generate data with diverse patterns and angles and different sequence lengths. Furthermore, instead of using classification tasks provided by the UCR archive as the source task as previous studies did,we used our own 55 regression tasks as the source tasks, which produced better results than selecting classification tasks from the UCR archive
A Universal Adversarial Policy for Text Classifiers
Jun 19, 2022

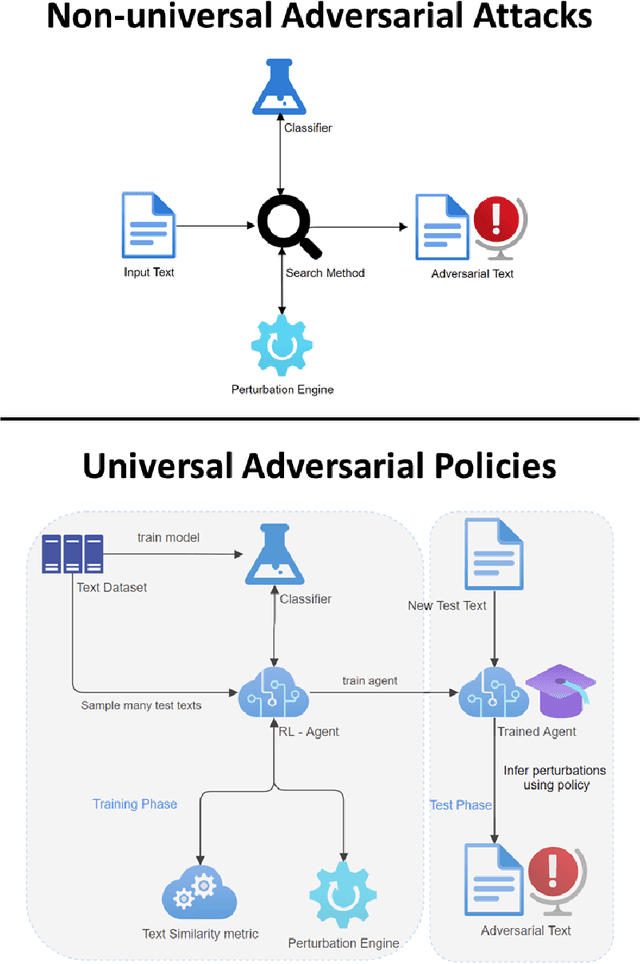
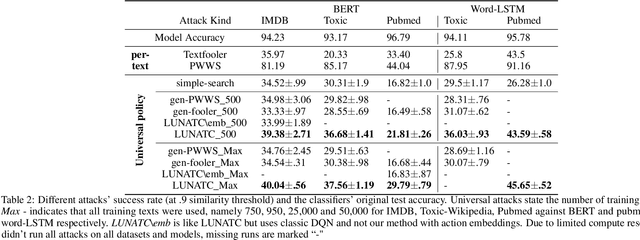
Discovering the existence of universal adversarial perturbations had large theoretical and practical impacts on the field of adversarial learning. In the text domain, most universal studies focused on adversarial prefixes which are added to all texts. However, unlike the vision domain, adding the same perturbation to different inputs results in noticeably unnatural inputs. Therefore, we introduce a new universal adversarial setup - a universal adversarial policy, which has many advantages of other universal attacks but also results in valid texts - thus making it relevant in practice. We achieve this by learning a single search policy over a predefined set of semantics preserving text alterations, on many texts. This formulation is universal in that the policy is successful in finding adversarial examples on new texts efficiently. Our approach uses text perturbations which were extensively shown to produce natural attacks in the non-universal setup (specific synonym replacements). We suggest a strong baseline approach for this formulation which uses reinforcement learning. It's ability to generalise (from as few as 500 training texts) shows that universal adversarial patterns exist in the text domain as well.
Deepchecks: A Library for Testing and Validating Machine Learning Models and Data
Mar 16, 2022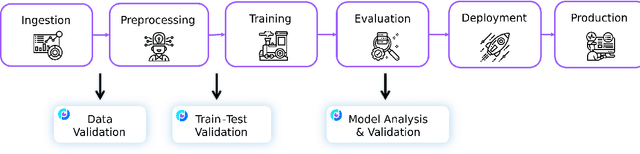
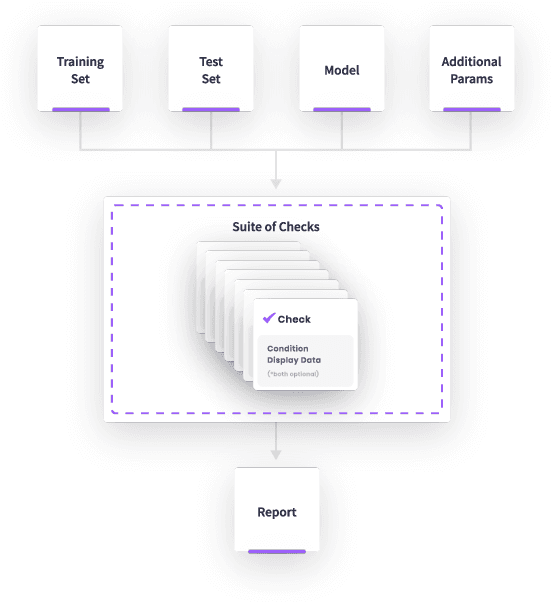
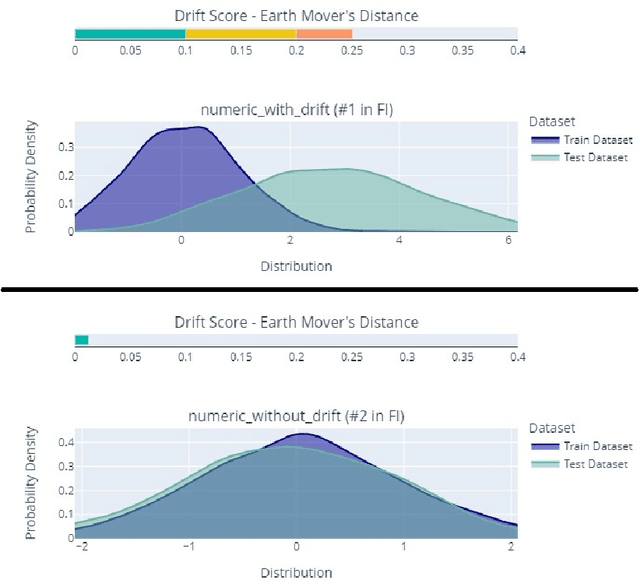
This paper presents Deepchecks, a Python library for comprehensively validating machine learning models and data. Our goal is to provide an easy-to-use library comprising of many checks related to various types of issues, such as model predictive performance, data integrity, data distribution mismatches, and more. The package is distributed under the GNU Affero General Public License (AGPL) and relies on core libraries from the scientific Python ecosystem: scikit-learn, PyTorch, NumPy, pandas, and SciPy. Source code, documentation, examples, and an extensive user guide can be found at \url{https://github.com/deepchecks/deepchecks} and \url{https://docs.deepchecks.com/}.
Boosting Anomaly Detection Using Unsupervised Diverse Test-Time Augmentation
Oct 29, 2021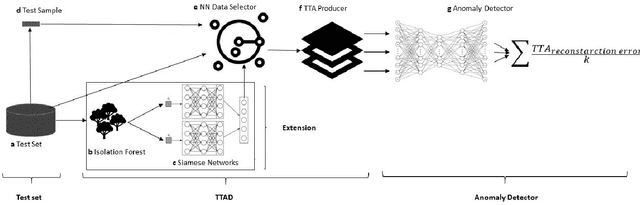
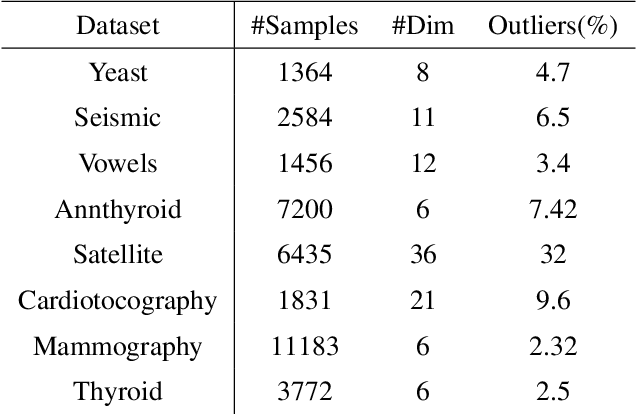
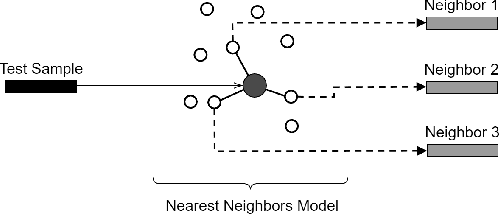
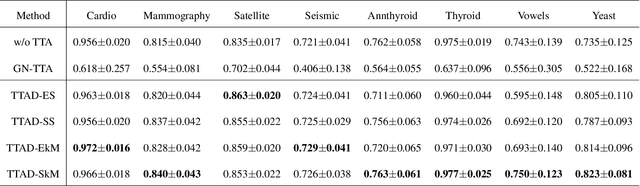
Anomaly detection is a well-known task that involves the identification of abnormal events that occur relatively infrequently. Methods for improving anomaly detection performance have been widely studied. However, no studies utilizing test-time augmentation (TTA) for anomaly detection in tabular data have been performed. TTA involves aggregating the predictions of several synthetic versions of a given test sample; TTA produces different points of view for a specific test instance and might decrease its prediction bias. We propose the Test-Time Augmentation for anomaly Detection (TTAD) technique, a TTA-based method aimed at improving anomaly detection performance. TTAD augments a test instance based on its nearest neighbors; various methods, including the k-Means centroid and SMOTE methods, are used to produce the augmentations. Our technique utilizes a Siamese network to learn an advanced distance metric when retrieving a test instance's neighbors. Our experiments show that the anomaly detector that uses our TTA technique achieved significantly higher AUC results on all datasets evaluated.
Enhancing Real-World Adversarial Patches with 3D Modeling Techniques
Feb 10, 2021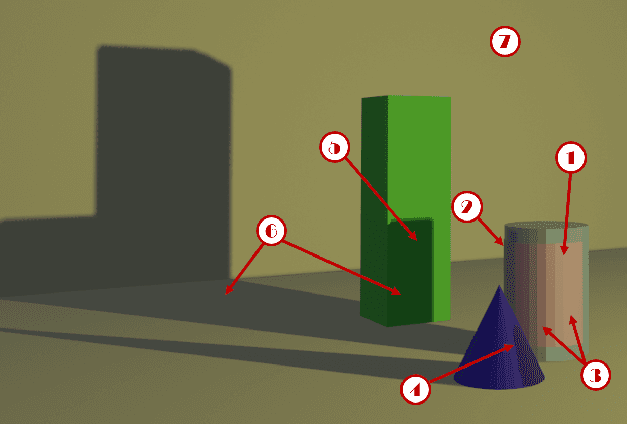
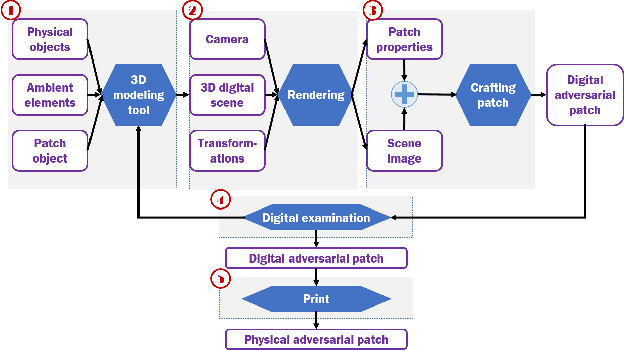


Although many studies have examined adversarial examples in the real world, most of them relied on 2D photos of the attack scene; thus, the attacks proposed cannot address realistic environments with 3D objects or varied conditions. Studies that use 3D objects are limited, and in many cases, the real-world evaluation process is not replicable by other researchers, preventing others from reproducing the results. In this study, we present a framework that crafts an adversarial patch for an existing real-world scene. Our approach uses a 3D digital approximation of the scene as a simulation of the real world. With the ability to add and manipulate any element in the digital scene, our framework enables the attacker to improve the patch's robustness in real-world settings. We use the framework to create a patch for an everyday scene and evaluate its performance using a novel evaluation process that ensures that our results are reproducible in both the digital space and the real world. Our evaluation results show that the framework can generate adversarial patches that are robust to different settings in the real world.
Automatic selection of clustering algorithms using supervised graph embedding
Nov 16, 2020
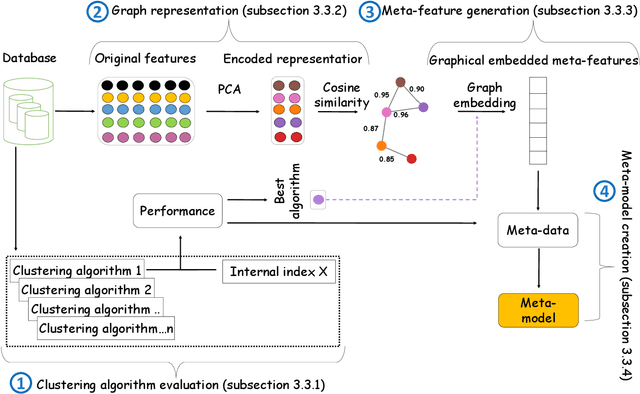


The widespread adoption of machine learning (ML) techniques and the extensive expertise required to apply them have led to increased interest in automated ML solutions that reduce the need for human intervention. One of the main challenges in applying ML to previously unseen problems is algorithm selection - the identification of high-performing algorithm(s) for a given dataset, task, and evaluation measure. This study addresses the algorithm selection challenge for data clustering, a fundamental task in data mining that is aimed at grouping similar objects. We present MARCO-GE, a novel meta-learning approach for the automated recommendation of clustering algorithms. MARCO-GE first transforms datasets into graphs and then utilizes a graph convolutional neural network technique to extract their latent representation. Using the embedding representations obtained, MARCO-GE trains a ranking meta-model capable of accurately recommending top-performing algorithms for a new dataset and clustering evaluation measure. Extensive evaluation on 210 datasets, 13 clustering algorithms, and 10 clustering measures demonstrates the effectiveness of our approach and its dominance in terms of predictive and generalization performance over state-of-the-art clustering meta-learning approaches.