 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiutao Yu
Direct Training High-Performance Deep Spiking Neural Networks: A Review of Theories and Methods
May 06, 2024
Spiking neural networks (SNNs) offer a promising energy-efficient alternative to artificial neural networks (ANNs), in virtue of their high biological plausibility, rich spatial-temporal dynamics, and event-driven computation. The direct training algorithms based on the surrogate gradient method provide sufficient flexibility to design novel SNN architectures and explore the spatial-temporal dynamics of SNNs. According to previous studies, the performance of models is highly dependent on their sizes. Recently, direct training deep SNNs have achieved great progress on both neuromorphic datasets and large-scale static datasets. Notably, transformer-based SNNs show comparable performance with their ANN counterparts. In this paper, we provide a new perspective to summarize the theories and methods for training deep SNNs with high performance in a systematic and comprehensive way, including theory fundamentals, spiking neuron models, advanced SNN models and residual architectures, software frameworks and neuromorphic hardware, applications, and future trends. The reviewed papers are collected at https://github.com/zhouchenlin2096/Awesome-Spiking-Neural-Networks
QKFormer: Hierarchical Spiking Transformer using Q-K Attention
Mar 25, 2024



Spiking Transformers, which integrate Spiking Neural Networks (SNNs) with Transformer architectures, have attracted significant attention due to their potential for energy efficiency and high performance. However, existing models in this domain still suffer from suboptimal performance. We introduce several innovations to improve the performance: i) We propose a novel spike-form Q-K attention mechanism, tailored for SNNs, which efficiently models the importance of token or channel dimensions through binary vectors with linear complexity. ii) We incorporate the hierarchical structure, which significantly benefits the performance of both the brain and artificial neural networks, into spiking transformers to obtain multi-scale spiking representation. iii) We design a versatile and powerful patch embedding module with a deformed shortcut specifically for spiking transformers. Together, we develop QKFormer, a hierarchical spiking transformer based on Q-K attention with direct training. QKFormer shows significantly superior performance over existing state-of-the-art SNN models on various mainstream datasets. Notably, with comparable size to Spikformer (66.34 M, 74.81%), QKFormer (64.96 M) achieves a groundbreaking top-1 accuracy of 85.65% on ImageNet-1k, substantially outperforming Spikformer by 10.84%. To our best knowledge, this is the first time that directly training SNNs have exceeded 85% accuracy on ImageNet-1K. The code and models are publicly available at https://github.com/zhouchenlin2096/QKFormer
Enhancing the Performance of Transformer-based Spiking Neural Networks by SNN-optimized Downsampling with Precise Gradient Backpropagation
May 19, 2023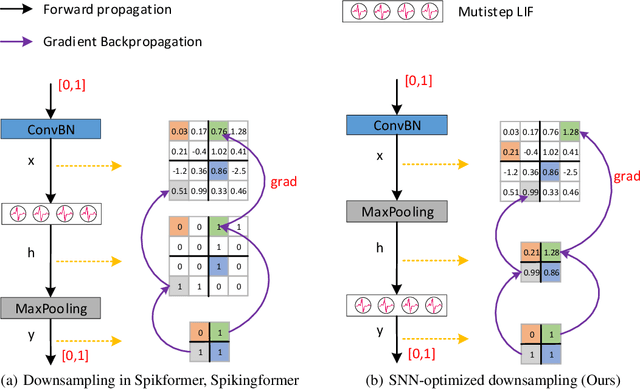

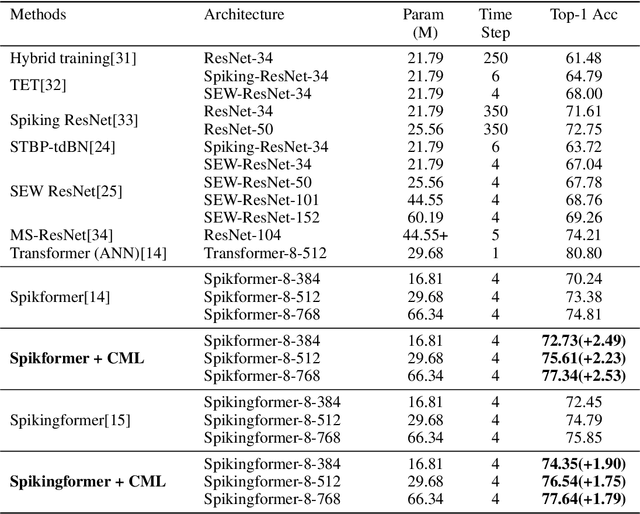
Deep spiking neural networks (SNNs) have drawn much attention in recent years because of their low power consumption, biological rationality and event-driven property. However, state-of-the-art deep SNNs (including Spikformer and Spikingformer) suffer from a critical challenge related to the imprecise gradient backpropagation. This problem arises from the improper design of downsampling modules in these networks, and greatly hampering the overall model performance. In this paper, we propose ConvBN-MaxPooling-LIF (CML), an SNN-optimized downsampling with precise gradient backpropagation. We prove that CML can effectively overcome the imprecision of gradient backpropagation from a theoretical perspective. In addition, we evaluate CML on ImageNet, CIFAR10, CIFAR100, CIFAR10-DVS, DVS128-Gesture datasets, and show state-of-the-art performance on all these datasets with significantly enhanced performances compared with Spikingformer. For instance, our model achieves 77.64 $\%$ on ImageNet, 96.04 $\%$ on CIFAR10, 81.4$\%$ on CIFAR10-DVS, with + 1.79$\%$ on ImageNet, +1.16$\%$ on CIFAR100 compared with Spikingformer.
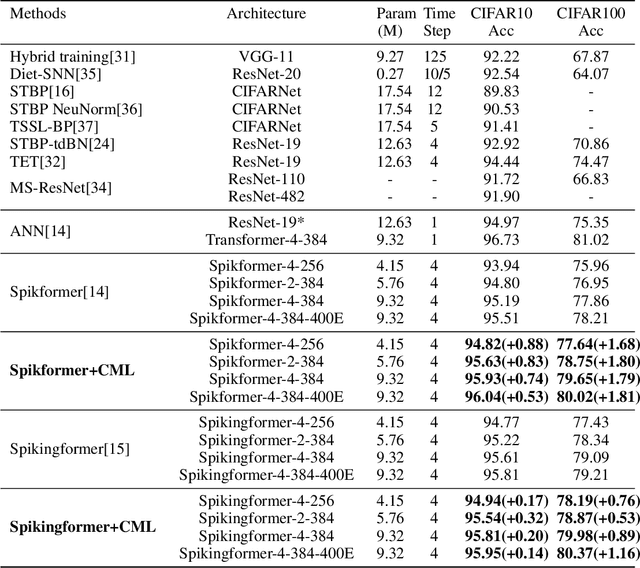
Spikingformer: Spike-driven Residual Learning for Transformer-based Spiking Neural Network
Apr 24, 2023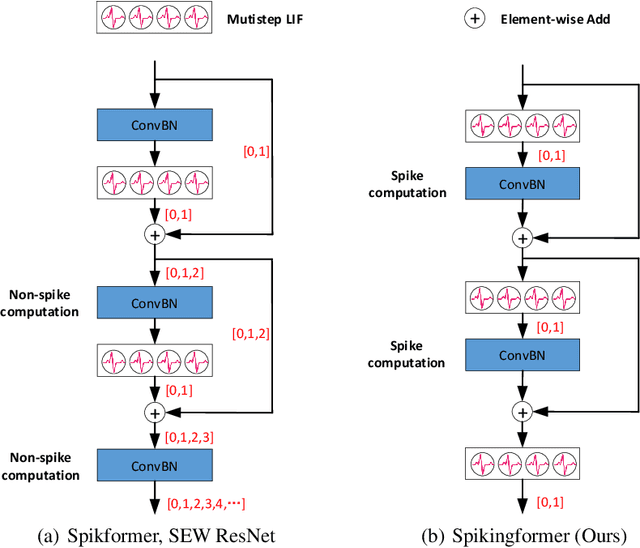
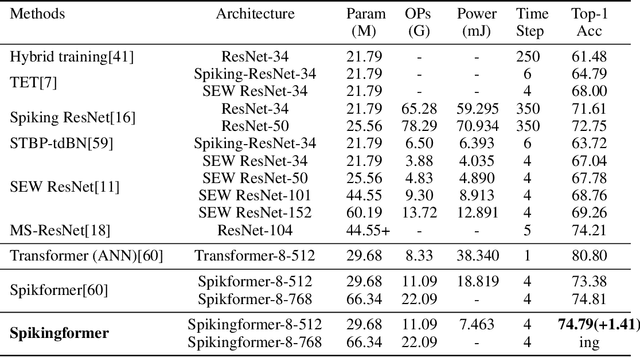

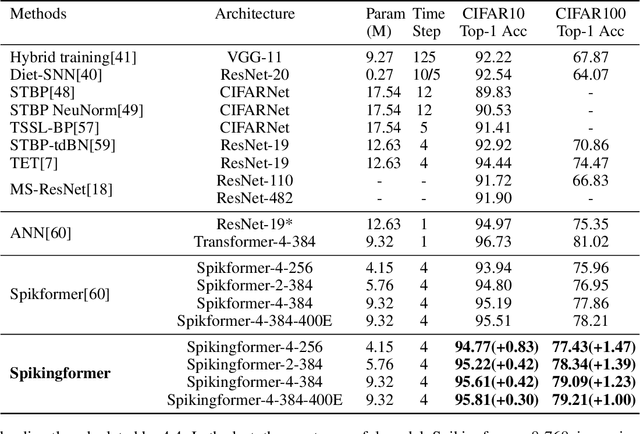
Spiking neural networks (SNNs) offer a promising energy-efficient alternative to artificial neural networks, due to their event-driven spiking computation. However, state-of-the-art deep SNNs (including Spikformer and SEW ResNet) suffer from non-spike computations (integer-float multiplications) caused by the structure of their residual connection. These non-spike computations increase SNNs' power consumption and make them unsuitable for deployment on mainstream neuromorphic hardware, which only supports spike operations. In this paper, we propose a hardware-friendly spike-driven residual learning architecture for SNNs to avoid non-spike computations. Based on this residual design, we develop Spikingformer, a pure transformer-based spiking neural network. We evaluate Spikingformer on ImageNet, CIFAR10, CIFAR100, CIFAR10-DVS and DVS128 Gesture datasets, and demonstrated that Spikingformer outperforms the state-of-the-art in directly trained pure SNNs as a novel advanced backbone (74.79$\%$ top-1 accuracy on ImageNet, + 1.41$\%$ compared with Spikformer). Furthermore, our experiments verify that Spikingformer effectively avoids non-spike computations and reduces energy consumption by 60.34$\%$ compared with Spikformer on ImageNet. To our best knowledge, this is the first time that a pure event-driven transformer-based SNN has been developed.
Deep Spiking Neural Networks with High Representation Similarity Model Visual Pathways of Macaque and Mouse
Mar 09, 2023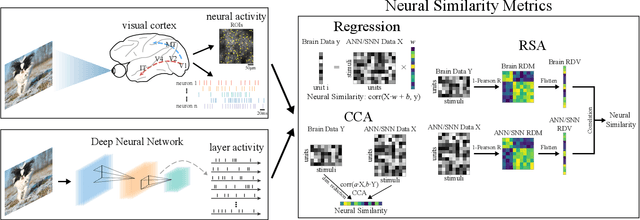

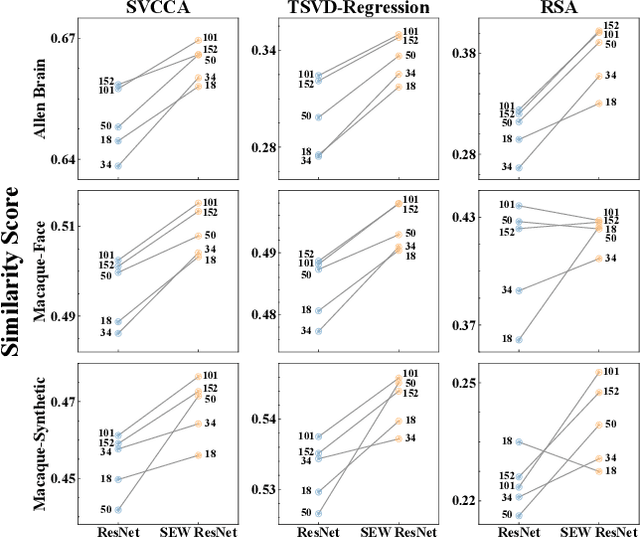

Deep artificial neural networks (ANNs) play a major role in modeling the visual pathways of primate and rodent. However, they highly simplify the computational properties of neurons compared to their biological counterparts. Instead, Spiking Neural Networks (SNNs) are more biologically plausible models since spiking neurons encode information with time sequences of spikes, just like biological neurons do. However, there is a lack of studies on visual pathways with deep SNNs models. In this study, we model the visual cortex with deep SNNs for the first time, and also with a wide range of state-of-the-art deep CNNs and ViTs for comparison. Using three similarity metrics, we conduct neural representation similarity experiments on three neural datasets collected from two species under three types of stimuli. Based on extensive similarity analyses, we further investigate the functional hierarchy and mechanisms across species. Almost all similarity scores of SNNs are higher than their counterparts of CNNs with an average of 6.6%. Depths of the layers with the highest similarity scores exhibit little differences across mouse cortical regions, but vary significantly across macaque regions, suggesting that the visual processing structure of mice is more regionally homogeneous than that of macaques. Besides, the multi-branch structures observed in some top mouse brain-like neural networks provide computational evidence of parallel processing streams in mice, and the different performance in fitting macaque neural representations under different stimuli exhibits the functional specialization of information processing in macaques. Taken together, our study demonstrates that SNNs could serve as promising candidates to better model and explain the functional hierarchy and mechanisms of the visual system.