 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLucas C. Uzal
Exploiting GAN Internal Capacity for High-Quality Reconstruction of Natural Images
Oct 26, 2019
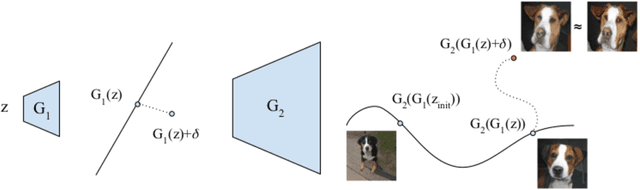



Generative Adversarial Networks (GAN) have demonstrated impressive results in modeling the distribution of natural images, learning latent representations that capture semantic variations in an unsupervised basis. Beyond the generation of novel samples, it is of special interest to exploit the ability of the GAN generator to model the natural image manifold and hence generate credible changes when manipulating images. However, this line of work is conditioned by the quality of the reconstruction. Until now, only inversion to the latent space has been considered, we propose to exploit the representation in intermediate layers of the generator, and we show that this leads to increased capacity. In particular, we observe that the representation after the first dense layer, present in all state-of-the-art GAN models, is expressive enough to represent natural images with high visual fidelity. It is possible to interpolate around these images obtaining a sequence of new plausible synthetic images that cannot be generated from the latent space. Finally, as an example of potential applications that arise from this inversion mechanism, we show preliminary results in exploiting the learned representation in the attention map of the generator to obtain an unsupervised segmentation of natural images.
Exploiting video sequences for unsupervised disentangling in generative adversarial networks
Oct 16, 2019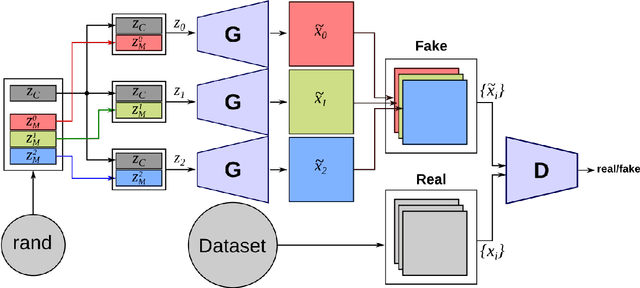



In this work we present an adversarial training algorithm that exploits correlations in video to learn --without supervision-- an image generator model with a disentangled latent space. The proposed methodology requires only a few modifications to the standard algorithm of Generative Adversarial Networks (GAN) and involves training with sets of frames taken from short videos. We train our model over two datasets of face-centered videos which present different people speaking or moving the head: VidTIMIT and YouTube Faces datasets. We found that our proposal allows us to split the generator latent space into two subspaces. One of them controls content attributes, those that do not change along short video sequences. For the considered datasets, this is the identity of the generated face. The other subspace controls motion attributes, those attributes that are observed to change along short videos. We observed that these motion attributes are face expressions, head orientation, lips and eyes movement. The presented experiments provide quantitative and qualitative evidence supporting that the proposed methodology induces a disentangling of this two kinds of attributes in the latent space.
Class-Splitting Generative Adversarial Networks
May 17, 2018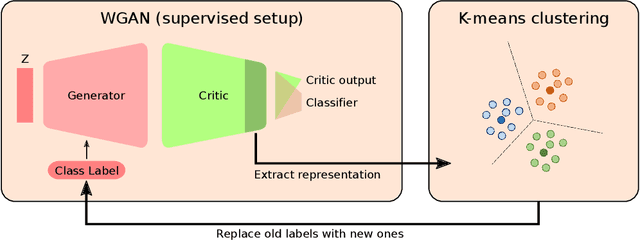

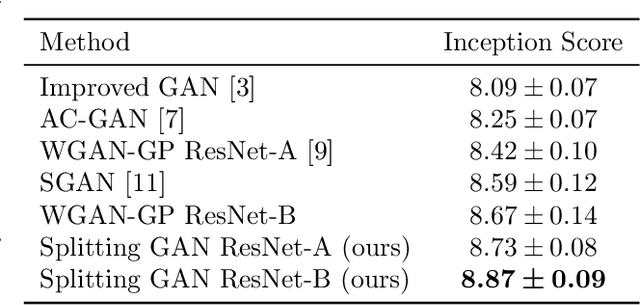

Generative Adversarial Networks (GANs) produce systematically better quality samples when class label information is provided., i.e. in the conditional GAN setup. This is still observed for the recently proposed Wasserstein GAN formulation which stabilized adversarial training and allows considering high capacity network architectures such as ResNet. In this work we show how to boost conditional GAN by augmenting available class labels. The new classes come from clustering in the representation space learned by the same GAN model. The proposed strategy is also feasible when no class information is available, i.e. in the unsupervised setup. Our generated samples reach state-of-the-art Inception scores for CIFAR-10 and STL-10 datasets in both supervised and unsupervised setup.