 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuna M. Zhang
Pairwise Neural Networks (PairNets) with Low Memory for Fast On-Device Applications
Feb 10, 2020
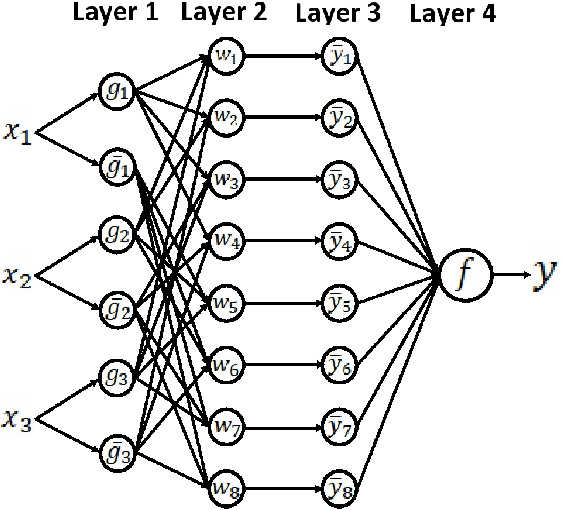
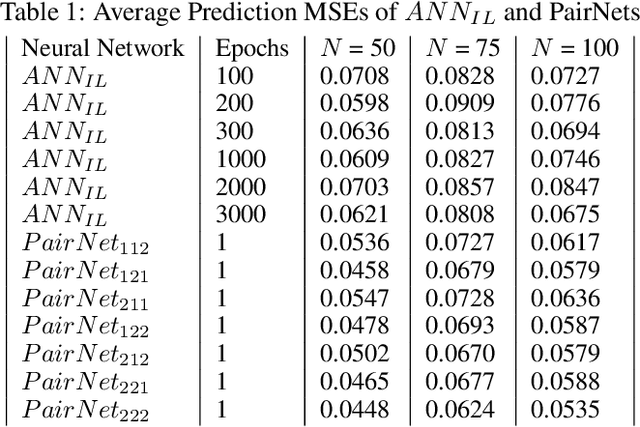
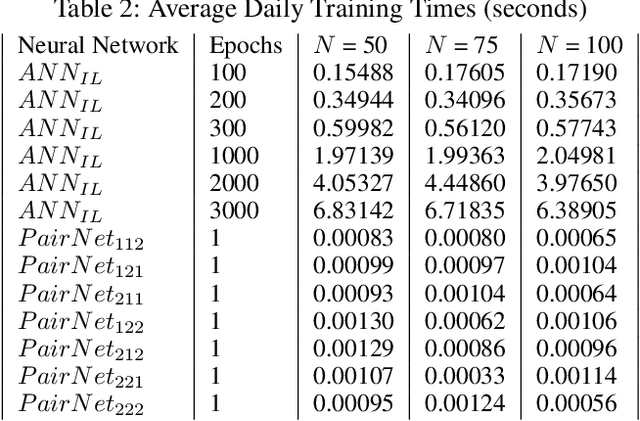
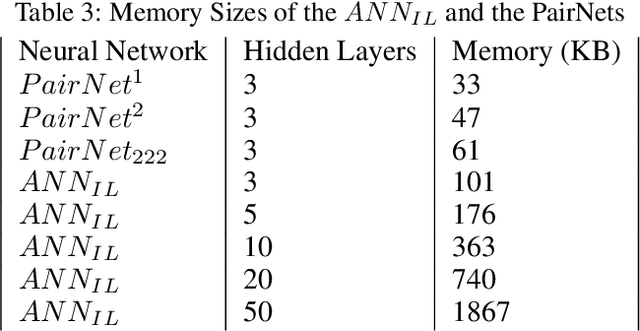
A traditional artificial neural network (ANN) is normally trained slowly by a gradient descent algorithm, such as the backpropagation algorithm, since a large number of hyperparameters of the ANN need to be fine-tuned with many training epochs. Since a large number of hyperparameters of a deep neural network, such as a convolutional neural network, occupy much memory, a memory-inefficient deep learning model is not ideal for real-time Internet of Things (IoT) applications on various devices, such as mobile phones. Thus, it is necessary to develop fast and memory-efficient Artificial Intelligence of Things (AIoT) systems for real-time on-device applications. We created a novel wide and shallow 4-layer ANN called "Pairwise Neural Network" ("PairNet") with high-speed non-gradient-descent hyperparameter optimization. The PairNet is trained quickly with only one epoch since its hyperparameters are directly optimized one-time via simply solving a system of linear equations by using the multivariate least squares fitting method. In addition, an n-input space is partitioned into many n-input data subspaces, and a local PairNet is built in a local n-input subspace. This divide-and-conquer approach can train the local PairNet using specific local features to improve model performance. Simulation results indicate that the three PairNets with incremental learning have smaller average prediction mean squared errors, and achieve much higher speeds than traditional ANNs. An important future work is to develop better and faster non-gradient-descent hyperparameter optimization algorithms to generate effective, fast, and memory-efficient PairNets with incremental learning on optimal subspaces for real-time AIoT on-device applications.
PairNets: Novel Fast Shallow Artificial Neural Networks on Partitioned Subspaces
Jan 24, 2020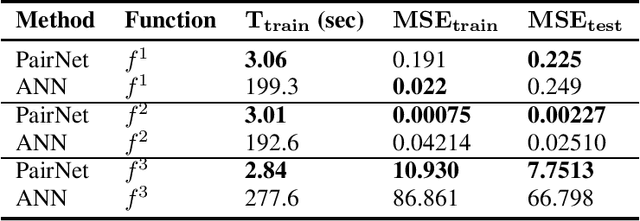
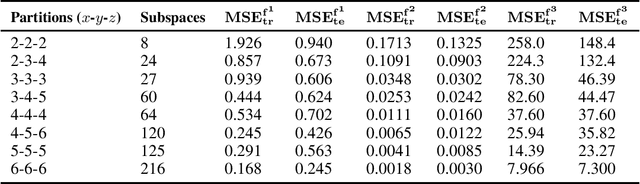
Traditionally, an artificial neural network (ANN) is trained slowly by a gradient descent algorithm such as the backpropagation algorithm since a large number of hyperparameters of the ANN need to be fine-tuned with many training epochs. To highly speed up training, we created a novel shallow 4-layer ANN called "Pairwise Neural Network" ("PairNet") with high-speed hyperparameter optimization. In addition, a value of each input is partitioned into multiple intervals, and then an n-dimensional space is partitioned into M n-dimensional subspaces. M local PairNets are built in M partitioned local n-dimensional subspaces. A local PairNet is trained very quickly with only one epoch since its hyperparameters are directly optimized one-time via simply solving a system of linear equations by using the multivariate least squares fitting method. Simulation results for three regression problems indicated that the PairNet achieved much higher speeds and lower average testing mean squared errors (MSEs) for the three cases, and lower average training MSEs for two cases than the traditional ANNs. A significant future work is to develop better and faster optimization algorithms based on intelligent methods and parallel computing methods to optimize both partitioned subspaces and hyperparameters to build the fast and effective PairNets for applications in big data mining and real-time machine learning.
A New Compensatory Genetic Algorithm-Based Method for Effective Compressed Multi-function Convolutional Neural Network Model Selection with Multi-Objective Optimization
Jun 08, 2019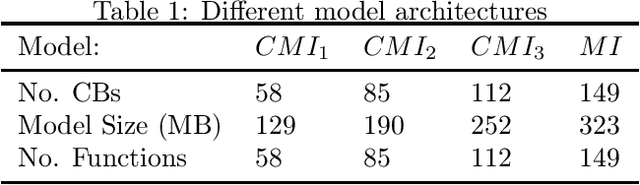
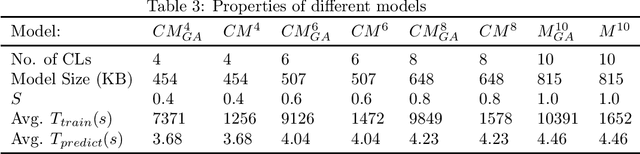
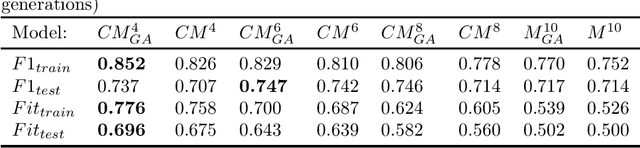
In recent years, there have been many popular Convolutional Neural Networks (CNNs), such as Google's Inception-V4, that have performed very well for various image classification problems. These commonly used CNN models usually use the same activation function, such as RELU, for all neurons in the convolutional layers; they are "Single-function CNNs." However, SCNNs may not always be optimal. Thus, a "Multi-function CNN" (MCNN), which uses different activation functions for different neurons, has been shown to outperform a SCNN. Also, CNNs typically have very large architectures that use a lot of memory and need a lot of data in order to be trained well. As a result, they tend to have very high training and prediction times too. An important research problem is how to automatically and efficiently find the best CNN with both high classification performance and compact architecture with high training and prediction speeds, small power usage, and small memory size for any image classification problem. It is very useful to intelligently find an effective, fast, energy-efficient, and memory-efficient "Compressed Multi-function CNN" (CMCNN) from a large number of candidate MCNNs. A new compensatory algorithm using a new genetic algorithm (GA) is created to find the best CMCNN with an ideal compensation between performance and architecture size. The optimal CMCNN has the best performance and the smallest architecture size. Simulations using the CIFAR10 dataset showed that the new compensatory algorithm could find CMCNNs that could outperform non-compressed MCNNs in terms of classification performance (F1-score), speed, power usage, and memory usage. Other effective, fast, power-efficient, and memory-efficient CMCNNs based on popular CNN architectures will be developed for image classification problems in important real-world applications, such as brain informatics and biomedical imaging.
Effective, Fast, and Memory-Efficient Compressed Multi-function Convolutional Neural Networks for More Accurate Medical Image Classification
Nov 29, 2018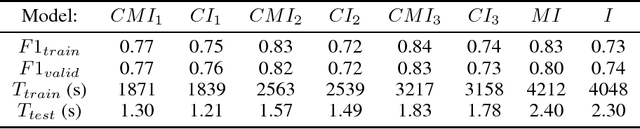
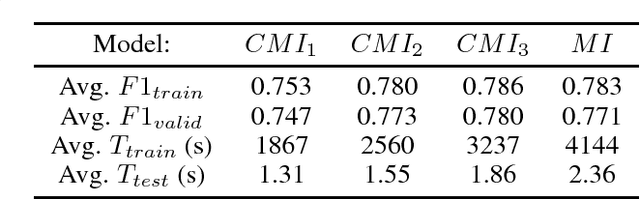
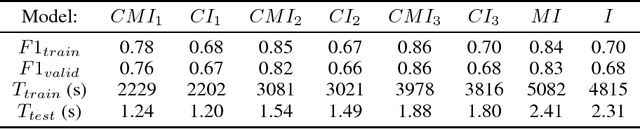
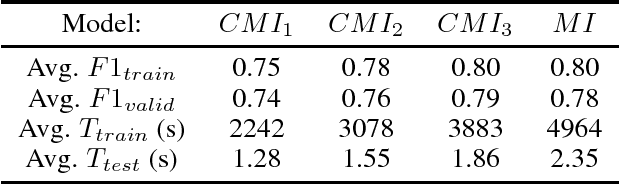
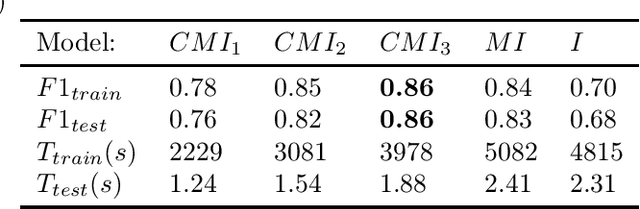
Convolutional Neural Networks (CNNs) usually use the same activation function, such as RELU, for all convolutional layers. There are performance limitations of just using RELU. In order to achieve better classification performance, reduce training and testing times, and reduce power consumption and memory usage, a new "Compressed Multi-function CNN" is developed. Google's Inception-V4, for example, is a very deep CNN that consists of 4 Inception-A blocks, 7 Inception-B blocks, and 3 Inception-C blocks. RELU is used for all convolutional layers. A new "Compressed Multi-function Inception-V4" (CMI) that can use different activation functions is created with k Inception-A blocks, m Inception-B blocks, and n Inception-C blocks where k in {1, 2, 3, 4}, m in {1, 2, 3, 4, 5, 6, 7}, n in {1, 2, 3}, and (k+m+n)<14. For performance analysis, a dataset for classifying brain MRI images into one of the four stages of Alzheimer's disease is used to compare three CMI architectures with Inception-V4 in terms of F1-score, training and testing times (related to power consumption), and memory usage (model size). Overall, simulations show that the new CMI models can outperform both the commonly used Inception-V4 and Inception-V4 using different activation functions. In the future, other "Compressed Multi-function CNNs", such as "Compressed Multi-function ResNets and DenseNets" that have a reduced number of convolutional blocks using different activation functions, will be developed to further increase classification accuracy, reduce training and testing times, reduce computational power, and reduce memory usage (model size) for building more effective healthcare systems, such as implementing accurate and convenient disease diagnosis systems on mobile devices that have limited battery power and memory.
Multi-function Convolutional Neural Networks for Improving Image Classification Performance
May 30, 2018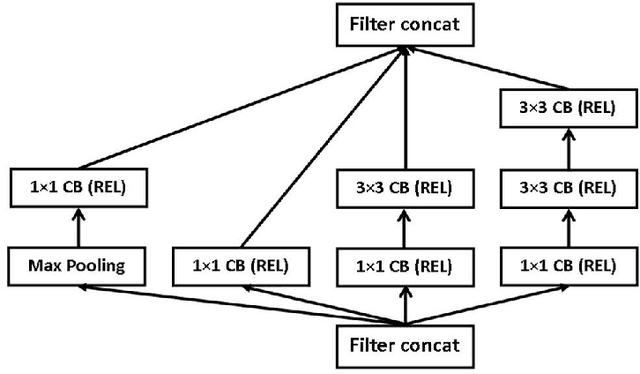

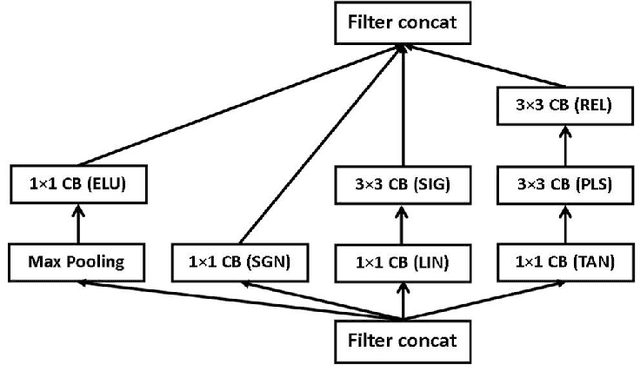

Traditional Convolutional Neural Networks (CNNs) typically use the same activation function (usually ReLU) for all neurons with non-linear mapping operations. For example, the deep convolutional architecture Inception-v4 uses ReLU. To improve the classification performance of traditional CNNs, a new "Multi-function Convolutional Neural Network" (MCNN) is created by using different activation functions for different neurons. For $n$ neurons and $m$ different activation functions, there are a total of $m^n-m$ MCNNs and only $m$ traditional CNNs. Therefore, the best model is very likely to be chosen from MCNNs because there are $m^n-2m$ more MCNNs than traditional CNNs. For performance analysis, two different datasets for two applications (classifying handwritten digits from the MNIST database and classifying brain MRI images into one of the four stages of Alzheimer's disease (AD)) are used. For both applications, an activation function is randomly selected for each layer of a MCNN. For the AD diagnosis application, MCNNs using a newly created multi-function Inception-v4 architecture are constructed. Overall, simulations show that MCNNs can outperform traditional CNNs in terms of multi-class classification accuracy for both applications. An important future research work will be to efficiently select the best MCNN from $m^n-m$ candidate MCNNs. Current CNN software only provides users with partial functionality of MCNNs since different layers can use different activation functions but not individual neurons in the same layer. Thus, modifying current CNN software systems such as ResNets, DenseNets, and Dual Path Networks by using multiple activation functions and developing more effective and faster MCNN software systems and tools would be very useful to solve difficult practical image classification problems.