 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuziwei Leng
Weakly-Supervised Action Localization by Hierarchically-structured Latent Attention Modeling
Aug 19, 2023

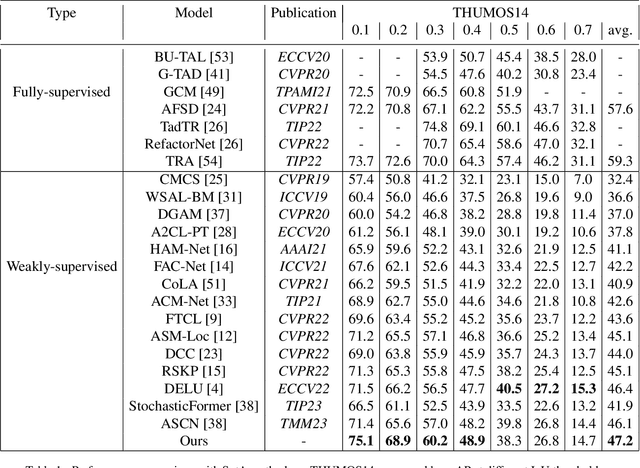
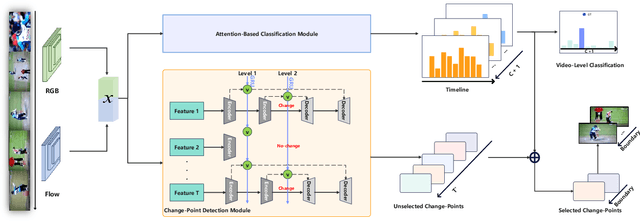
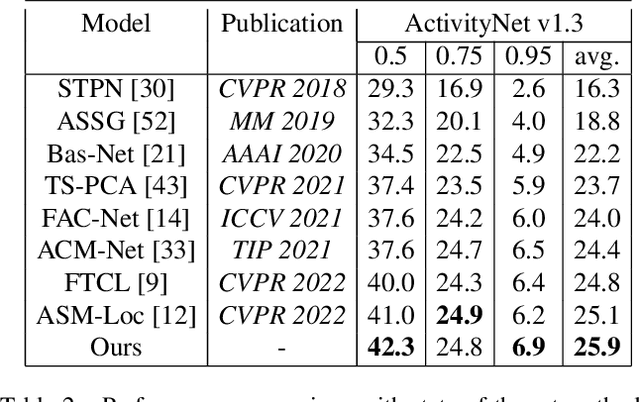
Weakly-supervised action localization aims to recognize and localize action instancese in untrimmed videos with only video-level labels. Most existing models rely on multiple instance learning(MIL), where the predictions of unlabeled instances are supervised by classifying labeled bags. The MIL-based methods are relatively well studied with cogent performance achieved on classification but not on localization. Generally, they locate temporal regions by the video-level classification but overlook the temporal variations of feature semantics. To address this problem, we propose a novel attention-based hierarchically-structured latent model to learn the temporal variations of feature semantics. Specifically, our model entails two components, the first is an unsupervised change-points detection module that detects change-points by learning the latent representations of video features in a temporal hierarchy based on their rates of change, and the second is an attention-based classification model that selects the change-points of the foreground as the boundaries. To evaluate the effectiveness of our model, we conduct extensive experiments on two benchmark datasets, THUMOS-14 and ActivityNet-v1.3. The experiments show that our method outperforms current state-of-the-art methods, and even achieves comparable performance with fully-supervised methods.
Automotive Object Detection via Learning Sparse Events by Temporal Dynamics of Spiking Neurons
Jul 24, 2023

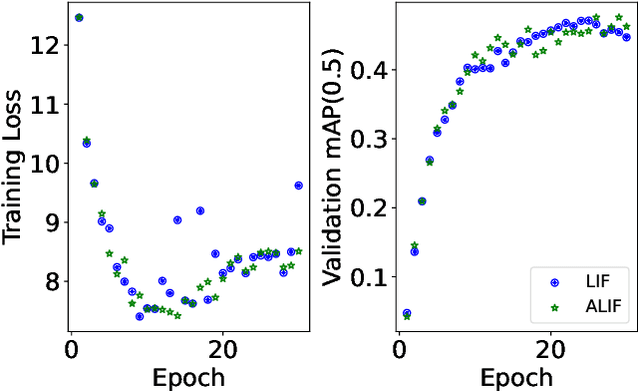

Event-based sensors, with their high temporal resolution (1us) and dynamical range (120dB), have the potential to be deployed in high-speed platforms such as vehicles and drones. However, the highly sparse and fluctuating nature of events poses challenges for conventional object detection techniques based on Artificial Neural Networks (ANNs). In contrast, Spiking Neural Networks (SNNs) are well-suited for representing event-based data due to their inherent temporal dynamics. In particular, we demonstrate that the membrane potential dynamics can modulate network activity upon fluctuating events and strengthen features of sparse input. In addition, the spike-triggered adaptive threshold can stabilize training which further improves network performance. Based on this, we develop an efficient spiking feature pyramid network for event-based object detection. Our proposed SNN outperforms previous SNNs and sophisticated ANNs with attention mechanisms, achieving a mean average precision (map50) of 47.7% on the Gen1 benchmark dataset. This result significantly surpasses the previous best SNN by 9.7% and demonstrates the potential of SNNs for event-based vision. Our model has a concise architecture while maintaining high accuracy and much lower computation cost as a result of sparse computation. Our code will be publicly available.
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023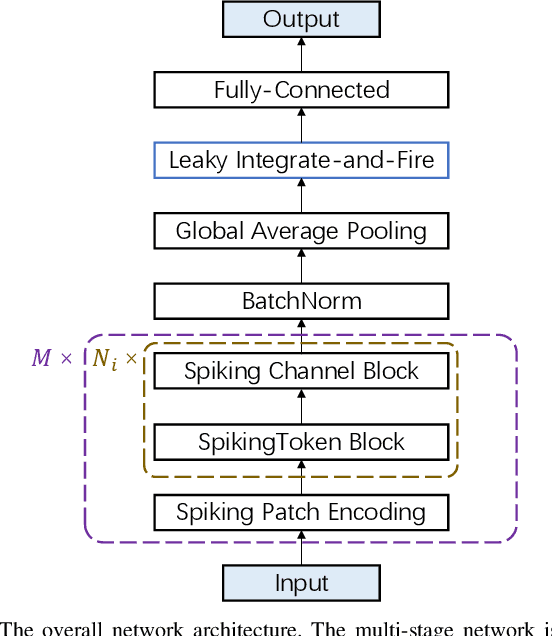
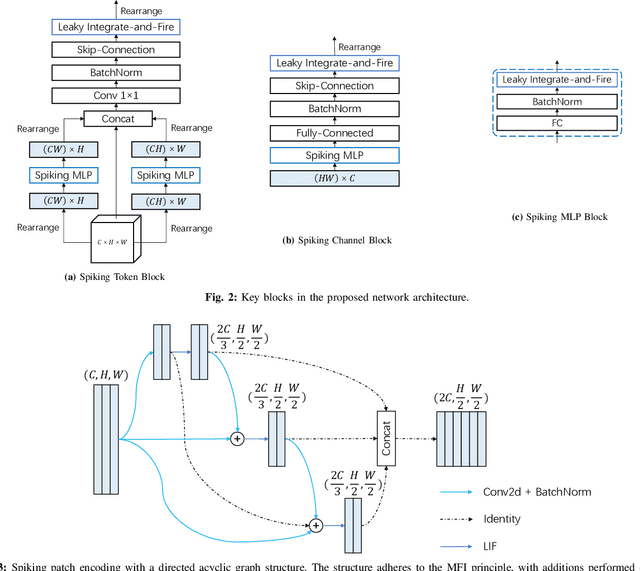
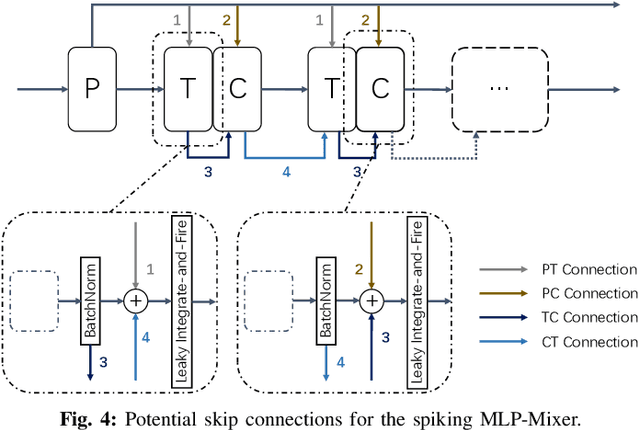
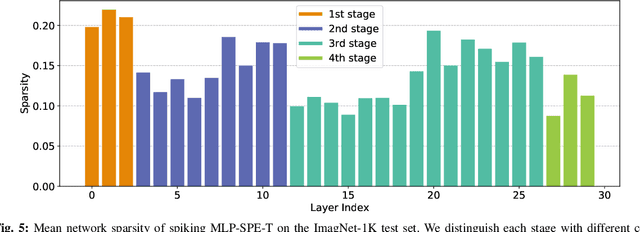
Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.
Accurate and Efficient Event-based Semantic Segmentation Using Adaptive Spiking Encoder-Decoder Network
Apr 24, 2023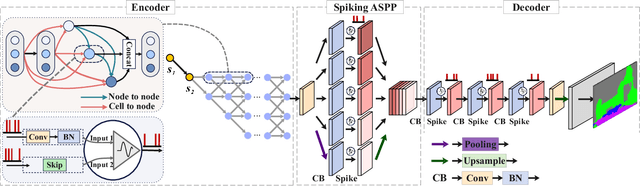
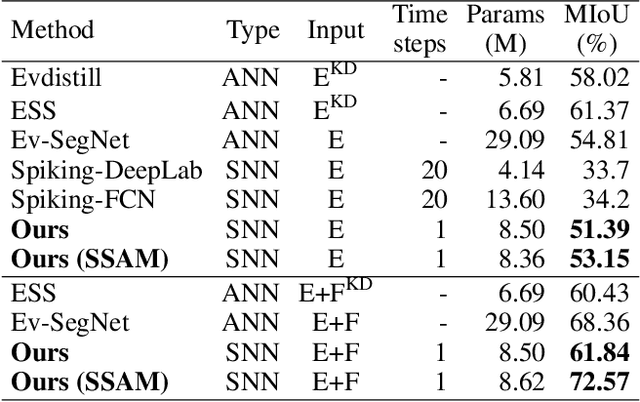
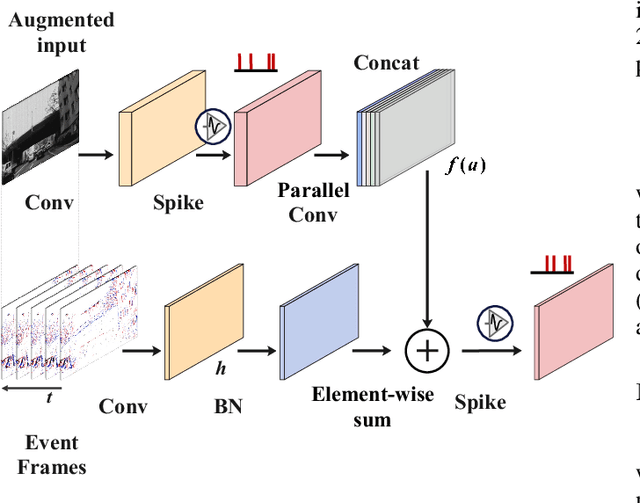
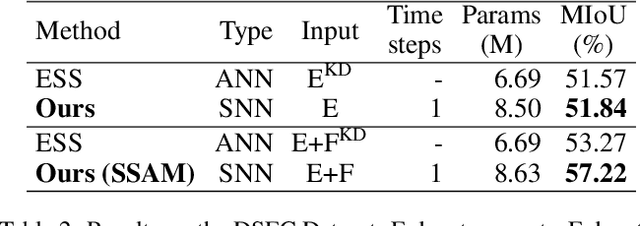
Low-power event-driven computation and inherent temporal dynamics render spiking neural networks (SNNs) ideal candidates for processing highly dynamic and asynchronous signals from event-based sensors. However, due to the challenges in training and architectural design constraints, there is a scarcity of competitive demonstrations of SNNs in event-based dense prediction compared to artificial neural networks (ANNs). In this work, we construct an efficient spiking encoder-decoder network for large-scale event-based semantic segmentation tasks, optimizing the encoder with hierarchical search. To improve learning from highly dynamic event streams, we exploit the intrinsic adaptive threshold of spiking neurons to modulate network activation. Additionally, we develop a dual-path spiking spatially-adaptive modulation (SSAM) block to enhance the representation of sparse events, significantly improving network performance. Our network achieves 72.57% mean intersection over union (MIoU) on the DDD17 dataset and 57.22% MIoU on the newly proposed larger DSEC-Semantic dataset, surpassing current record ANNs by 4% while utilizing much lower computation costs. To the best of our knowledge, this is the first instance of SNNs outperforming ANNs in challenging event-based semantic segmentation tasks, demonstrating their immense potential in event-based vision. Our code will be publicly available.
Neuro-Modulated Hebbian Learning for Fully Test-Time Adaptation
Mar 10, 2023



Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. We take inspiration from the biological plausibility learning where the neuron responses are tuned based on a local synapse-change procedure and activated by competitive lateral inhibition rules. Based on these feed-forward learning rules, we design a soft Hebbian learning process which provides an unsupervised and effective mechanism for online adaptation. We observe that the performance of this feed-forward Hebbian learning for fully test-time adaptation can be significantly improved by incorporating a feedback neuro-modulation layer. It is able to fine-tune the neuron responses based on the external feedback generated by the error back-propagation from the top inference layers. This leads to our proposed neuro-modulated Hebbian learning (NHL) method for fully test-time adaptation. With the unsupervised feed-forward soft Hebbian learning being combined with a learned neuro-modulator to capture feedback from external responses, the source model can be effectively adapted during the testing process. Experimental results on benchmark datasets demonstrate that our proposed method can significantly improve the adaptation performance of network models and outperforms existing state-of-the-art methods.
Generative models on accelerated neuromorphic hardware
Jul 11, 2018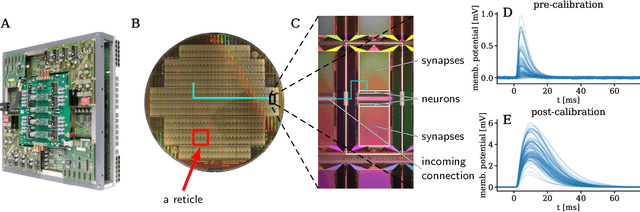
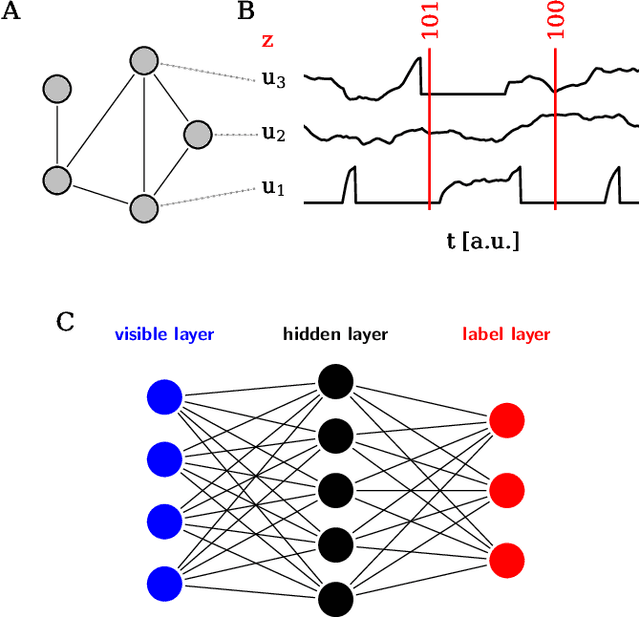
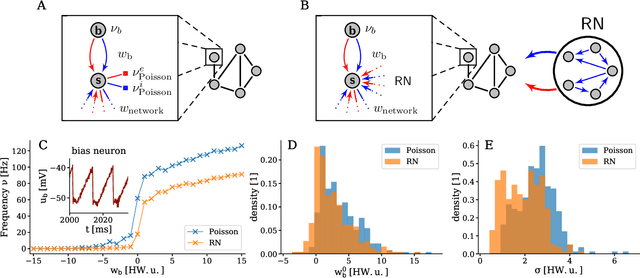
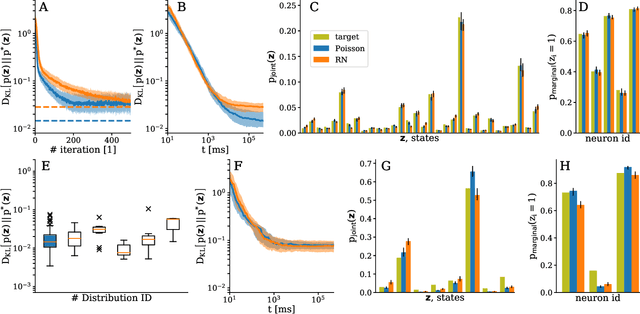
The traditional von Neumann computer architecture faces serious obstacles, both in terms of miniaturization and in terms of heat production, with increasing performance. Artificial neural (neuromorphic) substrates represent an alternative approach to tackle this challenge. A special subset of these systems follow the principle of "physical modeling" as they directly use the physical properties of the underlying substrate to realize computation with analog components. While these systems are potentially faster and/or more energy efficient than conventional computers, they require robust models that can cope with their inherent limitations in terms of controllability and range of parameters. A natural source of inspiration for robust models is neuroscience as the brain faces similar challenges. It has been recently suggested that sampling with the spiking dynamics of neurons is potentially suitable both as a generative and a discriminative model for artificial neural substrates. In this work we present the implementation of sampling with leaky integrate-and-fire neurons on the BrainScaleS physical model system. We prove the sampling property of the network and demonstrate its applicability to high-dimensional datasets. The required stochasticity is provided by a spiking random network on the same substrate. This allows the system to run in a self-contained fashion without external stochastic input from the host environment. The implementation provides a basis as a building block in large-scale biologically relevant emulations, as a fast approximate sampler or as a framework to realize on-chip learning on (future generations of) accelerated spiking neuromorphic hardware. Our work contributes to the development of robust computation on physical model systems.
Spiking neurons with short-term synaptic plasticity form superior generative networks
Oct 10, 2017



Spiking networks that perform probabilistic inference have been proposed both as models of cortical computation and as candidates for solving problems in machine learning. However, the evidence for spike-based computation being in any way superior to non-spiking alternatives remains scarce. We propose that short-term plasticity can provide spiking networks with distinct computational advantages compared to their classical counterparts. In this work, we use networks of leaky integrate-and-fire neurons that are trained to perform both discriminative and generative tasks in their forward and backward information processing paths, respectively. During training, the energy landscape associated with their dynamics becomes highly diverse, with deep attractor basins separated by high barriers. Classical algorithms solve this problem by employing various tempering techniques, which are both computationally demanding and require global state updates. We demonstrate how similar results can be achieved in spiking networks endowed with local short-term synaptic plasticity. Additionally, we discuss how these networks can even outperform tempering-based approaches when the training data is imbalanced. We thereby show how biologically inspired, local, spike-triggered synaptic dynamics based simply on a limited pool of synaptic resources can allow spiking networks to outperform their non-spiking relatives.