 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManuela Veloso
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024
Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
Six Levels of Privacy: A Framework for Financial Synthetic Data
Mar 20, 2024Synthetic Data is increasingly important in financial applications. In addition to the benefits it provides, such as improved financial modeling and better testing procedures, it poses privacy risks as well. Such data may arise from client information, business information, or other proprietary sources that must be protected. Even though the process by which Synthetic Data is generated serves to obscure the original data to some degree, the extent to which privacy is preserved is hard to assess. Accordingly, we introduce a hierarchy of ``levels'' of privacy that are useful for categorizing Synthetic Data generation methods and the progressively improved protections they offer. While the six levels were devised in the context of financial applications, they may also be appropriate for other industries as well. Our paper includes: A brief overview of Financial Synthetic Data, how it can be used, how its value can be assessed, privacy risks, and privacy attacks. We close with details of the ``Six Levels'' that include defenses against those attacks.
Intelligent Execution through Plan Analysis
Mar 18, 2024
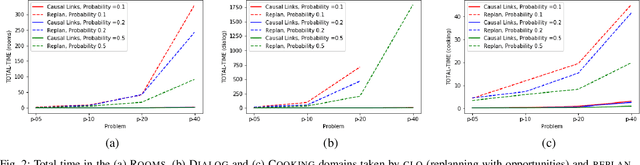
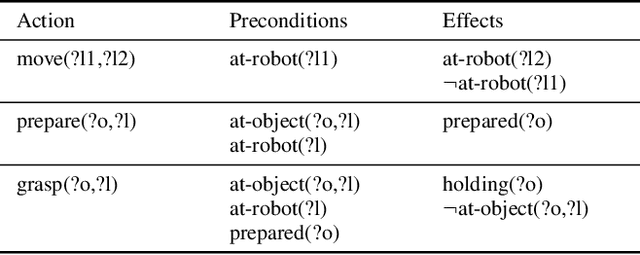

Intelligent robots need to generate and execute plans. In order to deal with the complexity of real environments, planning makes some assumptions about the world. When executing plans, the assumptions are usually not met. Most works have focused on the negative impact of this fact and the use of replanning after execution failures. Instead, we focus on the positive impact, or opportunities to find better plans. When planning, the proposed technique finds and stores those opportunities. Later, during execution, the monitoring system can use them to focus perception and repair the plan, instead of replanning from scratch. Experiments in several paradigmatic robotic tasks show how the approach outperforms standard replanning strategies.
From Pixels to Predictions: Spectrogram and Vision Transformer for Better Time Series Forecasting
Mar 17, 2024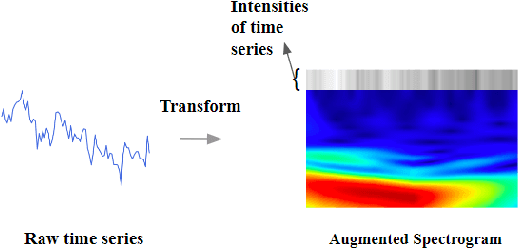
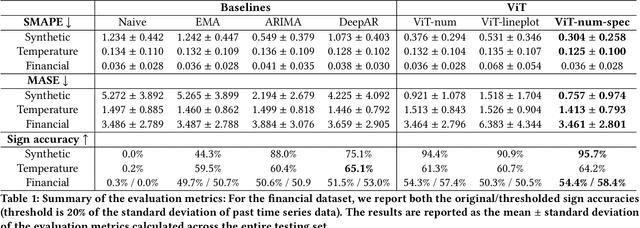
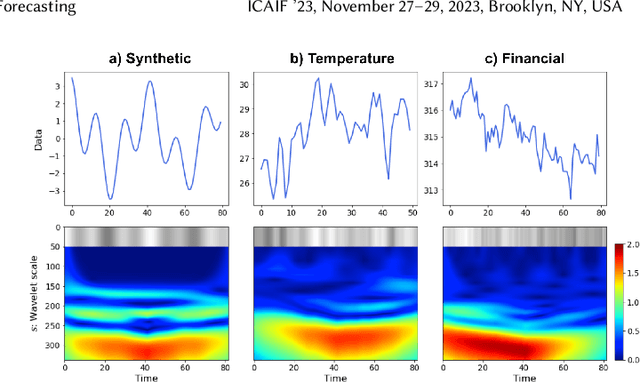
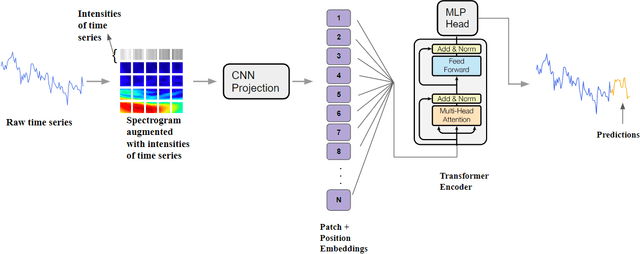
Time series forecasting plays a crucial role in decision-making across various domains, but it presents significant challenges. Recent studies have explored image-driven approaches using computer vision models to address these challenges, often employing lineplots as the visual representation of time series data. In this paper, we propose a novel approach that uses time-frequency spectrograms as the visual representation of time series data. We introduce the use of a vision transformer for multimodal learning, showcasing the advantages of our approach across diverse datasets from different domains. To evaluate its effectiveness, we compare our method against statistical baselines (EMA and ARIMA), a state-of-the-art deep learning-based approach (DeepAR), other visual representations of time series data (lineplot images), and an ablation study on using only the time series as input. Our experiments demonstrate the benefits of utilizing spectrograms as a visual representation for time series data, along with the advantages of employing a vision transformer for simultaneous learning in both the time and frequency domains.
REFRESH: Responsible and Efficient Feature Reselection Guided by SHAP Values
Mar 13, 2024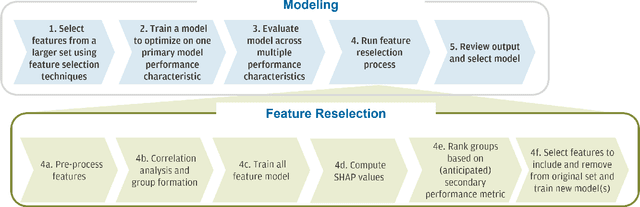


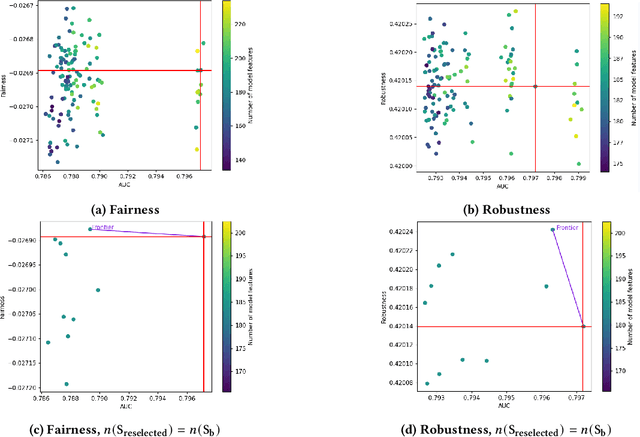
Feature selection is a crucial step in building machine learning models. This process is often achieved with accuracy as an objective, and can be cumbersome and computationally expensive for large-scale datasets. Several additional model performance characteristics such as fairness and robustness are of importance for model development. As regulations are driving the need for more trustworthy models, deployed models need to be corrected for model characteristics associated with responsible artificial intelligence. When feature selection is done with respect to one model performance characteristic (eg. accuracy), feature selection with secondary model performance characteristics (eg. fairness and robustness) as objectives would require going through the computationally expensive selection process from scratch. In this paper, we introduce the problem of feature \emph{reselection}, so that features can be selected with respect to secondary model performance characteristics efficiently even after a feature selection process has been done with respect to a primary objective. To address this problem, we propose REFRESH, a method to reselect features so that additional constraints that are desirable towards model performance can be achieved without having to train several new models. REFRESH's underlying algorithm is a novel technique using SHAP values and correlation analysis that can approximate for the predictions of a model without having to train these models. Empirical evaluations on three datasets, including a large-scale loan defaulting dataset show that REFRESH can help find alternate models with better model characteristics efficiently. We also discuss the need for reselection and REFRESH based on regulation desiderata.
On Computing Plans with Uniform Action Costs
Feb 15, 2024In many real-world planning applications, agents might be interested in finding plans whose actions have costs that are as uniform as possible. Such plans provide agents with a sense of stability and predictability, which are key features when humans are the agents executing plans suggested by planning tools. This paper adapts three uniformity metrics to automated planning, and introduce planning-based compilations that allow to lexicographically optimize sum of action costs and action costs uniformity. Experimental results both in well-known and novel planning benchmarks show that the reformulated tasks can be effectively solved in practice to generate uniform plans.
Synthetic Data Applications in Finance
Dec 29, 2023Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Fair Wasserstein Coresets
Nov 09, 2023Recent technological advancements have given rise to the ability of collecting vast amounts of data, that often exceed the capacity of commonly used machine learning algorithms. Approaches such as coresets and synthetic data distillation have emerged as frameworks to generate a smaller, yet representative, set of samples for downstream training. As machine learning is increasingly applied to decision-making processes, it becomes imperative for modelers to consider and address biases in the data concerning subgroups defined by factors like race, gender, or other sensitive attributes. Current approaches focus on creating fair synthetic representative samples by optimizing local properties relative to the original samples. These methods, however, are not guaranteed to positively affect the performance or fairness of downstream learning processes. In this work, we present Fair Wasserstein Coresets (FWC), a novel coreset approach which generates fair synthetic representative samples along with sample-level weights to be used in downstream learning tasks. FWC aims to minimize the Wasserstein distance between the original datasets and the weighted synthetic samples while enforcing (an empirical version of) demographic parity, a prominent criterion for algorithmic fairness, via a linear constraint. We show that FWC can be thought of as a constrained version of Lloyd's algorithm for k-medians or k-means clustering. Our experiments, conducted on both synthetic and real datasets, demonstrate the scalability of our approach and highlight the competitive performance of FWC compared to existing fair clustering approaches, even when attempting to enhance the fairness of the latter through fair pre-processing techniques.
FairWASP: Fast and Optimal Fair Wasserstein Pre-processing
Oct 31, 2023Recent years have seen a surge of machine learning approaches aimed at reducing disparities in model outputs across different subgroups. In many settings, training data may be used in multiple downstream applications by different users, which means it may be most effective to intervene on the training data itself. In this work, we present FairWASP, a novel pre-processing approach designed to reduce disparities in classification datasets without modifying the original data. FairWASP returns sample-level weights such that the reweighted dataset minimizes the Wasserstein distance to the original dataset while satisfying (an empirical version of) demographic parity, a popular fairness criterion. We show theoretically that integer weights are optimal, which means our method can be equivalently understood as duplicating or eliminating samples. FairWASP can therefore be used to construct datasets which can be fed into any classification method, not just methods which accept sample weights. Our work is based on reformulating the pre-processing task as a large-scale mixed-integer program (MIP), for which we propose a highly efficient algorithm based on the cutting plane method. Experiments on synthetic datasets demonstrate that our proposed optimization algorithm significantly outperforms state-of-the-art commercial solvers in solving both the MIP and its linear program relaxation. Further experiments highlight the competitive performance of FairWASP in reducing disparities while preserving accuracy in downstream classification settings.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023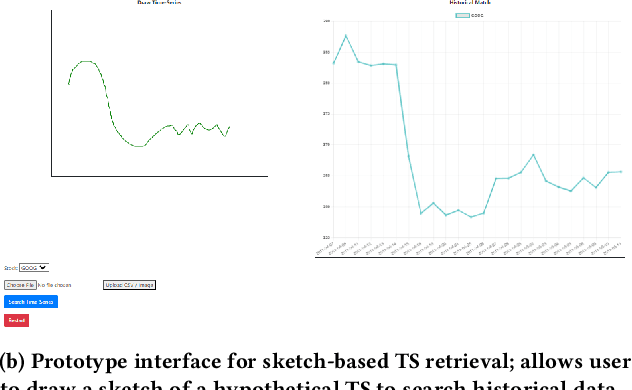
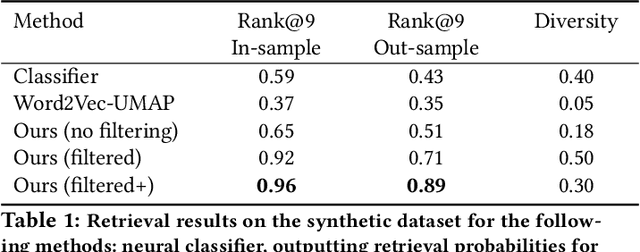
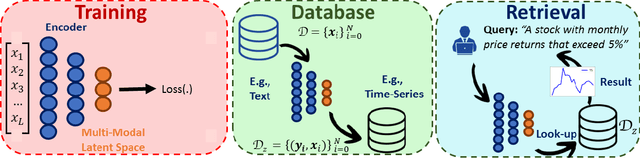
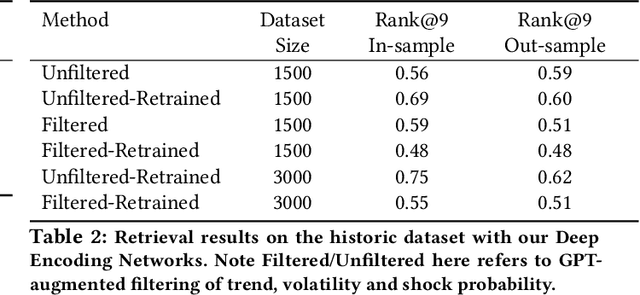
Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.