 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManuele Leonelli
AI and the creative realm: A short review of current and future applications
Jun 01, 2023
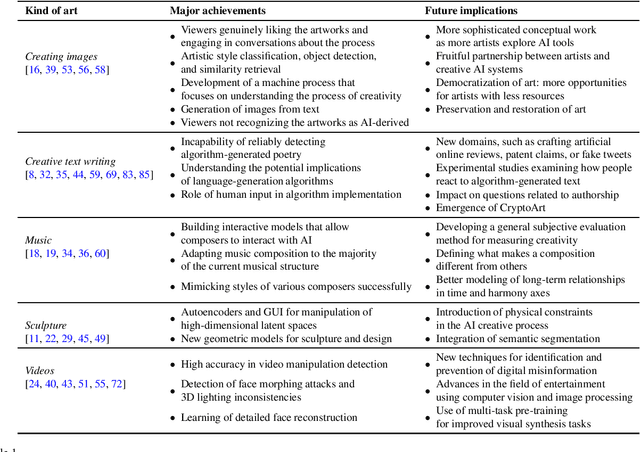
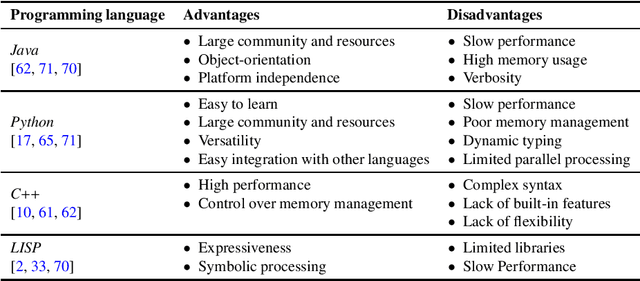
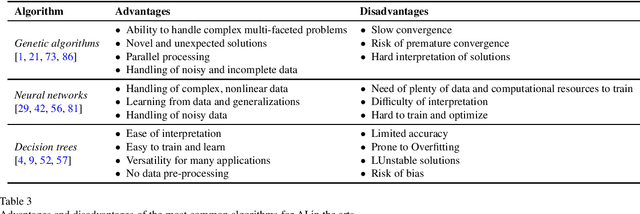
This study explores the concept of creativity and artificial intelligence (AI) and their recent integration. While AI has traditionally been perceived as incapable of generating new ideas or creating art, the development of more sophisticated AI models and the proliferation of human-computer interaction tools have opened up new possibilities for AI in artistic creation. This study investigates the various applications of AI in a creative context, differentiating between the type of art, language, and algorithms used. It also considers the philosophical implications of AI and creativity, questioning whether consciousness can be researched in machines and AI's potential interests and decision-making capabilities. Overall, we aim to stimulate a reflection on AI's use and ethical implications in creative contexts.
The YODO algorithm: An efficient computational framework for sensitivity analysis in Bayesian networks
Feb 01, 2023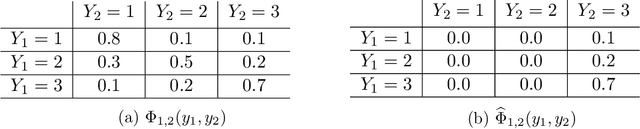
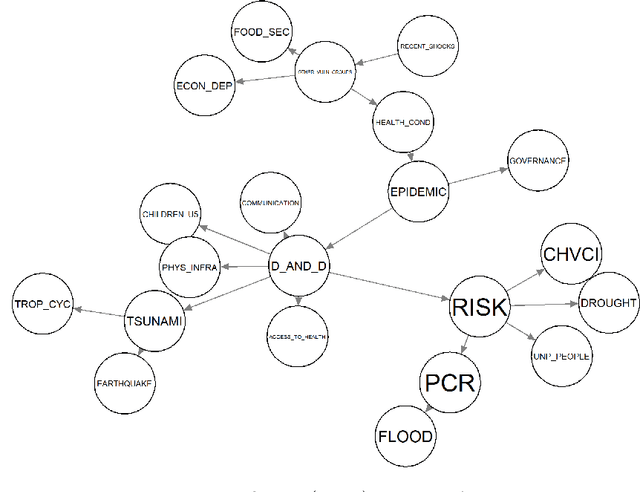
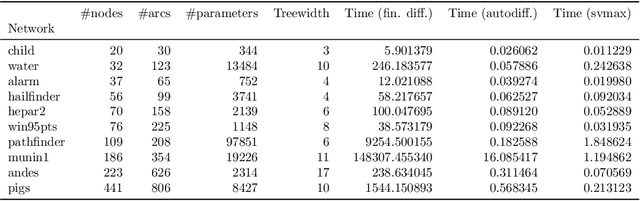
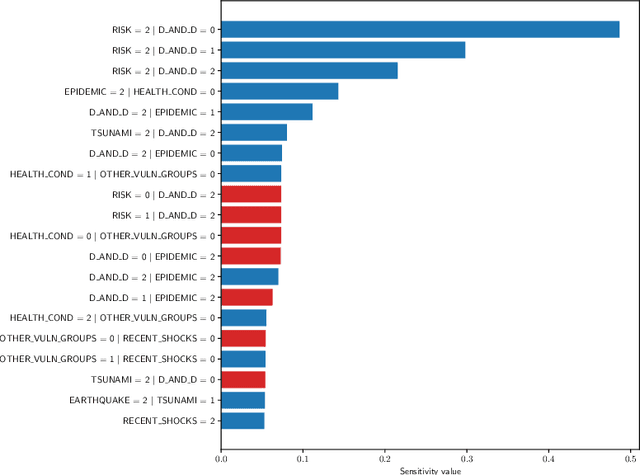
Sensitivity analysis measures the influence of a Bayesian network's parameters on a quantity of interest defined by the network, such as the probability of a variable taking a specific value. Various sensitivity measures have been defined to quantify such influence, most commonly some function of the quantity of interest's partial derivative with respect to the network's conditional probabilities. However, computing these measures in large networks with thousands of parameters can become computationally very expensive. We propose an algorithm combining automatic differentiation and exact inference to efficiently calculate the sensitivity measures in a single pass. It first marginalizes the whole network once, using e.g. variable elimination, and then backpropagates this operation to obtain the gradient with respect to all input parameters. Our method can be used for one-way and multi-way sensitivity analysis and the derivation of admissible regions. Simulation studies highlight the efficiency of our algorithm by scaling it to massive networks with up to 100'000 parameters and investigate the feasibility of generic multi-way analyses. Our routines are also showcased over two medium-sized Bayesian networks: the first modeling the country-risks of a humanitarian crisis, the second studying the relationship between the use of technology and the psychological effects of forced social isolation during the COVID-19 pandemic. An implementation of the methods using the popular machine learning library PyTorch is freely available.
Learning and interpreting asymmetry-labeled DAGs: a case study on COVID-19 fear
Jan 02, 2023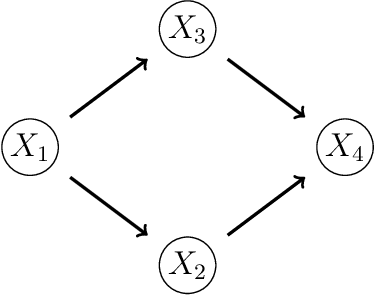
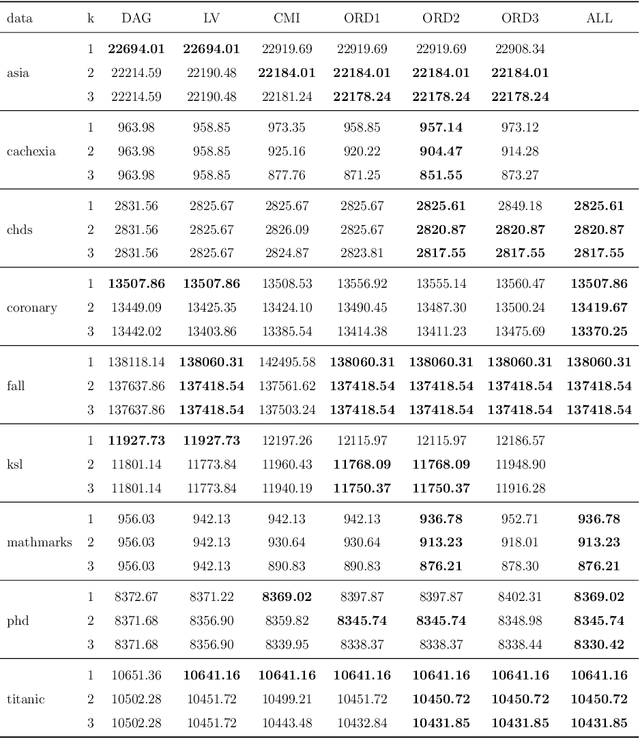
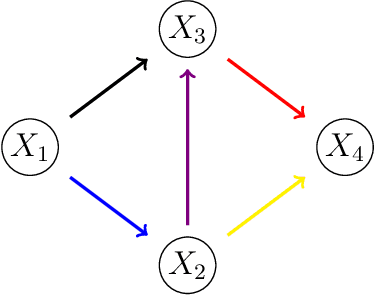
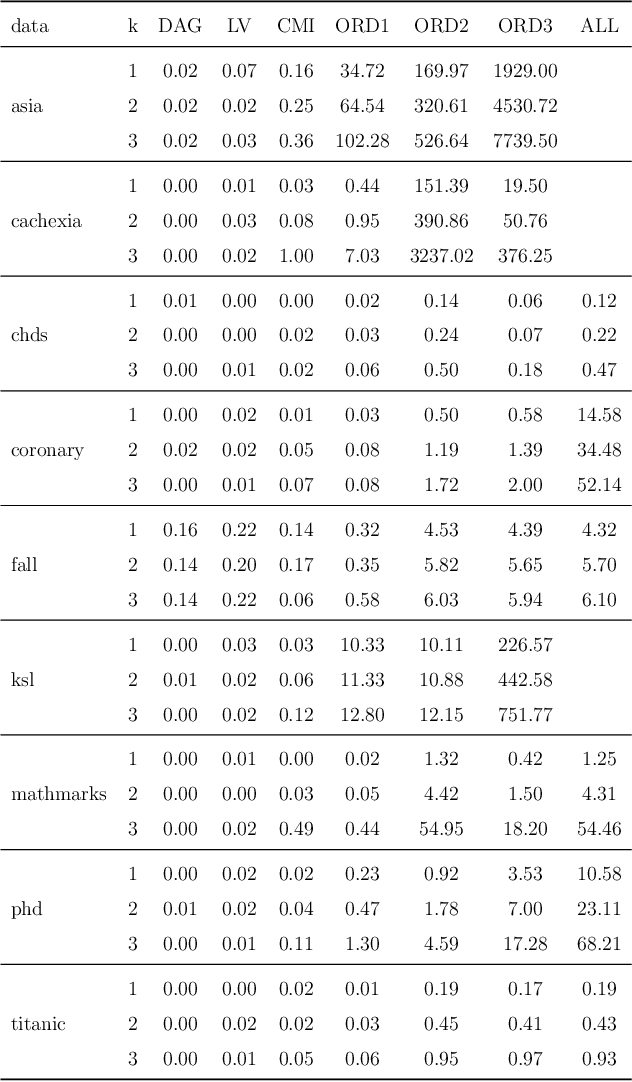
Bayesian networks are widely used to learn and reason about the dependence structure of discrete variables. However, they are only capable of formally encoding symmetric conditional independence, which in practice is often too strict to hold. Asymmetry-labeled DAGs have been recently proposed to both extend the class of Bayesian networks by relaxing the symmetric assumption of independence and denote the type of dependence existing between the variables of interest. Here, we introduce novel structural learning algorithms for this class of models which, whilst being efficient, allow for a straightforward interpretation of the underlying dependence structure. A comprehensive computational study highlights the efficiency of the algorithms. A real-world data application using data from the Fear of COVID-19 Scale collected in Italy showcases their use in practice.
You Only Derive Once (YODO): Automatic Differentiation for Efficient Sensitivity Analysis in Bayesian Networks
Jun 17, 2022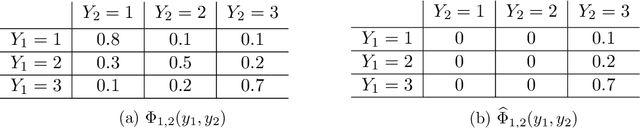
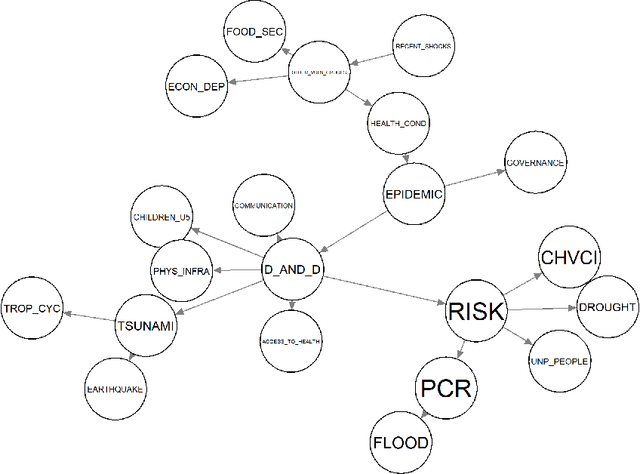
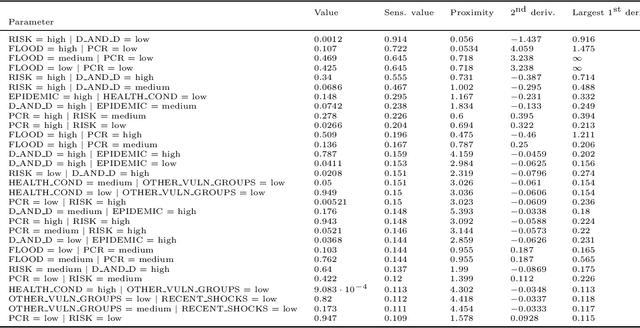
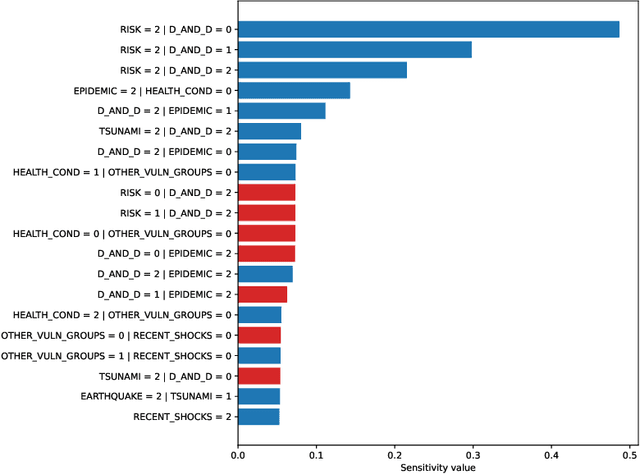
Sensitivity analysis measures the influence of a Bayesian network's parameters on a quantity of interest defined by the network, such as the probability of a variable taking a specific value. In particular, the so-called sensitivity value measures the quantity of interest's partial derivative with respect to the network's conditional probabilities. However, finding such values in large networks with thousands of parameters can become computationally very expensive. We propose to use automatic differentiation combined with exact inference to obtain all sensitivity values in a single pass. Our method first marginalizes the whole network once using e.g. variable elimination and then backpropagates this operation to obtain the gradient with respect to all input parameters. We demonstrate our routines by ranking all parameters by importance on a Bayesian network modeling humanitarian crises and disasters, and then show the method's efficiency by scaling it to huge networks with up to 100'000 parameters. An implementation of the methods using the popular machine learning library PyTorch is freely available.
Highly Efficient Structural Learning of Sparse Staged Trees
Jun 14, 2022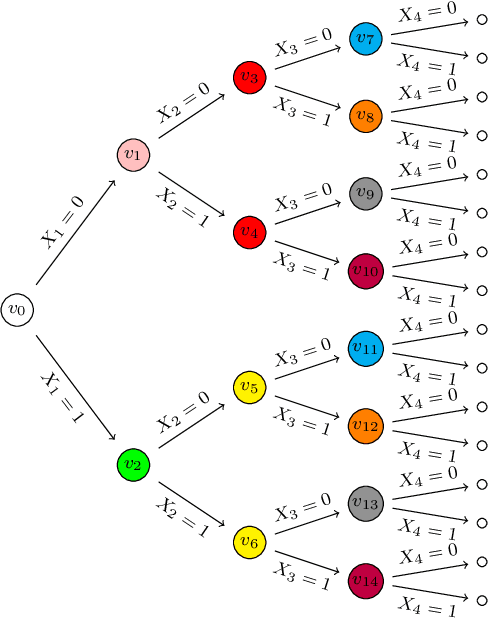
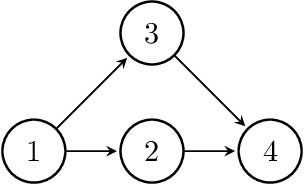
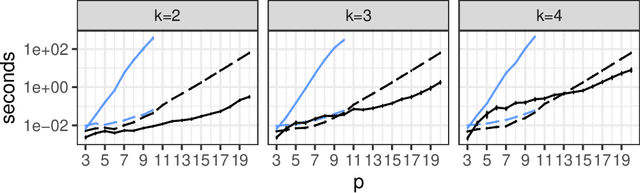
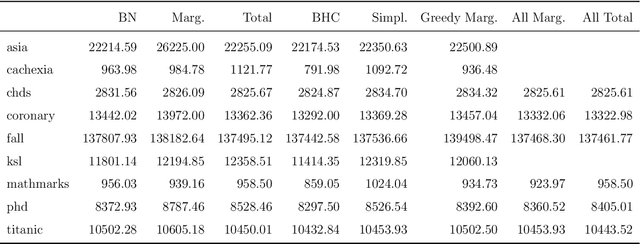
Several structural learning algorithms for staged tree models, an asymmetric extension of Bayesian networks, have been defined. However, they do not scale efficiently as the number of variables considered increases. Here we introduce the first scalable structural learning algorithm for staged trees, which searches over a space of models where only a small number of dependencies can be imposed. A simulation study as well as a real-world application illustrate our routines and the practical use of such data-learned staged trees.
Structural Learning of Simple Staged Trees
Mar 08, 2022
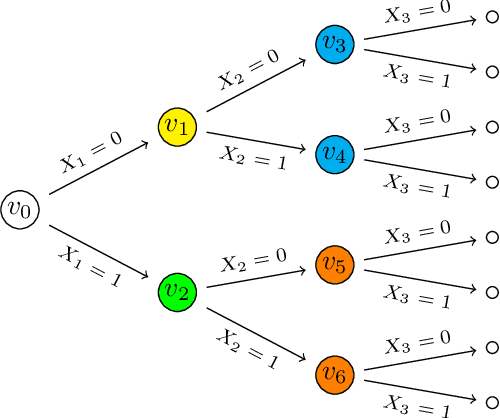
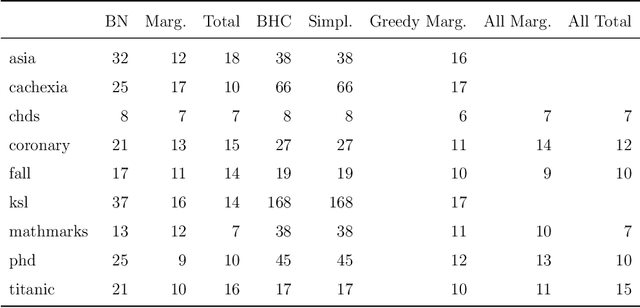
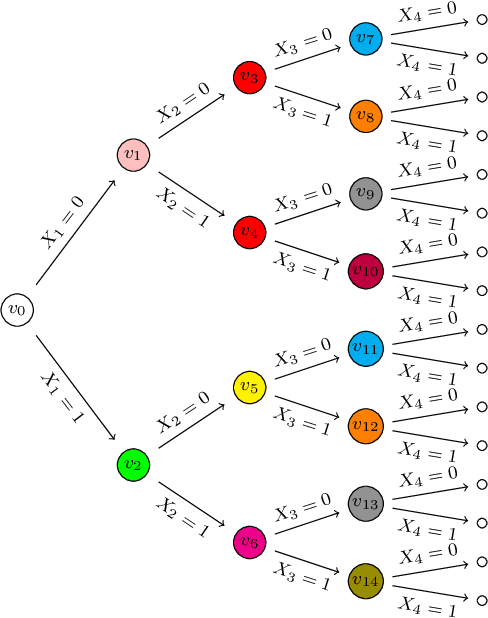
Bayesian networks faithfully represent the symmetric conditional independences existing between the components of a random vector. Staged trees are an extension of Bayesian networks for categorical random vectors whose graph represents non-symmetric conditional independences via vertex coloring. However, since they are based on a tree representation of the sample space, the underlying graph becomes cluttered and difficult to visualize as the number of variables increases. Here we introduce the first structural learning algorithms for the class of simple staged trees, entertaining a compact coalescence of the underlying tree from which non-symmetric independences can be easily read. We show that data-learned simple staged trees often outperform Bayesian networks in model fit and illustrate how the coalesced graph is used to identify non-symmetric conditional independences.
Global sensitivity analysis in probabilistic graphical models
Oct 07, 2021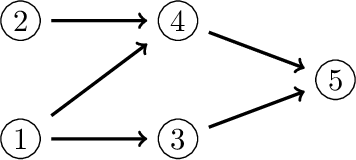


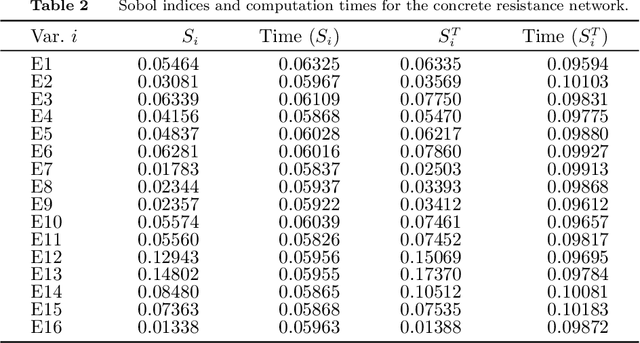
We show how to apply Sobol's method of global sensitivity analysis to measure the influence exerted by a set of nodes' evidence on a quantity of interest expressed by a Bayesian network. Our method exploits the network structure so as to transform the problem of Sobol index estimation into that of marginalization inference. This way, we can efficiently compute indices for networks where brute-force or Monte Carlo based estimators for variance-based sensitivity analysis would require millions of costly samples. Moreover, our method gives exact results when exact inference is used, and also supports the case of correlated inputs. The proposed algorithm is inspired by the field of tensor networks, and generalizes earlier tensor sensitivity techniques from the acyclic to the cyclic case. We demonstrate the method on three medium to large Bayesian networks that cover the areas of project risk management and reliability engineering.
Staged trees and asymmetry-labeled DAGs
Aug 04, 2021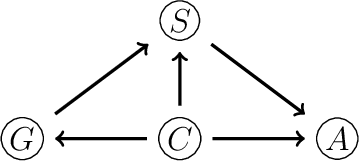
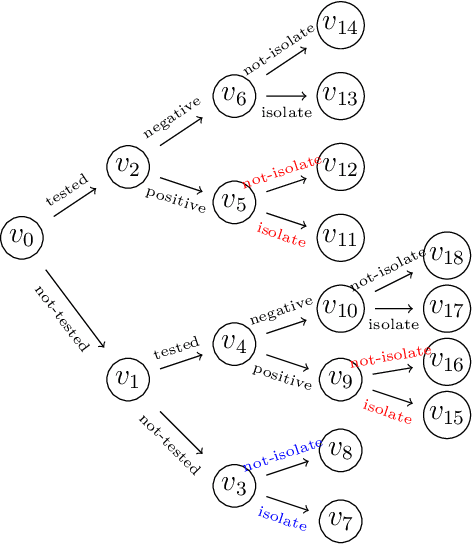
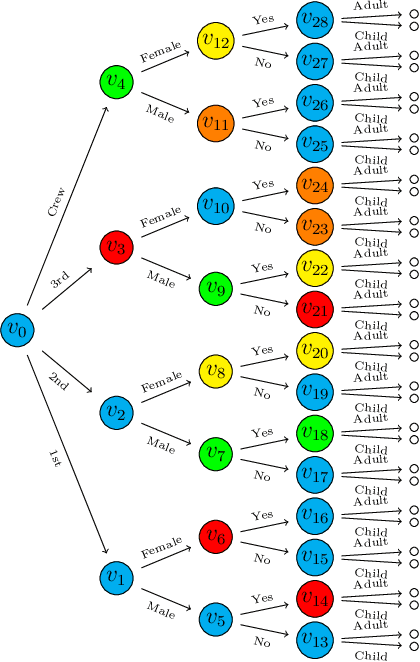
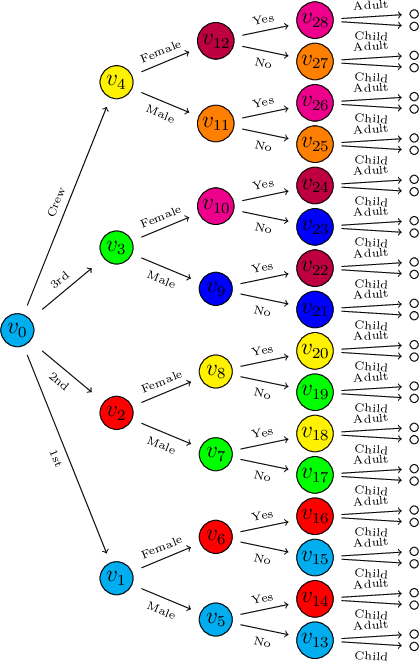
Bayesian networks are a widely-used class of probabilistic graphical models capable of representing symmetric conditional independence between variables of interest using the topology of the underlying graph. They can be seen as a special case of the much more general class of models called staged trees, which can represent any type of non-symmetric conditional independence. Here we formalize the relationship between these two models and introduce a minimal Bayesian network representation of the staged tree, which can be used to read conditional independences in an intuitive way. Furthermore, we define a new labeled graph, termed asymmetry-labeled directed acyclic graph, whose edges are labeled to denote the type of dependence existing between any two random variables. Various datasets are used to illustrate the methodology, highlighting the need to construct models which more flexibly encode and represent non-symmetric structures.
Sensitivity and robustness analysis in Bayesian networks with the bnmonitor R package
Jul 25, 2021
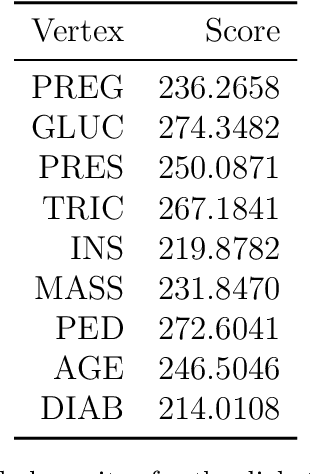
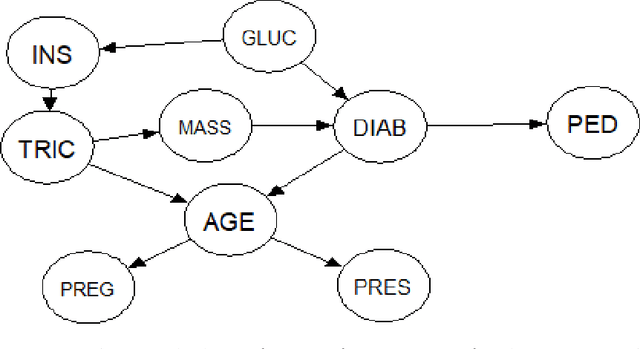

Bayesian networks are a class of models that are widely used for risk assessment of complex operational systems. There are now multiple approaches, as well as implemented software, that guide their construction via data learning or expert elicitation. However, a constructed Bayesian network needs to be validated before it can be used for practical risk assessment. Here, we illustrate the usage of the bnmonitor R package: the first comprehensive software for the validation of a Bayesian network. An applied data analysis using bnmonitor is carried out over a medical dataset to illustrate the use of its wide array of functions.
Context-Specific Causal Discovery for Categorical Data Using Staged Trees
Jun 08, 2021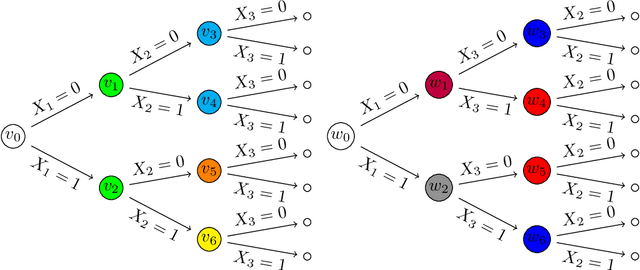
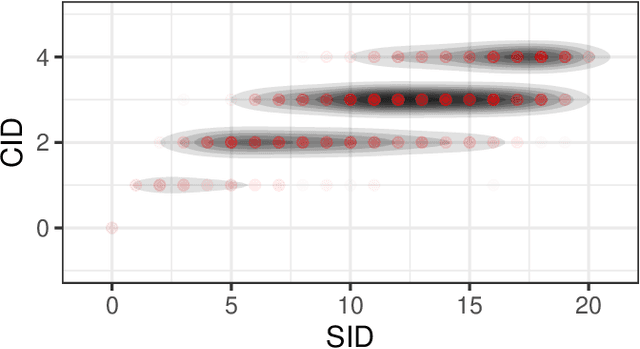
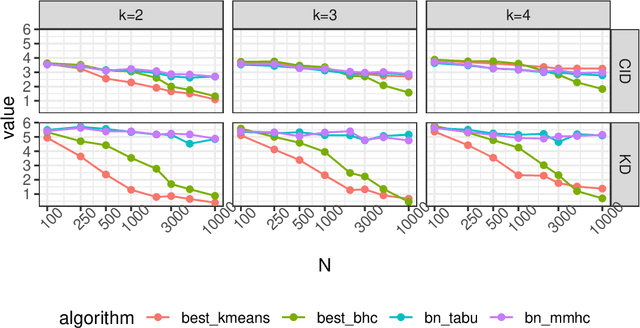
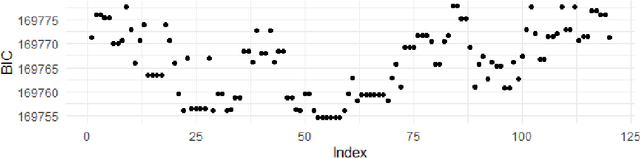
Causal discovery algorithms aims at untangling complex causal relationships using observational data only. Here, we introduce new causal discovery algorithms based on staged tree models, which can represent complex and non-symmetric causal effects. To demonstrate the efficacy of our algorithms, we introduce a new distance, inspired by the widely used structural interventional distance, to quantify the closeness between two staged trees in terms of their corresponding causal inference statements. A simulation study highlights the efficacy of staged trees in uncovering complex, asymmetric causal relationship from data and a real-world data application illustrates their use in a practical causal analysis.